%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型简介
模型特点
模型能力
使用案例
🚀 Controlnet - v1.1 - 涂鸦版本
Controlnet v1.1 是一款强大的图像生成辅助模型,它能够为 Stable Diffusion 等大模型添加额外的条件控制,让图像生成更加精准和多样化,满足艺术创作等多种场景需求。
🚀 快速开始
Controlnet v1.1 是 Controlnet v1.0 的后续模型,由 Lvmin Zhang 在 lllyasviel/ControlNet-v1-1 中发布。
此检查点是将 原始检查点 转换为 diffusers 格式后的版本,可与 Stable Diffusion 结合使用,例如 runwayml/stable-diffusion-v1-5。
更多详细信息,请查看 🧨 Diffusers 文档。
ControlNet 是一种神经网络结构,可通过添加额外条件来控制扩散模型。

此检查点对应基于 涂鸦图像 进行条件控制的 ControlNet。
✨ 主要特性
- 支持额外输入条件:ControlNet 可以控制预训练的大型扩散模型,支持如边缘图、分割图、关键点等额外输入条件,丰富了控制大型扩散模型的方法。
- 端到端学习:能够以端到端的方式学习特定任务的条件,即使训练数据集较小(少于 50k),学习过程也很稳健。
- 训练速度快:训练 ControlNet 的速度与微调扩散模型相当,并且可以在个人设备上进行训练。如果有强大的计算集群,模型也可以处理大量(数百万到数十亿)的数据。
📦 安装指南
安装外部依赖
若要处理图像以创建辅助条件,需要安装以下外部依赖:
$ pip install controlnet_aux==0.3.0
安装 diffusers 及相关包
$ pip install diffusers transformers accelerate
💻 使用示例
基础用法
建议将此检查点与 Stable Diffusion v1-5 结合使用,因为该检查点是基于此进行训练的。实验表明,此检查点也可与其他扩散模型(如经过微调的 Stable Diffusion)一起使用。
import torch
import os
from huggingface_hub import HfApi
from pathlib import Path
from diffusers.utils import load_image
from PIL import Image
import numpy as np
from controlnet_aux import PidiNetDetector, HEDdetector
from diffusers import (
ControlNetModel,
StableDiffusionControlNetPipeline,
UniPCMultistepScheduler,
)
checkpoint = "lllyasviel/control_v11p_sd15_scribble"
image = load_image(
"https://huggingface.co/lllyasviel/control_v11p_sd15_scribble/resolve/main/images/input.png"
)
prompt = "royal chamber with fancy bed"
processor = HEDdetector.from_pretrained('lllyasviel/Annotators')
control_image = processor(image, scribble=True)
control_image.save("./images/control.png")
controlnet = ControlNetModel.from_pretrained(checkpoint, torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
generator = torch.manual_seed(0)
image = pipe(prompt, num_inference_steps=30, generator=generator, image=control_image).images[0]
image.save('images/image_out.png')
注意事项
⚠️ 重要提示
如果要处理图像以创建辅助条件,需要安装外部依赖,具体安装步骤见安装指南。
💡 使用建议
建议使用 Stable Diffusion v1-5 与该检查点配合使用,因为该检查点是基于此进行训练的。
📚 详细文档
模型详情
| 属性 | 详情 |
|---|---|
| 开发者 | Lvmin Zhang, Maneesh Agrawala |
| 模型类型 | 基于扩散的文本到图像生成模型 |
| 语言 | 英文 |
| 许可证 | CreativeML OpenRAIL M 许可证 是一种 Open RAIL M 许可证,改编自 BigScience 和 RAIL Initiative 在负责任 AI 许可领域的工作。有关此许可证的详细信息,请参阅 关于 BLOOM Open RAIL 许可证的文章。 |
| 更多信息资源 | GitHub 仓库,论文 |
| 引用格式 | @misc{zhang2023adding, title={Adding Conditional Control to Text-to-Image Diffusion Models}, author={Lvmin Zhang and Maneesh Agrawala}, year={2023}, eprint={2302.05543}, archivePrefix={arXiv}, primaryClass={cs.CV} } |
模型介绍
Controlnet 由 Lvmin Zhang 和 Maneesh Agrawala 在 Adding Conditional Control to Text-to-Image Diffusion Models 中提出。论文摘要如下:
我们提出了一种神经网络结构 ControlNet,用于控制预训练的大型扩散模型以支持额外的输入条件。ControlNet 以端到端的方式学习特定任务的条件,即使训练数据集较小(少于 50k),学习过程也很稳健。此外,训练 ControlNet 的速度与微调扩散模型相当,并且可以在个人设备上进行训练。或者,如果有强大的计算集群,模型可以处理大量(数百万到数十亿)的数据。我们发现,像 Stable Diffusion 这样的大型扩散模型可以通过添加 ControlNet 来支持边缘图、分割图、关键点等条件输入,这可能会丰富控制大型扩散模型的方法,并进一步促进相关应用的发展。
其他发布的检查点 v1-1
作者发布了 14 种不同的检查点,每种都基于 Stable Diffusion v1-5 在不同类型的条件下进行训练:
| 模型名称 | 控制图像概述 | 条件图像 | 控制图像示例 | 生成图像示例 |
|---|---|---|---|---|
| lllyasviel/control_v11p_sd15_canny |
基于 Canny 边缘检测进行训练 | 黑色背景上带有白色边缘的单色图像。 |  |
 |
| lllyasviel/control_v11e_sd15_ip2p |
基于像素到像素指令进行训练 | 无特定条件。 |  |
 |
| lllyasviel/control_v11p_sd15_inpaint |
基于图像修复进行训练 | 无特定条件。 |  |
 |
| lllyasviel/control_v11p_sd15_mlsd |
基于多级线段检测进行训练 | 带有标注线段的图像。 |  |
 |
| lllyasviel/control_v11f1p_sd15_depth |
基于深度估计进行训练 | 带有深度信息的图像,通常表示为灰度图像。 |  |
 |
| lllyasviel/control_v11p_sd15_normalbae |
基于表面法线估计进行训练 | 带有表面法线信息的图像,通常表示为彩色编码图像。 |  |
 |
| lllyasviel/control_v11p_sd15_seg |
基于图像分割进行训练 | 带有分割区域的图像,通常表示为彩色编码图像。 |  |
 |
| lllyasviel/control_v11p_sd15_lineart |
基于线条画生成进行训练 | 带有线条画的图像,通常是白色背景上的黑色线条。 |  |
 |
| lllyasviel/control_v11p_sd15s2_lineart_anime |
基于动漫线条画生成进行训练 | 带有动漫风格线条画的图像。 |  |
 |
| lllyasviel/control_v11p_sd15_openpose |
基于人体姿态估计进行训练 | 带有人体姿态的图像,通常表示为一组关键点或骨架。 | 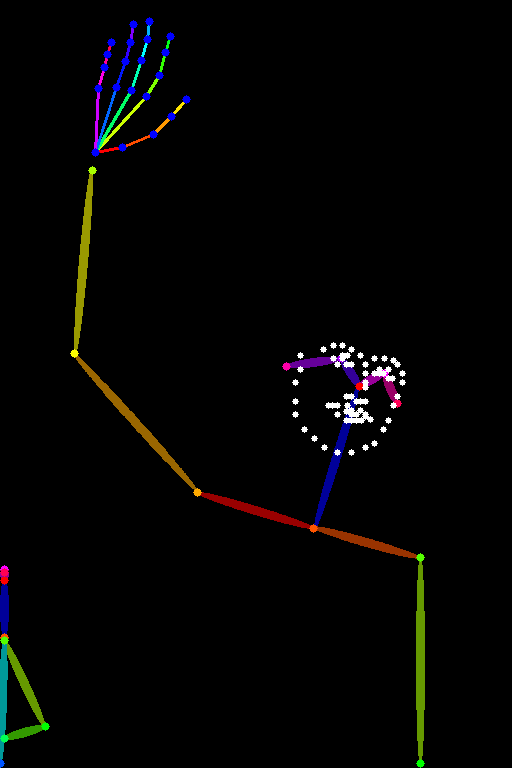 |
 |
| lllyasviel/control_v11p_sd15_scribble |
基于涂鸦图像生成进行训练 | 带有涂鸦的图像,通常是随机或用户绘制的笔触。 |  |
 |
| lllyasviel/control_v11p_sd15_softedge |
基于软边缘图像生成进行训练 | 带有软边缘的图像,通常用于创建更具绘画感或艺术效果的图像。 |  |
 |
| lllyasviel/control_v11e_sd15_shuffle |
基于图像打乱进行训练 | 带有打乱的图像块或区域的图像。 |  |
 |
| lllyasviel/control_v11f1e_sd15_tile |
基于图像拼接进行训练 | 模糊的图像或图像的一部分。 |  |
 |
涂鸦 1.1 版本的改进
- 训练数据集优化:之前的 cnet 1.0 训练数据集存在一些问题,包括(1)一小部分灰度人体图像被重复数千次,导致之前的模型容易生成灰度人体图像;(2)一些图像质量较低、模糊或有明显的 JPEG 伪影;(3)由于数据处理脚本的错误,一小部分图像的提示信息配对错误。新模型解决了训练数据集的所有问题,在许多情况下表现更合理。
- 对厚涂鸦的支持:考虑到用户有时喜欢绘制非常粗的涂鸦,我们使用了更激进的随机形态变换来合成涂鸦。即使涂鸦相对较粗(训练数据在 512 画布上的最大宽度为 24 像素宽的涂鸦,但对于稍宽的涂鸦似乎也能正常工作;最小宽度为 1 像素),该模型也能正常工作。
- 持续训练:在涂鸦 1.0 的基础上,继续使用 A100 80G GPU 进行了 200 小时的训练。
📄 许可证
本模型使用 OpenRAIL 许可证。
更多信息
如需更多信息,请查看 Diffusers ControlNet 博客文章 和 官方文档。