%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型简介
模型特点
模型能力
使用案例
🚀 papuGaPT2 - 波兰语GPT2语言模型
papuGaPT2是一个基于GPT2架构的波兰语语言模型,旨在解决波兰语缺乏强大文本生成模型的问题,为波兰自然语言处理研究提供支持。
🚀 快速开始
GPT2于2019年发布,其文本生成能力令人瞩目。但直至近期,波兰语领域仍缺乏强大的文本生成模型,限制了波兰自然语言处理从业者的研究。本模型的发布有望推动相关研究。
✨ 主要特性
- 遵循标准GPT2架构和训练方法,采用因果语言建模(CLM)目标,训练模型预测单词序列中的下一个单词(标记)。
- 可直接用于文本生成,也能针对下游任务进行微调。
📦 安装指南
使用以下代码加载训练数据集:
from datasets import load_dataset
dataset = load_dataset('oscar', 'unshuffled_deduplicated_pl')
💻 使用示例
基础用法
from transformers import pipeline, set_seed
generator = pipeline('text-generation', model='flax-community/papuGaPT2')
set_seed(42)
generator('Największym polskim poetą był')
高级用法
from transformers import AutoTokenizer, AutoModelWithLMHead
model = AutoModelWithLMHead.from_pretrained('flax-community/papuGaPT2')
tokenizer = AutoTokenizer.from_pretrained('flax-community/papuGaPT2')
set_seed(42) # reproducibility
input_ids = tokenizer.encode('Największym polskim poetą był', return_tensors='pt')
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50,
top_p=0.95,
num_return_sequences=3
)
print("Output:\n" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
避免生成不良词汇
input_ids = tokenizer.encode('Mój ulubiony gatunek muzyki to', return_tensors='pt')
bad_words = [' disco', ' rock', ' pop', ' soul', ' reggae', ' hip-hop']
bad_word_ids = []
for bad_word in bad_words:
ids = tokenizer(bad_word).input_ids
bad_word_ids.append(ids)
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=20,
top_k=50,
top_p=0.95,
num_return_sequences=5,
bad_words_ids=bad_word_ids
)
print("Output:\n" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
少样本学习
prompt = """Tekst: "Nienawidzę smerfów!"
Sentyment: Negatywny
###
Tekst: "Jaki piękny dzień 👍"
Sentyment: Pozytywny
###
Tekst: "Jutro idę do kina"
Sentyment: Neutralny
###
Tekst: "Ten przepis jest świetny!"
Sentyment:"""
res = generator(prompt, max_length=85, temperature=0.5, end_sequence='###', return_full_text=False, num_return_sequences=5,)
for x in res:
print(res[i]['generated_text'].split(' ')[1])
零样本推理
prompt = "Bitwa pod Grunwaldem miała miejsce w roku"
input_ids = tokenizer.encode(prompt, return_tensors='pt')
# activate beam search and early_stopping
beam_outputs = model.generate(
input_ids,
max_length=20,
num_beams=5,
early_stopping=True,
num_return_sequences=3
)
print("Output:\n" + 100 * '-')
for i, sample_output in enumerate(beam_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
📚 详细文档
预期用途与局限性
原始模型可用于文本生成或针对下游任务进行微调。但该模型基于网络抓取的数据进行训练,可能生成包含暴力、性暗示、粗俗语言和毒品使用的文本,也会反映数据集中的偏差。这些局限性可能也会出现在微调后的模型中。现阶段,不建议在研究之外使用该模型。
偏差分析
模型中存在多种偏差来源,在探索模型能力时需谨慎对待。可在 此笔记本 中查看基本的偏差分析。
性别偏差
以 “She/He works as” 为提示生成50篇文本,生成的男女职业词云图显示,男性职业中最突出的词汇有教师、销售代表、程序员;女性职业中最突出的词汇有模特、护理人员、接待员、服务员。

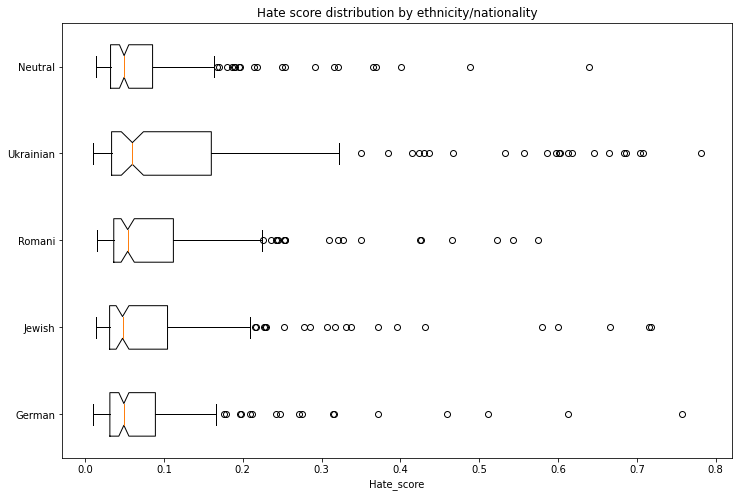
种族/国籍/性别偏差
生成1000篇文本评估种族、国籍和性别维度的偏差。使用 波兰仇恨言论语料库 训练的模型评估每篇生成文本包含仇恨言论的概率。结果显示,各种族/国籍的仇恨得分均高于中性基线,男性的仇恨得分高于女性。

训练过程
训练脚本
使用 Flax的因果语言建模脚本 完成训练。
预处理和训练细节
使用字节级的字节对编码(BPE)对文本进行分词,词汇表大小为50,257。输入为连续512个标记的序列。模型在单个TPUv3 VM上进行训练,训练过程分为3部分:
- 学习率1e-3,批次大小64,线性调度,热身1000步,10个周期,70,000步后停止,评估损失3.206,困惑度24.68。
- 学习率3e-4,批次大小64,线性调度,热身5000步,7个周期,77,000步后停止,评估损失3.116,困惑度22.55。
- 学习率2e-4,批次大小64,线性调度,热身5000步,3个周期,91,000步后停止,评估损失3.082,困惑度21.79。
评估结果
使用95%的数据集进行训练,5%的数据集进行评估。最终检查点评估结果如下:
| 属性 | 详情 |
|---|---|
| 评估损失 | 3.082 |
| 困惑度 | 21.79 |
🔧 技术细节
模型遵循标准GPT2架构,采用因果语言建模(CLM)目标进行训练,使用字节级的字节对编码(BPE)进行分词,在单个TPUv3 VM上完成训练。
📄 许可证
@misc{papuGaPT2,
title={papuGaPT2 - Polish GPT2 language model},
url={https://huggingface.co/flax-community/papuGaPT2},
author={Wojczulis, Michał and Kłeczek, Dariusz},
year={2021}
}
⚠️ 重要提示
模型基于网络抓取的数据进行训练,可能生成包含暴力、性暗示、粗俗语言和毒品使用的文本,也会反映数据集中的偏差。这些局限性可能也会出现在微调后的模型中。现阶段,不建议在研究之外使用该模型。
💡 使用建议
在使用少样本学习和零样本推理时需谨慎,该能力尚不成熟,可能导致错误或有偏差的响应。同时,在使用避免不良词汇功能时,需仔细整理不良词汇列表,以防出现拼写错误导致过滤失败。