🚀 Perceiver IO for vision (convolutional processing)
A Perceiver IO model pre - trained on ImageNet for image classification, offering flexible input - output processing.
🚀 Quick Start
The Perceiver IO model presented here is pre - trained on ImageNet at a resolution of 224x224. It can be used for image classification tasks. You can find other fine - tuned versions on the model hub.
✨ Features
- Modality - agnostic: Can be applied to various modalities like text, images, audio, and video.
- Efficient self - attention: Uses self - attention on a small set of latent vectors, making time and memory requirements independent of input size.
- Flexible decoding: Employs decoder queries to produce outputs of arbitrary size and semantics.
- Direct pixel training: Can be trained directly on raw pixel values instead of patches.
💻 Usage Examples
Basic Usage
from transformers import PerceiverFeatureExtractor, PerceiverForImageClassificationConvProcessing
import requests
from PIL import Image
feature_extractor = PerceiverFeatureExtractor.from_pretrained("deepmind/vision-perceiver-conv")
model = PerceiverForImageClassificationConvProcessing.from_pretrained("deepmind/vision-perceiver-conv")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = feature_extractor(image, return_tensors="pt").pixel_values
outputs = model(inputs)
logits = outputs.logits
print("Predicted class:", model.config.id2label[logits.argmax(-1).item()])
>>> should print Predicted class: tabby, tabby cat
📚 Documentation
Model description
Perceiver IO is a transformer encoder model applicable to any modality. It uses self - attention on a small set of latent vectors and cross - attention with inputs. For decoding, decoder queries are used to produce outputs of arbitrary size and semantics. In image classification, the output is a tensor of logits.
The self - attention mechanism in Perceiver IO allows the model to be trained directly on raw pixel values. This specific model uses a 2D conv+maxpool preprocessing network on pixel values before cross - attention with latents. Pre - training the model enables it to learn an inner representation of images for downstream tasks.
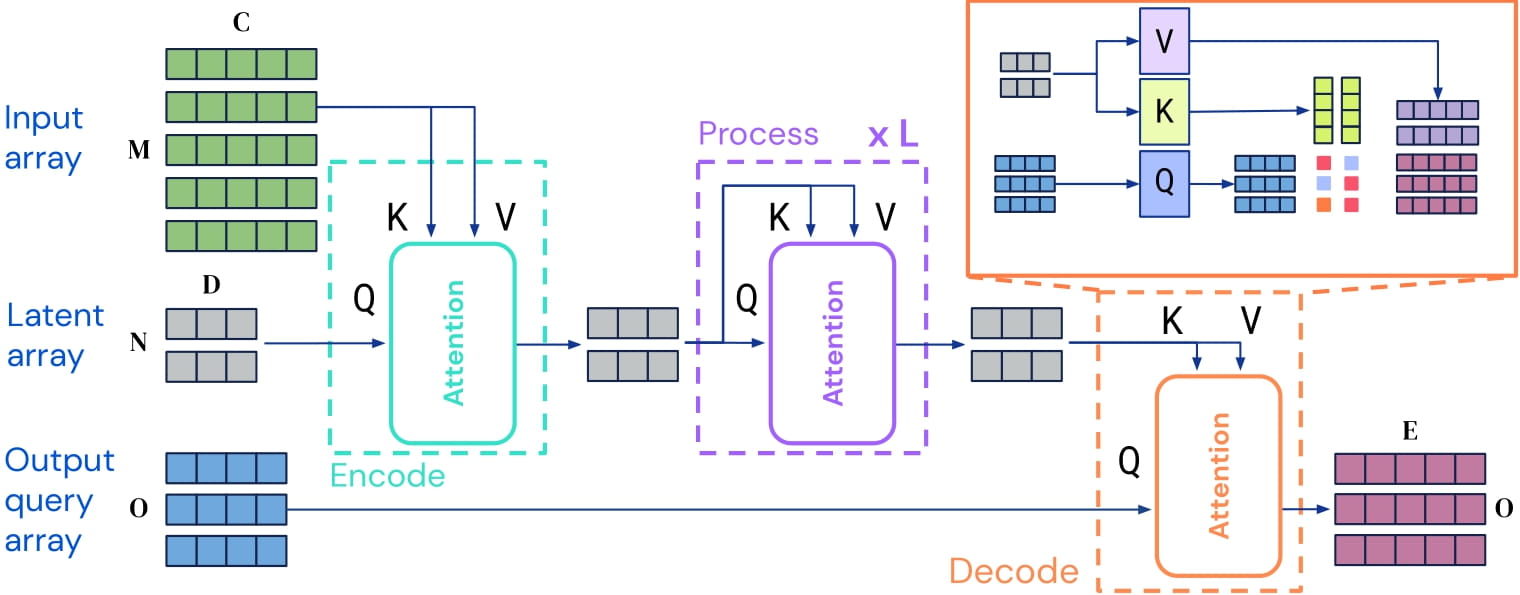 Perceiver IO architecture.
Perceiver IO architecture.
Intended uses & limitations
The raw model can be used for image classification. You can search for other fine - tuned versions on the model hub.
Training data
This model was pretrained on ImageNet, which consists of 14 million images and 1k classes.
Training procedure
Preprocessing
Images are center - cropped, resized to 224x224, and normalized across RGB channels. Data augmentation was used during pre - training as described in Appendix H of the paper.
Pretraining
Hyperparameter details can be found in Appendix H of the paper.
Evaluation results
This model achieves a top - 1 accuracy of 82.1 on ImageNet - 1k.
BibTeX entry and citation info
@article{DBLP:journals/corr/abs-2107-14795,
author = {Andrew Jaegle and
Sebastian Borgeaud and
Jean{-}Baptiste Alayrac and
Carl Doersch and
Catalin Ionescu and
David Ding and
Skanda Koppula and
Daniel Zoran and
Andrew Brock and
Evan Shelhamer and
Olivier J. H{\'{e}}naff and
Matthew M. Botvinick and
Andrew Zisserman and
Oriol Vinyals and
Jo{\~{a}}o Carreira},
title = {Perceiver {IO:} {A} General Architecture for Structured Inputs {\&}
Outputs},
journal = {CoRR},
volume = {abs/2107.14795},
year = {2021},
url = {https://arxiv.org/abs/2107.14795},
eprinttype = {arXiv},
eprint = {2107.14795},
timestamp = {Tue, 03 Aug 2021 14:53:34 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2107-14795.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
📄 License
This model is released under the Apache 2.0 license.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)