🚀 用于视觉的Perceiver IO(卷积处理)
Perceiver IO是一种可应用于任何模态(文本、图像、音频、视频等)的Transformer编码器模型。本模型在分辨率为224x224的ImageNet(1400万张图像,1000个类别)上进行了预训练。它由Jaegle等人在论文Perceiver IO: A General Architecture for Structured Inputs & Outputs中提出,并首次在此仓库中发布。
声明:发布Perceiver IO的团队并未为此模型撰写模型卡片,此模型卡片由Hugging Face团队编写。
✨ 主要特性
- 多模态适用性:可应用于文本、图像、音频、视频等多种模态。
- 高效的注意力机制:通过对少量潜在向量应用自注意力机制,使时间和内存需求不依赖于输入大小。
- 灵活的解码方式:使用解码器查询,可灵活解码潜在向量的最终隐藏状态,以产生任意大小和语义的输出。
📚 详细文档
模型描述
Perceiver IO是一个Transformer编码器模型,其核心思想是在一组数量不大的潜在向量(例如256或512)上应用自注意力机制,仅使用输入与潜在向量进行交叉注意力计算。这样,自注意力机制的时间和内存需求就不依赖于输入的大小。
为了解码,作者采用了所谓的解码器查询,它可以灵活地将潜在向量的最终隐藏状态解码为任意大小和语义的输出。对于图像分类任务,输出是一个包含对数概率的张量,形状为(batch_size, num_labels)。
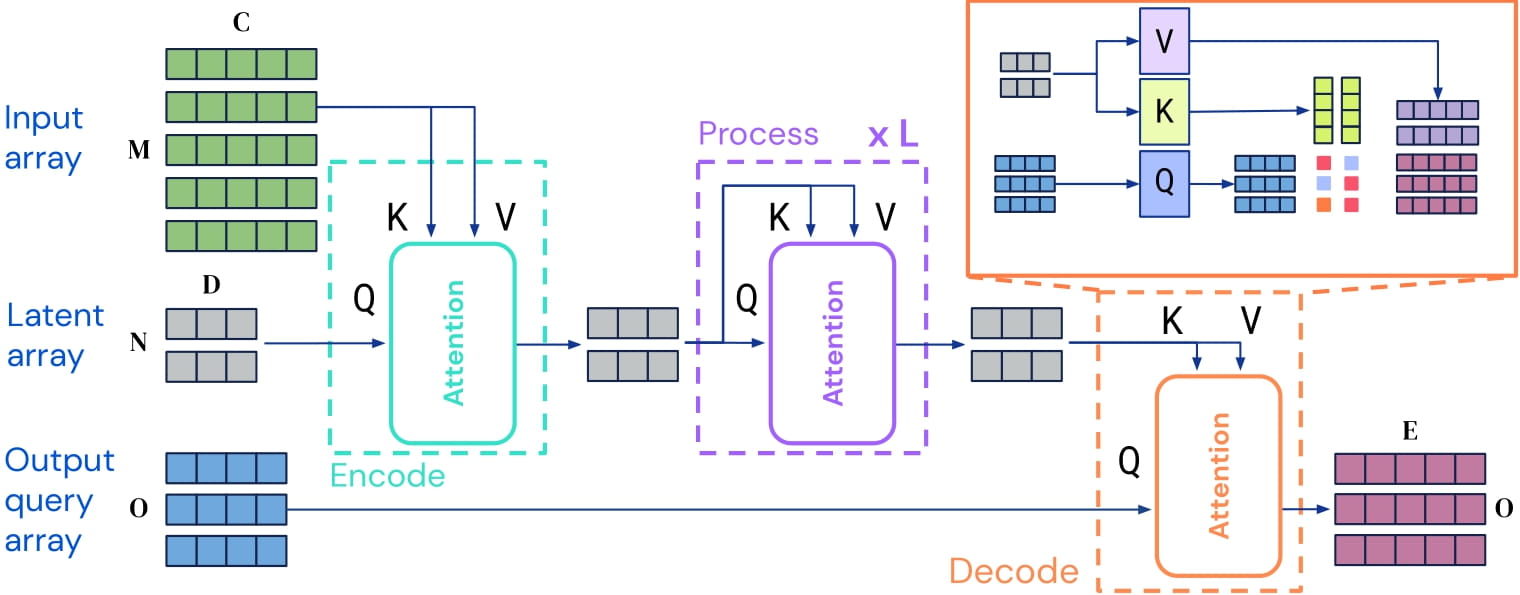
Perceiver IO架构。
由于自注意力机制的时间和内存需求不依赖于输入大小,Perceiver IO的作者可以直接在原始像素值上训练模型,而不是像ViT那样在图像块上训练。这个特定的模型在使用输入与潜在向量进行交叉注意力计算之前,会在像素值上应用一个简单的2D卷积+最大池化预处理网络。
通过对模型进行预训练,它可以学习到图像的内部表示,这些表示可用于提取对下游任务有用的特征。例如,如果你有一个带标签的图像数据集,可以通过替换分类解码器来训练一个标准的分类器。
预期用途和限制
你可以使用原始模型进行图像分类。请查看模型中心,以寻找其他可能符合你需求的微调版本。
训练数据
该模型在ImageNet数据集上进行了预训练,该数据集包含1400万张图像和1000个类别。
训练过程
预处理
图像会进行中心裁剪并调整为224x224的分辨率,并在RGB通道上进行归一化。请注意,在预训练期间使用了数据增强,具体细节可参考论文Perceiver IO: A General Architecture for Structured Inputs & Outputs的附录H。
预训练
超参数的详细信息可在论文Perceiver IO: A General Architecture for Structured Inputs & Outputs的附录H中找到。
评估结果
该模型在ImageNet-1k上能够达到82.1的top-1准确率。
💻 使用示例
基础用法
以下是如何在PyTorch中使用此模型的示例:
from transformers import PerceiverFeatureExtractor, PerceiverForImageClassificationConvProcessing
import requests
from PIL import Image
feature_extractor = PerceiverFeatureExtractor.from_pretrained("deepmind/vision-perceiver-conv")
model = PerceiverForImageClassificationConvProcessing.from_pretrained("deepmind/vision-perceiver-conv")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = feature_extractor(image, return_tensors="pt").pixel_values
outputs = model(inputs)
logits = outputs.logits
print("Predicted class:", model.config.id2label[logits.argmax(-1).item()])
>>> 应该输出 Predicted class: tabby, tabby cat
📄 许可证
本项目采用Apache-2.0许可证。
BibTeX引用
@article{DBLP:journals/corr/abs-2107-14795,
author = {Andrew Jaegle and
Sebastian Borgeaud and
Jean{-}Baptiste Alayrac and
Carl Doersch and
Catalin Ionescu and
David Ding and
Skanda Koppula and
Daniel Zoran and
Andrew Brock and
Evan Shelhamer and
Olivier J. H{\'{e}}naff and
Matthew M. Botvinick and
Andrew Zisserman and
Oriol Vinyals and
Jo{\~{a}}o Carreira},
title = {Perceiver {IO:} {A} General Architecture for Structured Inputs {\&}
Outputs},
journal = {CoRR},
volume = {abs/2107.14795},
year = {2021},
url = {https://arxiv.org/abs/2107.14795},
eprinttype = {arXiv},
eprint = {2107.14795},
timestamp = {Tue, 03 Aug 2021 14:53:34 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2107-14795.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多种语言
Transformers 支持多种语言