🚀 Stable Diffusion x2 潜在空间图像放大模型卡片
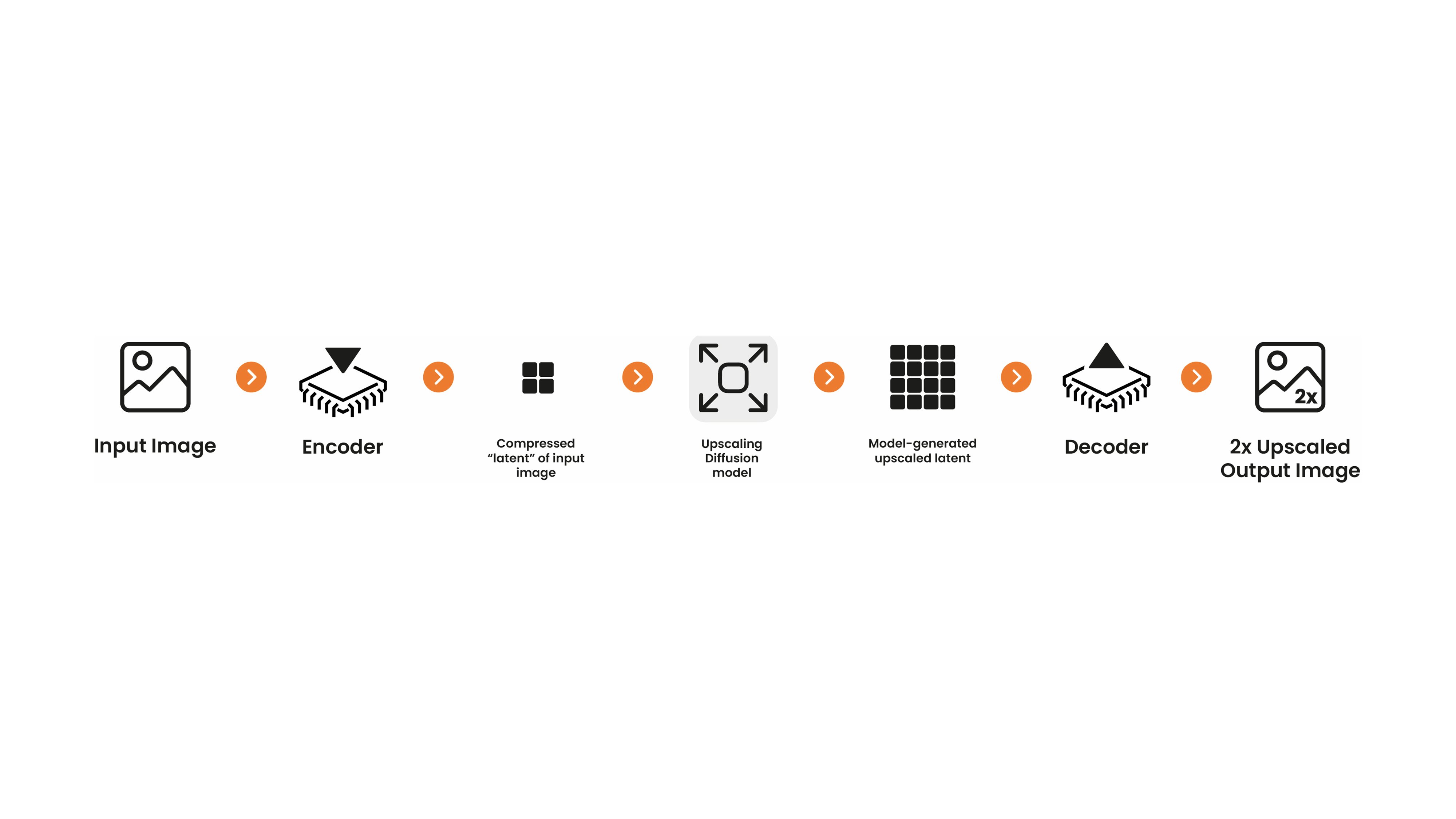
本模型卡片聚焦于由 Katherine Crowson 与 Stability AI 合作开发的基于潜在扩散的图像放大模型。该模型在 LAION - 2B 数据集的高分辨率子集上进行训练。它是一个在与 Stable Diffusion 模型相同的潜在空间中运行的扩散模型,可解码为全分辨率图像。要将其与 Stable Diffusion 结合使用,你可以将 Stable Diffusion 生成的潜在空间图像输入到放大模型中,然后再使用标准的变分自编码器(VAE)进行解码。或者,你也可以将任何图像编码到潜在空间,使用放大模型处理后再进行解码。
注意:
此放大模型专门为 Stable Diffusion 设计,因为它可以对 Stable Diffusion 的潜在去噪图像嵌入进行放大。这使得文本到图像 + 放大的流程非常快速,因为所有中间状态都可以保留在 GPU 上。更多信息,请参阅下面的示例。该模型适用于所有 Stable Diffusion 检查点。
| 原始输出图像 |
放大 2 倍后的输出图像 |
 |
 |
✨ 主要特性
- 专为 Stable Diffusion 设计:能够对 Stable Diffusion 的潜在去噪图像嵌入进行放大,实现快速的文本到图像 + 放大流程。
- 高分辨率训练:在 LAION - 2B 数据集的高分辨率子集上训练,可生成高质量放大图像。
- 适用于多检查点:支持所有 Stable Diffusion 检查点。
📦 安装指南
pip install git+https://github.com/huggingface/diffusers.git
pip install transformers accelerate scipy safetensors
💻 使用示例
基础用法
使用 ü§ó 的 Diffusers 库 在任何 StableDiffusionUpscalePipeline 检查点上运行潜在空间图像放大模型,将输出图像的分辨率提高 2 倍。
from diffusers import StableDiffusionLatentUpscalePipeline, StableDiffusionPipeline
import torch
pipeline = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
pipeline.to("cuda")
upscaler = StableDiffusionLatentUpscalePipeline.from_pretrained("stabilityai/sd-x2-latent-upscaler", torch_dtype=torch.float16)
upscaler.to("cuda")
prompt = "a photo of an astronaut high resolution, unreal engine, ultra realistic"
generator = torch.manual_seed(33)
low_res_latents = pipeline(prompt, generator=generator, output_type="latent").images
upscaled_image = upscaler(
prompt=prompt,
image=low_res_latents,
num_inference_steps=20,
guidance_scale=0,
generator=generator,
).images[0]
upscaled_image.save("astronaut_1024.png")
with torch.no_grad():
image = pipeline.decode_latents(low_res_latents)
image = pipeline.numpy_to_pil(image)[0]
image.save("astronaut_512.png")
结果:
512 分辨率宇航员图像

1024 分辨率宇航员图像

注意事项:
- 尽管
xformers 不是必需依赖项,但我们强烈建议你安装 xformers 以实现内存高效的注意力机制(更好的性能)。
- 如果你可用的 GPU 内存较低,请在将模型发送到
cuda 后添加 pipe.enable_attention_slicing() 以减少 VRAM 使用(代价是速度变慢)。
📚 详细文档
直接使用
该模型仅用于研究目的。可能的研究领域和任务包括:
- 安全部署有可能生成有害内容的模型。
- 探究和理解生成模型的局限性和偏差。
- 生成艺术作品并应用于设计和其他艺术过程。
- 在教育或创意工具中的应用。
- 生成模型的研究。
排除的使用情况如下所述。
误用、恶意使用和超出范围的使用
注意:本节内容最初来自 DALLE - MINI 模型卡片,曾用于 Stable Diffusion v1,同样适用于 Stable Diffusion v2。
该模型不应被用于故意创建或传播会对人们造成敌对或疏离环境的图像。这包括生成人们可预见会感到不安、痛苦或冒犯的图像,或传播历史或当前刻板印象的内容。
超出范围的使用
该模型并非用于生成对人物或事件的真实或准确呈现,因此使用该模型生成此类内容超出了其能力范围。
误用和恶意使用
使用该模型生成对个人残忍的内容属于对该模型的误用。这包括但不限于:
- 生成贬低、非人化或以其他方式伤害人们或其环境、文化、宗教等的表现形式。
- 故意推广或传播歧视性内容或有害刻板印象。
- 在未经个人同意的情况下冒充他人。
- 未经可能看到该内容的人的同意分享性内容。
- 传播错误和虚假信息。
- 呈现严重暴力和血腥的内容。
- 违反使用条款分享受版权保护或有使用许可的材料。
- 违反使用条款分享对受版权保护或有使用许可的材料进行修改后的内容。
局限性和偏差
局限性
- 模型无法实现完美的照片级真实感。
- 模型无法渲染清晰可读的文本。
- 模型在涉及组合性的更复杂任务上表现不佳,例如渲染与“一个红色立方体放在蓝色球体上”对应的图像。
- 面部和人物的生成可能不够理想。
- 该模型主要使用英文标题进行训练,在其他语言中的效果不佳。
- 模型的自动编码部分存在信息损失。
- 该模型在大规模数据集 LAION - 5B 的一个子集上训练,该数据集包含成人、暴力和性内容。为部分缓解这一问题,我们使用 LAION 的 NSFW 检测器对数据集进行了过滤(见训练部分)。
偏差
虽然图像生成模型的能力令人印象深刻,但它们也可能强化或加剧社会偏差。Stable Diffusion vw 主要在 LAION - 2B(en) 的子集上训练,该子集的图像仅限于英文描述。使用其他语言的社区和文化的文本和图像可能在训练中考虑不足。这影响了模型的整体输出,因为白人和西方文化通常被设定为默认。此外,该模型使用非英文提示生成内容的能力明显不如使用英文提示。Stable Diffusion v2 在一定程度上反映并加剧了偏差,因此无论输入或意图如何,都建议观众谨慎使用。
🔧 技术细节
📄 许可证
本模型使用 CreativeML Open RAIL++ - M 许可证。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 支持多种语言
Transformers 支持多种语言