🚀 InternViT-6B-448px-V2_5
InternViT-6B-448px-V2_5 是基于 InternViT-6B-448px-V1-5 进行显著增强的模型。它采用了带有NTP损失的ViT增量学习,提升了视觉编码器提取视觉特征的能力,能捕获更全面的信息,尤其在大规模网络数据集(如LAION - 5B)中代表性不足的领域表现出色。
[📂 GitHub] [📜 InternVL 1.0] [📜 InternVL 1.5] [📜 Mini-InternVL] [📜 InternVL 2.5]
[🆕 Blog] [🗨️ Chat Demo] [🤗 HF Demo] [🚀 Quick Start] [📖 Documents]
🚀 快速开始
⚠️ 重要提示
根据经验,InternViT V2.5系列更适合用于构建多语言大语言模型(MLLMs),而非传统的计算机视觉任务。
import torch
from PIL import Image
from transformers import AutoModel, CLIPImageProcessor
model = AutoModel.from_pretrained(
'OpenGVLab/InternViT-6B-448px-V2_5',
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True).cuda().eval()
image = Image.open('./examples/image1.jpg').convert('RGB')
image_processor = CLIPImageProcessor.from_pretrained('OpenGVLab/InternViT-6B-448px-V2_5')
pixel_values = image_processor(images=image, return_tensors='pt').pixel_values
pixel_values = pixel_values.to(torch.bfloat16).cuda()
outputs = model(pixel_values)
✨ 主要特性
- 基于
InternViT-6B-448px-V1-5 进行增强,采用ViT增量学习,提升视觉特征提取能力。
- 能捕获更全面的信息,尤其在多语言OCR数据和数学图表等领域表现出色。
- 支持多图像和视频数据,采用动态高分辨率训练策略。
📦 模型信息
| 属性 |
详情 |
| 模型类型 |
图像特征提取 |
| 基础模型 |
OpenGVLab/InternViT-6B-448px-V1-5 |
| 基础模型关系 |
微调 |
📚 详细文档
InternViT 2.5 家族
以下表格展示了InternViT 2.5系列的概况:
| 模型名称 |
Hugging Face链接 |
| InternViT-300M-448px-V2_5 |
🤗 link |
| InternViT-6B-448px-V2_5 |
🤗 link |
模型架构
如下图所示,InternVL 2.5保留了与前代版本(InternVL 1.5和2.0)相同的模型架构,遵循“ViT - MLP - LLM”范式。在这个新版本中,我们使用随机初始化的MLP投影器,将新的增量预训练的InternViT与各种预训练的大语言模型(LLM)集成在一起,包括InternLM 2.5和Qwen 2.5。

与之前的版本一样,我们应用了像素重排操作,将视觉标记的数量减少到原来的四分之一。此外,我们采用了与InternVL 1.5类似的动态分辨率策略,将图像分割成448×448像素的图块。从InternVL 2.0开始,关键的区别在于我们额外引入了对多图像和视频数据的支持。
训练策略
多模态数据的动态高分辨率训练
在InternVL 2.0和2.5中,我们扩展了动态高分辨率训练方法,增强了其处理多图像和视频数据集的能力。

- 对于单图像数据集,将总图块数
n_max 分配给单个图像以获得最大分辨率。视觉标记用 <img> 和 </img> 标签括起来。
- 对于多图像数据集,将总图块数
n_max 分配到一个样本中的所有图像上。每个图像用 Image - 1 等辅助标签标记,并使用 <img> 和 </img> 标签括起来。
- 对于视频,每个帧被调整为448×448。帧用
Frame - 1 等标签标记,并使用 <img> 和 </img> 标签括起来,与图像类似。
单模型训练流程
InternVL 2.5中单个模型的训练流程分为三个阶段,旨在增强模型的视觉感知和多模态能力。

- 阶段1:MLP预热:在这个阶段,只训练MLP投影器,而视觉编码器和语言模型被冻结。应用动态高分辨率训练策略以获得更好的性能,尽管成本会增加。此阶段确保了强大的跨模态对齐,并为模型的稳定多模态训练做好准备。
- 阶段1.5:ViT增量学习(可选):此阶段允许使用与阶段1相同的数据对视觉编码器和MLP投影器进行增量训练。它增强了编码器处理多语言OCR和数学图表等罕见领域的能力。一旦训练完成,编码器可以在不同的大语言模型之间重复使用,而无需重新训练,因此除非引入新的领域,否则此阶段是可选的。
- 阶段2:全模型指令微调:在高质量的多模态指令数据集上训练整个模型。实施严格的数据质量控制,以防止大语言模型性能下降,因为嘈杂的数据可能会导致输出重复或错误等问题。此阶段完成后,训练过程结束。
视觉能力评估
我们对视觉编码器在各个领域和任务中的性能进行了全面评估。评估分为两个关键类别:(1)图像分类,代表全局视图语义质量;(2)语义分割,捕获局部视图语义质量。这种方法使我们能够评估InternViT在其连续版本更新中的表示质量。更多详细信息请参考我们的技术报告。
图像分类
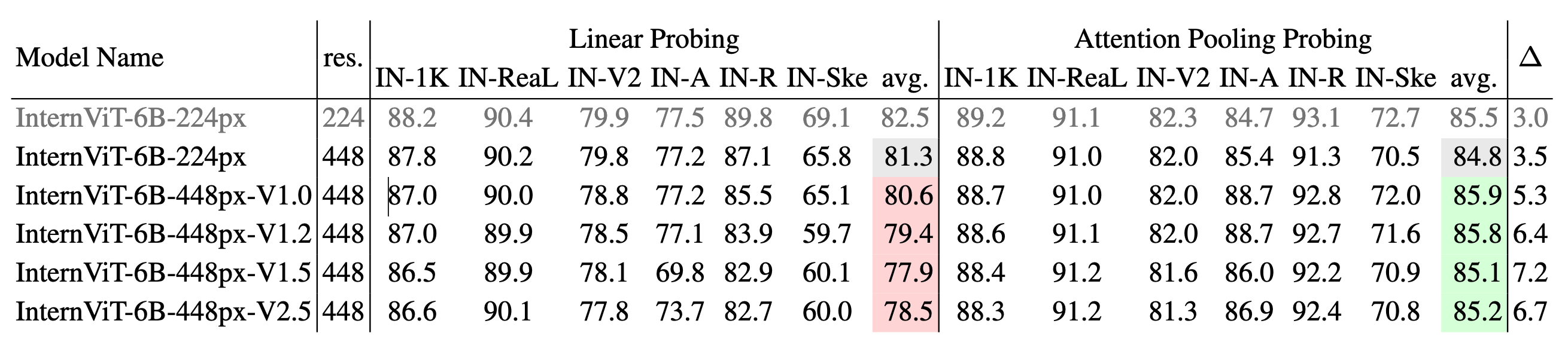
不同版本InternViT的图像分类性能:我们使用IN - 1K进行训练,并在IN - 1K验证集以及多个ImageNet变体(包括IN - ReaL、IN - V2、IN - A、IN - R和IN - Sketch)上进行评估。报告了线性探测和注意力池化探测方法的结果,并给出了每种方法的平均准确率。∆ 表示注意力池化探测和线性探测之间的性能差距,∆ 值越大表明从学习简单的线性特征向捕获更复杂的非线性语义表示的转变。
语义分割性能

不同版本InternViT的语义分割性能:在ADE20K和COCO - Stuff - 164K上使用三种配置(线性探测、头部微调、全微调)对模型进行评估。表格显示了每种配置的mIoU分数及其平均值。∆1 表示头部微调与线性探测之间的差距,而∆2 表示全微调与线性探测之间的差距。∆ 值越大表明从简单的线性特征向更复杂的非线性表示的转变。
🔧 技术细节
文档中未详细提及具体技术细节,但从训练策略和评估等方面可推测,模型在架构设计、训练方法和数据处理上采用了多种技术手段来提升性能,如ViT增量学习、动态高分辨率训练、严格的数据质量控制等。
📄 许可证
本项目采用MIT许可证发布。
引用
如果您在研究中发现本项目有用,请考虑引用以下文献:
@article{chen2024expanding,
title={Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling},
author={Chen, Zhe and Wang, Weiyun and Cao, Yue and Liu, Yangzhou and Gao, Zhangwei and Cui, Erfei and Zhu, Jinguo and Ye, Shenglong and Tian, Hao and Liu, Zhaoyang and others},
journal={arXiv preprint arXiv:2412.05271},
year={2024}
}
@article{gao2024mini,
title={Mini-internvl: A flexible-transfer pocket multimodal model with 5\% parameters and 90\% performance},
author={Gao, Zhangwei and Chen, Zhe and Cui, Erfei and Ren, Yiming and Wang, Weiyun and Zhu, Jinguo and Tian, Hao and Ye, Shenglong and He, Junjun and Zhu, Xizhou and others},
journal={arXiv preprint arXiv:2410.16261},
year={2024}
}
@article{chen2024far,
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
journal={arXiv preprint arXiv:2404.16821},
year={2024}
}
@inproceedings{chen2024internvl,
title={Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={24185--24198},
year={2024}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)


 Transformers 支持多种语言
Transformers 支持多种语言