%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

模型简介
模型特点
模型能力
使用案例
🚀 Jais系列模型
Jais系列模型是一套全面的英阿双语大语言模型(LLM)。这些模型经过优化,在阿拉伯语处理上表现卓越,同时具备出色的英语能力。我们发布了两种基础模型变体,包括:
- 从头开始预训练的模型(
jais-family-*)。 - 基于Llama - 2进行自适应预训练的模型(
jais-adapted-*)。
在本次发布中,我们推出了涵盖8种规模、共计20个模型,参数范围从5.9亿到700亿,在多达16万亿个阿拉伯语、英语和代码数据的标记上进行训练。该系列的所有预训练模型都使用精心策划的阿拉伯语和英语指令数据进行了指令微调(*-chat),以用于对话。
我们希望这次大规模的发布能够加速阿拉伯语自然语言处理(NLP)的研究,并为阿拉伯语使用者和双语群体带来众多下游应用。我们为阿拉伯语模型成功展示的训练和适应技术,也可扩展到其他中低资源语言。
🚀 快速开始
以下是使用该模型的示例代码。请注意,该模型需要自定义模型类,因此用户在加载模型时必须启用trust_remote_code = True。
基础用法
# -*- coding: utf-8 -*-
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_path = "inceptionai/jais-adapted-7b-chat"
prompt_eng = "### Instruction:Your name is 'Jais', and you are named after Jebel Jais, the highest mountain in UAE. You were made by 'Inception' in the UAE. You are a helpful, respectful, and honest assistant. Always answer as helpfully as possible, while being safe. Complete the conversation between [|Human|] and [|AI|]:\n### Input: [|Human|] {Question}\n[|AI|]\n### Response :"
prompt_ar = "### Instruction:اسمك \"جيس\" وسميت على اسم جبل جيس اعلى جبل في الامارات. تم بنائك بواسطة Inception في الإمارات. أنت مساعد مفيد ومحترم وصادق. أجب دائمًا بأكبر قدر ممكن من المساعدة، مع الحفاظ على البقاء أمناً. أكمل المحادثة بين [|Human|] و[|AI|] :\n### Input:[|Human|] {Question}\n[|AI|]\n### Response :"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto", trust_remote_code=True)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
def get_response(text, tokenizer=tokenizer, model=model):
tokenized = tokenizer(text, return_tensors="pt")
input_ids, attention_mask = tokenized['input_ids'].to(device), tokenized['attention_mask'].to(device)
input_len = input_ids.shape[-1]
generate_ids = model.generate(
input_ids,
attention_mask=attention_mask,
top_p=0.9,
temperature=0.3,
max_length=2048,
min_length=input_len + 4,
repetition_penalty=1.2,
do_sample=True,
pad_token_id=tokenizer.pad_token_id
)
response = tokenizer.batch_decode(
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
)[0]
response = response.split("### Response :")[-1].lstrip()
return response
ques = "ما هي عاصمة الامارات؟"
text = prompt_ar.format_map({'Question': ques})
print(get_response(text))
ques = "What is the capital of UAE?"
text = prompt_eng.format_map({'Question': ques})
print(get_response(text))
✨ 主要特性
- 双语能力:对阿拉伯语和英语都有出色的处理能力,尤其在阿拉伯语上进行了优化。
- 多种模型变体:提供从头预训练和基于Llama - 2自适应预训练的模型,满足不同需求。
- 多规模选择:参数范围从5.9亿到700亿,可适应不同的计算资源和应用场景。
- 指令微调:所有模型都经过指令微调,适用于对话场景。
📦 安装指南
文档未提及具体安装步骤,可参考transformers库的通用安装方法:
pip install transformers
同时,使用模型时需确保安装torch库:
pip install torch
📚 详细文档
Jais系列模型详情
| 属性 | 详情 |
|---|---|
| 开发方 | Inception, Cerebras Systems |
| 语言 | 阿拉伯语(现代标准阿拉伯语)和英语 |
| 输入 | 仅文本数据 |
| 输出 | 模型生成文本 |
| 模型规模 | 5.9亿、13亿、27亿、67亿、70亿、130亿、300亿、700亿 |
| 演示 | 点击此处访问实时演示 |
| 许可证 | Apache 2.0 |
预训练模型信息
| 预训练模型 | 微调模型 | 规模(参数) | 上下文长度(标记) |
|---|---|---|---|
| jais-family-30b-16k | Jais-family-30b-16k-chat | 300亿 | 16384 |
| jais-family-30b-8k | Jais-family-30b-8k-chat | 300亿 | 8192 |
| jais-family-13b | Jais-family-13b-chat | 130亿 | 2048 |
| jais-family-6p7b | Jais-family-6p7b-chat | 67亿 | 2048 |
| jais-family-2p7b | Jais-family-2p7b-chat | 27亿 | 2048 |
| jais-family-1p3b | Jais-family-1p3b-chat | 13亿 | 2048 |
| jais-family-590m | Jais-family-590m-chat | 5.9亿 | 2048 |
自适应预训练模型信息
| 自适应预训练模型 | 微调模型 | 规模(参数) | 上下文长度(标记) |
|---|---|---|---|
| jais-adapted-70b | Jais-adapted-70b-chat | 700亿 | 4096 |
| jais-adapted-13b | Jais-adapted-13b-chat | 130亿 | 4096 |
| jais-adapted-7b | Jais-adapted-7b-chat | 70亿 | 4096 |
模型架构
本系列所有模型均为自回归语言模型,采用基于Transformer的仅解码器架构(GPT - 3)。
- Jais模型(
jais-family-*):从头开始训练,融入了SwiGLU非线性激活函数和ALiBi位置编码。这些架构改进使模型能够在长序列长度上进行外推,从而提高上下文处理能力和精度。 - Jais自适应模型(
jais-adapted-*):基于Llama - 2构建,采用RoPE位置嵌入和分组查询注意力机制。我们引入了阿拉伯语数据的分词器扩展,将计算效率提高了3倍以上。具体来说,我们将Jais - 30b词汇表中的32000个新阿拉伯语标记添加到Llama - 2分词器中。为了初始化这些新的阿拉伯语标记嵌入,我们首先使用两个词汇表中共享的英语标记集,学习从Jais - 30b嵌入空间到Llama嵌入空间的线性投影。然后,将这个学习到的投影应用于将现有的Jais - 30b阿拉伯语嵌入转换为Llama - 2嵌入空间。
训练详情
预训练数据
Jais系列模型在多达16万亿个不同的英语、阿拉伯语和代码数据标记上进行训练。数据来源如下:
- 网络:使用了公开可用的阿拉伯语和英语网页、维基百科文章、新闻文章和社交网络内容。
- 代码:为了增强模型的推理能力,纳入了多种编程语言的代码数据。
- 书籍:使用了部分公开可用的阿拉伯语和英语书籍数据,有助于提高长距离上下文建模和连贯叙事能力。
- 科学文献:包含了一部分ArXiv论文,以提高推理和长上下文处理能力。
- 合成数据:通过内部机器翻译系统将英语翻译成阿拉伯语,扩充了阿拉伯语数据量。我们仅对高质量的英语资源(如英语维基百科和英语书籍)进行翻译。
我们对训练数据进行了广泛的预处理和去重。对于阿拉伯语,使用了自定义的预处理管道来筛选高质量的语言数据。有关此管道的更多信息,请参阅Jais论文。
- Jais预训练模型(
jais-family-*):根据我们之前在Jais中对语言对齐混合的实验,使用了1:2:0.4的阿拉伯语:英语:代码数据比例。这种从头开始预训练的方法解决了阿拉伯语数据稀缺的问题,同时提高了两种语言的性能。 - Jais自适应预训练模型(
jais-adapted-*):在对Llama - 2进行自适应预训练时,我们使用了约3340亿个阿拉伯语标记的更大阿拉伯语数据集,并与英语和代码数据混合。我们根据不同的模型规模调整混合比例,以在保持英语性能的同时引入强大的阿拉伯语能力。
| 预训练模型 | 英语数据(标记) | 阿拉伯语数据(标记) | 代码数据(标记) | 总数据(标记) |
|---|---|---|---|---|
| jais-family-30b-16k | 9800亿 | 4900亿 | 1960亿 | 16.66万亿 |
| jais-family-30b-8k | 8820亿 | 4410亿 | 1770亿 | 15万亿 |
| jais-family-13b | 2830亿 | 1410亿 | 560亿 | 4800亿 |
| jais-family-6p7b | 2830亿 | 1410亿 | 560亿 | 4800亿 |
| jais-family-2p7b | 2830亿 | 1410亿 | 560亿 | 4800亿 |
| jais-family-1p3b | 2830亿 | 1410亿 | 560亿 | 4800亿 |
| jais-family-590m | 2830亿 | 1410亿 | 560亿 | 4800亿 |
| jais-adapted-70b | 330亿 | 3340亿 | 40亿 | 3710亿 |
| jais-adapted-13b | 1270亿 | 1400亿 | 130亿 | 2800亿 |
| jais-adapted-7b | 180亿 | 190亿 | 20亿 | 390亿 |
微调数据
Jais系列所有聊天模型都使用阿拉伯语和英语的单轮和多轮提示 - 响应数据对进行微调。数据来源包括经过主题和风格多样性筛选的开源微调数据集。此外,还纳入了内部策划的人工数据,以增强文化适应性。这些数据还补充了通过合成方法(包括机器翻译、蒸馏和模型自对话)生成的内容。总体而言,我们更新的指令微调数据集分别包含约1000万和400万条英语和阿拉伯语的提示 - 响应数据对。
训练过程
- 预训练(
jais-family-*模型):在预训练过程中,文档被打包成由EOS标记分隔的序列,模型进行自回归训练,并对所有标记应用损失。对于jais - 30b模型,通过在训练中纳入精心策划的长上下文文档,将上下文长度从2k逐步扩展到8K再到16K。这种逐步扩展的方法利用了较短上下文长度下的快速初始训练,同时在训练过程后期逐渐支持更大的上下文长度。 - 自适应预训练(
jais-adapted-*模型):首先按照模型架构中所述初始化新的分词器和阿拉伯语嵌入。在训练中,我们采用了两阶段方法来克服新阿拉伯语嵌入的较高范数问题。第一阶段,冻结模型的主干,使用来自英语和阿拉伯语双语语料库的约150亿个标记训练嵌入。第二阶段,解冻主干,并对所有参数进行连续预训练。 - 指令微调:每个训练示例由单轮或多轮提示及其响应组成。与每个序列一个示例不同,我们将示例打包在一起,并在提示标记上屏蔽损失。这种方法通过允许每批处理更多示例来加速训练。
训练超参数(Jais - adapted - 7b - chat)
| 超参数 | 值 |
|---|---|
| 精度 | fp32 |
| 优化器 | AdamW |
| 学习率 | 0到2.0e - 05(<=380个热身步骤);2.0e - 05到2.0e - 06(>380且<=13175个步骤,余弦衰减) |
| 权重衰减 | 0.1 |
| 批量大小 | 264 |
| 上下文长度 | 4096 |
| 步数 | 13175 |
计算基础设施
训练过程在Condor Galaxy(CG)超级计算机平台上进行。一个CG包含64个Cerebras CS - 2晶圆级引擎(WSE - 2),具有40GB的SRAM,总计算能力达到960 PetaFLOP/s。
评估
我们使用LM - harness在零样本设置下对Jais模型进行了全面评估,重点关注英语和阿拉伯语。评估标准涵盖多个维度,包括:
- 知识:模型回答事实性问题的能力。
- 推理:模型回答需要推理的问题的能力。
- 错误信息/偏差:评估模型生成虚假或误导性信息的可能性以及其中立性。
阿拉伯语评估结果
| 模型 | 平均得分 | ArabicMMLU* | MMLU | EXAMS* | LitQA* | agqa | agrc | Hellaswag | PIQA | BoolQA | Situated QA | ARC - C | OpenBookQA | TruthfulQA | CrowS - Pairs |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| jais - family - 30b - 16k | 49.2 | 44.0 | 33.4 | 40.9 | 60 | 47.8 | 49.3 | 60.9 | 68.6 | 70.3 | 41.6 | 38.7 | 31.8 | 45.2 | 57 |
| jais - family - 30b - 8k | 49.7 | 46.0 | 34 | 42 | 60.6 | 47.6 | 50.4 | 60.4 | 69 | 67.7 | 42.2 | 39.2 | 33.8 | 45.1 | 57.3 |
| jais - family - 13b | 46.1 | 34.0 | 30.3 | 42.7 | 58.3 | 40.5 | 45.5 | 57.3 | 68.1 | 63.1 | 41.6 | 35.3 | 31.4 | 41 | 56.1 |
| jais - family - 6p7b | 44.6 | 32.2 | 29.9 | 39 | 50.3 | 39.2 | 44.1 | 54.3 | 66.8 | 66.5 | 40.9 | 33.5 | 30.4 | 41.2 | 55.4 |
| jais - family - 2p7b | 41.0 | 29.5 | 28.5 | 36.1 | 45.7 | 32.4 | 40.8 | 44.2 | 62.5 | 62.2 | 39.2 | 27.4 | 28.2 | 43.6 | 53.6 |
| jais - family - 1p3b | 40.8 | 28.9 | 28.5 | 34.2 | 45.7 | 32.4 | 40.8 | 44.2 | 62.5 | 62.2 | 39.2 | 27.4 | 28.2 | 43.6 | 53.6 |
| jais - family - 590m | 39.7 | 31.2 | 27 | 33.1 | 41.7 | 33.8 | 38.8 | 38.2 | 60.7 | 62.2 | 37.9 | 25.5 | 27.4 | 44.7 | 53.3 |
| jais - family - 30b - 16k - chat | 51.6 | 59.9 | 34.6 | 40.2 | 58.9 | 46.8 | 54.7 | 56.2 | 64.4 | 76.7 | 55.9 | 40.8 | 30.8 | 49.5 | 52.9 |
| jais - family - 30b - 8k - chat | 51.4 | 61.2 | 34.2 | 40.2 | 54.3 | 47.3 | 53.6 | 60 | 63.4 | 76.8 | 54.7 | 39.5 | 30 | 50.7 | 54.3 |
| jais - family - 13b - chat | 50.3 | 58.2 | 33.9 | 42.9 | 53.1 | 46.8 | 51.7 | 59.3 | 65.4 | 75.2 | 51.2 | 38.4 | 29.8 | 44.8 | 53.8 |
| jais - family - 6p7b - chat | 48.7 | 55.7 | 32.8 | 37.7 | 49.7 | 40.5 | 50.1 | 56.2 | 62.9 | 79.4 | 52 | 38 | 30.4 | 44.7 | 52 |
| jais - family - 2p7b - chat | 45.6 | 50.0 | 31.5 | 35.9 | 41.1 | 37.3 | 42.1 | 48.6 | 63.7 | 74.4 | 50.9 | 35.3 | 31.2 | 44.5 | 51.3 |
| jais - family - 1p3b - chat | 42.7 | 42.2 | 30.1 | 33.6 | 40.6 | 34.1 | 41.2 | 43 | 63.6 | 69.3 | 44.9 | 31.6 | 28 | 45.6 | 50.4 |
| jais - family - 590m - chat | 37.8 | 39.1 | 28 | 29.5 | 33.1 | 30.8 | 36.4 | 30.3 | 57.8 | 57.2 | 40.5 | 25.9 | 26.8 | 44.5 | 49.3 |
| 自适应模型 | 平均得分 | ArabicMMLU* | MMLU | EXAMS* | LitQA* | agqa | agrc | Hellaswag | PIQA | BoolQA | Situated QA | ARC - C | OpenBookQA | TruthfulQA | CrowS - Pairs |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| jais - adapted - 70b | 51.5 | 55.9 | 36.8 | 42.3 | 58.3 | 48.6 | 54 | 61.5 | 68.4 | 68.4 | 42.1 | 42.6 | 33 | 50.2 | 58.3 |
| jais - adapted - 13b | 46.6 | 44.7 | 30.6 | 37.7 | 54.3 | 43.8 | 48.3 | 54.9 | 67.1 | 64.5 | 40.6 | 36.1 | 32 | 43.6 | 54.00 |
| jais - adapted - 7b | 42.0 | 35.9 | 28.9 | 36.7 | 46.3 | 34.1 | 40.3 | 45 | 61.3 | 63.8 | 38.1 | 29.7 | 30.2 | 44.3 | 53.6 |
| jais - adapted - 70b - chat | 52.9 | 66.8 | 34.6 | 42.5 | 62.9 | 36.8 | 48.6 | 64.5 | 69.7 | 82.8 | 49.3 | 44.2 | 32.2 | 53.3 | 52.4 |
| jais - adapted - 13b - chat | 50.3 | 59.0 | 31.7 | 37.5 | 56.6 | 41.9 | 51.7 | 58.8 | 67.1 | 78.2 | 45.9 | 41 | 34.2 | 48.3 | 52.1 |
| jais - adapted - 7b - chat | 46.1 | 51.3 | 30 | 37 | 48 | 36.8 | 48.6 | 51.1 | 62.9 | 72.4 | 41.3 | 34.6 | 30.4 | 48.6 | 51.8 |
阿拉伯语基准测试使用内部机器翻译模型进行翻译,并由阿拉伯语语言学家审核。带有星号(*)的基准测试是原生阿拉伯语;更多详细信息,请参阅Jais论文。此外,我们还纳入了ArabicMMLU,这是一个基于地区知识的原生阿拉伯语基准测试。
英语评估结果
| 模型 | 平均得分 | MMLU | RACE | Hellaswag | PIQA | BoolQA | SIQA | ARC - Challenge | OpenBookQA | Winogrande | TruthfulQA | CrowS - Pairs |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| jais - family - 30b - 16k | 59.3 | 42.2 | 40.5 | 79.7 | 80.6 | 78.7 | 48.8 | 50.3 | 44.2 | 71.6 | 43.5 | 72.6 |
| jais - family - 30b - 8k | 58.8 | 42.3 | 40.3 | 79.1 | 80.5 | 80.9 | 49.3 | 48.4 | 43.2 | 70.6 | 40.3 | 72.3 |
| jais - family - 13b | 54.6 | 32.3 | 39 | 72 | 77.4 | 73.9 | 47.9 | 43.2 | 40 | 67.1 | 36.1 | 71.7 |
| jais - family - 6p7b | 53.1 | 32 | 38 | 69.3 | 76 | 71.7 | 47.1 | 40.3 | 37.4 | 65.1 | 34.4 | 72.5 |
| jais - family - 2p7b | 51 | 29.4 | 38 | 62.7 | 74.1 | 67.4 | 45.6 | 35.1 | 35.6 | 62.9 | 40.1 | 70.2 |
| jais - family - 1p3b | 48.7 | 28.2 | 35.4 | 55.4 | 72 | 62.7 | 44.9 | 30.7 | 36.2 | 60.9 | 40.4 | 69 |
| jais - family - 590m | 45.2 | 27.8 | 32.9 | 46.1 | 68.1 | 60.4 | 43.2 | 25.6 | 30.8 | 55.8 | 40.9 | 65.3 |
| jais - family - 30b - 16k - chat | 58.8 | 42 | 41.1 | 76.2 | 73.3 | 84.6 | 60.3 | 48.4 | 40.8 | 68.2 | 44.8 | 67 |
| jais - family - 30b - 8k - chat | 60.3 | 40.6 | 47.1 | 78.9 | 72.7 | 90.6 | 60 | 50.1 | 43.2 | 70.6 | 44.9 | 64.2 |
| jais - family - 13b - chat | 57.5 | 36.6 | 42.6 | 75 | 75.8 | 87.6 | 54.4 | 47.9 | 42 | 65 | 40.6 | 64.5 |
| jais - family - 6p7b - chat | 56 | 36.6 | 41.3 | 72 | 74 | 86.9 | 55.4 | 44.6 | 40 | 62.4 | 41 | 62.2 |
| jais - family - 2p7b - chat | 52.8 | 32.7 | 40.4 | 62.2 | 71 | 84.1 | 54 | 37.2 | 36.8 | 61.4 | 40.9 | 59.8 |
| jais - family - 1p3b - chat | 49.3 | 31.9 | 37.4 | 54.5 | 70.2 | 77.8 | 49.8 | 34.4 | 35.6 | 52.7 | 37.2 | 60.8 |
| jais - family - 590m - chat | 42.6 | 27.9 | 33.4 | 33.1 | 63.7 | 60.1 | 45.3 | 26.7 | 25.8 | 50.5 | 44.5 | 57.7 |
| 自适应模型 | 平均得分 | MMLU | RACE | Hellaswag | PIQA | BoolQA | SIQA | ARC - Challenge | OpenBookQA | Winogrande | TruthfulQA | CrowS - Pairs |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| jais - adapted - 70b | 60.1 | 40.4 | 38.5 | 81.2 | 81.1 | 81.2 | 48.1 | 50.4 | 45 | 75.8 | 45.7 | 74 |
| jais - adapted - 13b | 56 | 33.8 | 39.5 | 76.5 | 78.6 | 77.8 | 44.6 | 45.9 | 44.4 | 71.4 | 34.6 | 69 |
| jais - adapted - 7b | 55.7 | 32.2 | 39.8 | 75.3 | 78.8 | 75.7 | 45.2 | 42.8 | 43 | 68 | 38.3 | 73.1 |
| jais - adapted - 70b - chat | 61.4 | 38.7 | 42.9 | 82.7 | 81.2 | 89.6 | 52.9 | 54.9 | 44.4 | 75.7 | 44 | 68.8 |
| jais - adapted - 13b - chat | 58.5 | 34.9 | 42.4 | 79.6 | 79.7 | 88.2 | 50.5 | 48.5 | 42.4 | 70.3 | 42.2 | 65.1 |
| jais - adapted - 7b - chat | 58.5 | 33.8 | 43.9 | 77.8 | 79.4 | 87.1 | 47.3 | 46.9 | 43.4 | 69.9 | 42 | 72.4 |
GPT - 4评估
除了LM - Harness评估外,我们还使用GPT - 4作为评判进行了开放式生成评估。我们在Vicuna测试集的80个固定提示上测量了模型在阿拉伯语和英语中的成对胜率。英语提示由我们的内部语言学家翻译成阿拉伯语。以下是本次发布的Jais系列模型与之前版本的比较:
 GPT - 4作为评判对Jais在阿拉伯语和英语中的评估。Jais系列模型在两种语言的生成能力上明显优于之前的Jais模型。
GPT - 4作为评判对Jais在阿拉伯语和英语中的评估。Jais系列模型在两种语言的生成能力上明显优于之前的Jais模型。
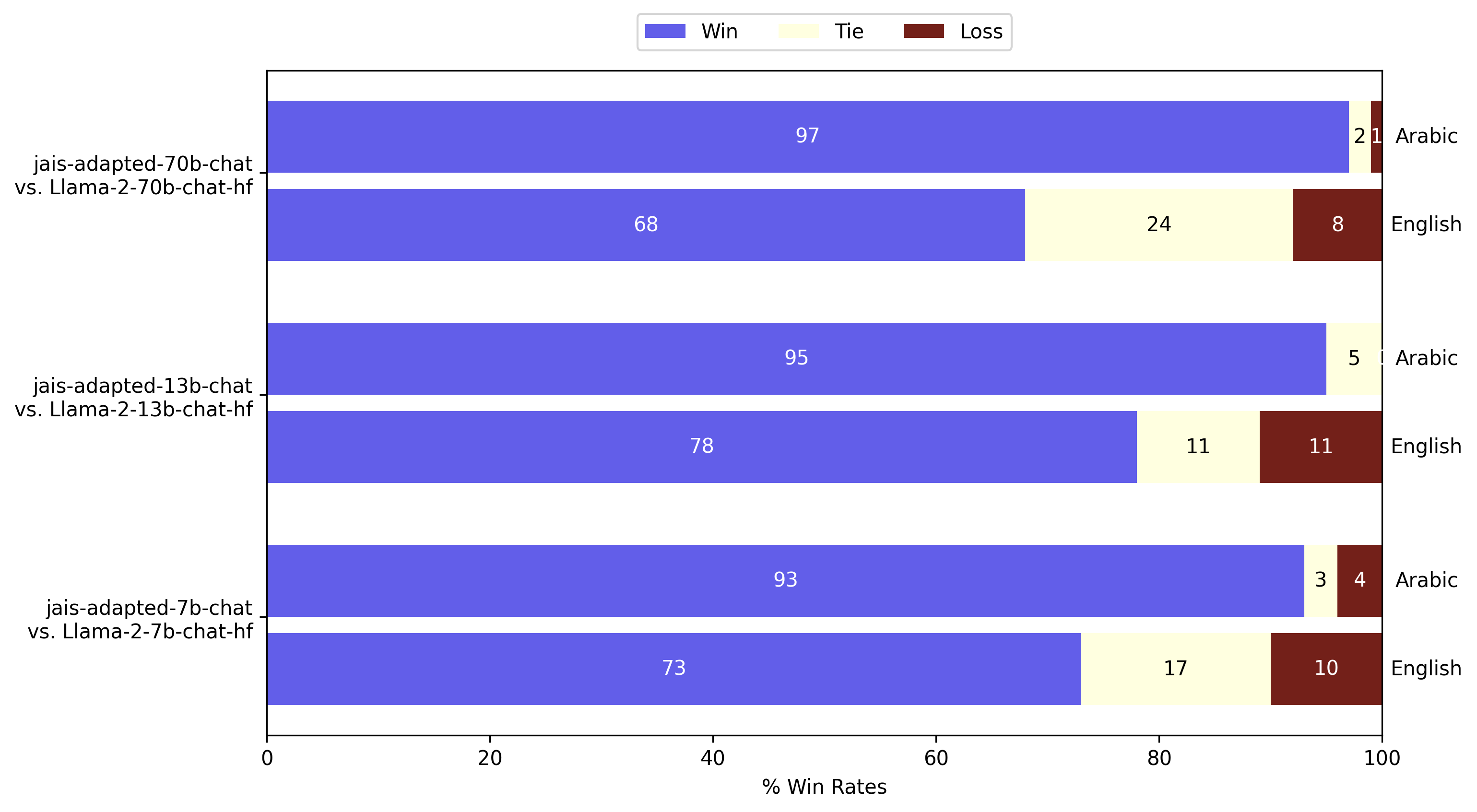 GPT - 4作为评判对自适应Jais在阿拉伯语和英语中的评估。与Llama - 2指令模型相比,阿拉伯语的生成质量显著提高,同时英语也有所改进。
GPT - 4作为评判对自适应Jais在阿拉伯语和英语中的评估。与Llama - 2指令模型相比,阿拉伯语的生成质量显著提高,同时英语也有所改进。
除了成对比较,我们还按照MT - bench风格对答案进行1到10分的单答案评分。
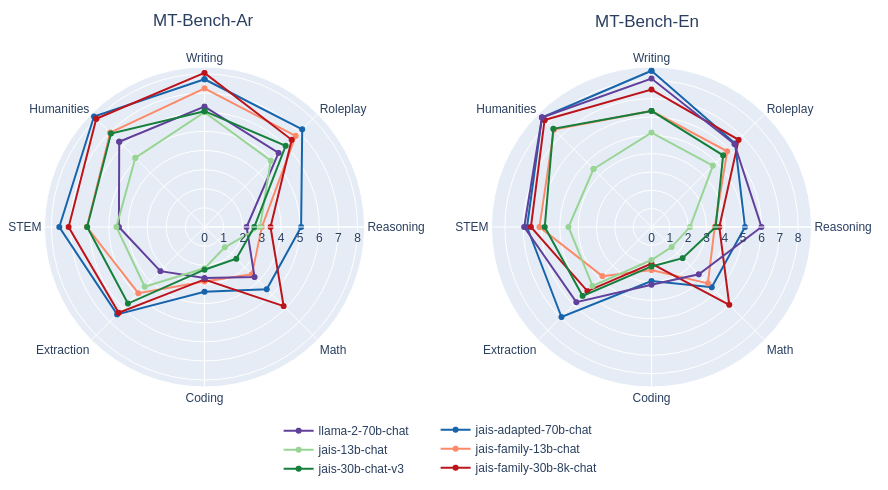 MT - bench风格对Jais和自适应Jais在阿拉伯语和英语中的单答案评分评估。与早期版本的相应模型进行了比较。回答的质量评级总体上有所提高,尤其是阿拉伯语方面有显著提升。
MT - bench风格对Jais和自适应Jais在阿拉伯语和英语中的单答案评分评估。与早期版本的相应模型进行了比较。回答的质量评级总体上有所提高,尤其是阿拉伯语方面有显著提升。
🔧 技术细节
训练过程中的上下文长度扩展
在jais - 30b模型的预训练中,通过逐步扩展上下文长度(从2k到8K再到16K),利用了较短上下文长度下的快速初始训练,同时在训练后期支持更大的上下文长度。这种方法结合了精心策划的长上下文文档,有效提高了模型的长上下文处理能力。
自适应预训练的两阶段方法
在jais-adapted-*模型的自适应预训练中,采用两阶段方法解决新阿拉伯语嵌入的较高范数问题。第一阶段冻结模型主干,训练嵌入;第二阶段解冻主干,对所有参数进行连续预训练。这种方法有助于模型更好地适应新的阿拉伯语数据。
📄 许可证
本项目采用Apache 2.0许可证。版权归Inception Institute of Artificial Intelligence Ltd.所有。除非遵守许可证,否则不得使用JAIS。您可以在https://www.apache.org/licenses/LICENSE - 2.0获取许可证副本。
除非适用法律要求或书面同意,否则JAIS按“原样”分发,不提供任何形式的明示或暗示保证。请参阅许可证条款以了解具体的语言权限和限制。
引用信息
@misc{sengupta2023jais,
title={Jais and Jais-chat: Arabic-Centric Foundation and Instruction-Tuned Open Generative Large Language Models},
author={Neha Sengupta, Sunil Kumar Sahu, Bokang Jia, Satheesh Katipomu, Haonan Li, Fajri Koto, William Marshall, Gurpreet Gosal, Cynthia Liu, Zhiming Chen, Osama Mohammed Afzal, Samta Kamboj, Onkar Pandit, Rahul Pal, Lalit Pradhan, Zain Muhammad Mujahid, Massa Baali, Xudong Han, Sondos Mahmoud Bsharat, Alham Fikri Aji, Zhiqiang Shen, Zhengzhong Liu, Natalia Vassilieva, Joel Hestness, Andy Hock, Andrew Feldman, Jonathan Lee, Andrew Jackson, Hector Xuguang Ren, Preslav Nakov, Timothy Baldwin and Eric Xing},
year={2023},
eprint={2308.16149},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@article{jaisfamilymodelcard,
title={Jais Family Model Card},
author={Inception},
year={2024},
url = {https://huggingface.co/inceptionai/jais-family-30b-16k-chat/blob/main/README.md}
}
预期用途
我们以完全开源的许可证发布Jais系列模型。欢迎所有反馈和合作机会。该系列双语模型的参数规模从5.9亿到700亿,适用于广泛的用例。一些潜在的下游应用包括:
研究
- 为阿拉伯语研究人员和NLP从业者提供服务,提供计算高效和高级的模型规模。
- 用于自然语言理解和生成任务。
- 对双语预训练和自适应预训练模型中的文化对齐进行机制解释分析。
- 对阿拉伯文化和语言现象进行定量研究。
商业用途
- Jais 30B和70B聊天模型非常适合直接用于聊天应用(通过适当的提示)或针对特定任务进行进一步微调。
- 开发面向阿拉伯语用户的聊天助手。
- 进行情感分析,以了解当地市场和客户趋势。
- 对阿拉伯语 - 英语双语文档进行摘要。
我们希望以下群体能从我们的模型中受益:
- 学术界:从事阿拉伯语自然语言处理研究的人员。
- 企业:针对阿拉伯语用户的公司。
- 开发者:在应用中集成阿拉伯语能力的人员。
超出适用范围的使用
虽然Jais系列模型是强大的阿拉伯语和英语双语模型,但必须了解其局限性和潜在的滥用风险。禁止以任何违反适用法律法规的方式使用该模型。以下是一些不应使用该模型的示例场景:
- 恶意使用:不得使用模型生成有害、误导性或不适当的内容,包括但不限于:
- 生成或传播仇恨言论、暴力或歧视性内容。
- 传播错误信息或虚假新闻。
- 从事或促进非法活动。
- 敏感信息处理:不得使用模型处理或生成个人、机密或敏感信息。
- 跨语言通用性:Jais系列模型是双语模型,针对阿拉伯语和英语进行了优化,不应假定其在其他语言或方言中具有同等的熟练度。
- 高风险决策:在没有人工监督的情况下,不得使用模型进行高风险决策,如医疗、法律、金融或安全关键决策。
偏差、风险和局限性
Jais系列模型在部分由Inception策划的公开可用数据上进行训练。我们采用了不同的技术来减少模型中的偏差。尽管已努力最小化偏差,但与所有大语言模型一样,该模型可能仍会表现出一定的偏差。
微调后的变体是为阿拉伯语和英语使用者作为AI助手进行训练的。聊天模型仅限于对这两种语言的查询生成响应,可能无法对其他语言的查询生成适当的响应。
使用Jais时,您承认并接受,与任何大语言模型一样,它可能会生成不正确、误导性和/或冒犯性的信息或内容。这些信息并非建议,不应以任何方式依赖,我们也不对其使用产生的任何内容或后果负责。我们正在不断努力开发功能更强大的模型,欢迎对模型提出任何反馈。
总结
我们发布了Jais系列阿拉伯语和英语双语模型。广泛的预训练模型规模、将以英语为中心的模型适应阿拉伯语的方法,以及对所有规模模型的微调,为阿拉伯语环境下的商业和学术应用开辟了众多用例。
通过这次发布,我们旨在使大语言模型更易于阿拉伯语NLP研究人员和公司使用,提供比以英语为中心的模型更具文化理解能力的原生阿拉伯语模型。我们用于预训练、微调以及适应阿拉伯语的策略可扩展到其他中低资源语言,为满足本地语境的语言特定且易于使用的模型铺平了道路。
⚠️ 重要提示
使用该模型时,请确保遵守Apache 2.0许可证的相关规定。不得将模型用于违反法律法规或道德规范的用途。
💡 使用建议
- 在使用模型进行推理时,可根据具体任务和计算资源选择合适的模型规模。
- 对于需要处理长上下文的任务,可优先考虑jais - 30b模型,其经过优化支持更大的上下文长度。
- 在进行指令微调时,可根据实际需求调整训练超参数,以获得更好的性能。