%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型简介
模型特点
模型能力
使用案例
🚀 Mistral 7B OpenOrca - GGUF
本项目提供了 OpenOrca的Mistral 7B OpenOrca 模型的GGUF格式文件。GGUF格式是由llama.cpp团队推出的新型模型格式,具有更好的兼容性和性能。

TheBloke的大语言模型工作得到了 andreessen horowitz (a16z) 的慷慨资助
🚀 快速开始
本项目提供了Mistral 7B OpenOrca模型的GGUF格式文件,你可以根据自己的需求选择合适的量化文件进行下载和使用。下面将为你介绍相关的兼容性、下载方法和运行示例。
✨ 主要特性
- 多种量化格式:提供了2、3、4、5、6和8位的GGUF量化模型,适用于不同的硬件环境和应用场景。
- 广泛的兼容性:与llama.cpp及众多第三方UI和库兼容,方便用户进行推理和开发。
- 高性能:基于Mistral 7B OpenOrca模型,在多个评估指标上表现出色。
📦 安装指南
下载GGUF文件
- 自动下载:LM Studio、LoLLMS Web UI、Faraday.dev等客户端/库会自动为你下载模型,并提供可用模型列表供你选择。
- 手动下载:不建议克隆整个仓库,因为提供了多种不同的量化格式,大多数用户只需要选择并下载单个文件。
在text-generation-webui中下载
在“Download Model”下,输入模型仓库地址 TheBloke/Mistral-7B-OpenOrca-GGUF,并在下方输入具体的文件名,如 mistral-7b-openorca.Q4_K_M.gguf,然后点击“Download”。
在命令行下载单个文件
推荐使用huggingface-hub Python库:
pip3 install huggingface-hub
然后使用以下命令将单个模型文件高速下载到当前目录:
huggingface-cli download TheBloke/Mistral-7B-OpenOrca-GGUF mistral-7b-openorca.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
高级下载用法
你可以使用通配符一次性下载多个文件:
huggingface-cli download TheBloke/Mistral-7B-OpenOrca-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
更多关于huggingface-cli下载的文档,请参考:HF -> Hub Python Library -> Download files -> Download from the CLI。
为了在高速连接(1Gbit/s或更高)下加速下载,安装hf_transfer:
pip3 install hf_transfer
并将环境变量HF_HUB_ENABLE_HF_TRANSFER设置为1:
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Mistral-7B-OpenOrca-GGUF mistral-7b-openorca.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
Windows命令行用户可以在下载命令前运行set HF_HUB_ENABLE_HF_TRANSFER=1来设置环境变量。
💻 使用示例
在llama.cpp中运行
确保你使用的是2023年8月27日之后的llama.cpp版本(提交号:d0cee0d)。
./main -ngl 32 -m mistral-7b-openorca.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<|im_start|>system\n{system_message}<|im_end|>\n<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant"
-ngl 32:将其改为要卸载到GPU的层数。如果没有GPU加速,请移除该参数。-c 2048:将其改为所需的序列长度。对于扩展序列模型(如8K、16K、32K),必要的RoPE缩放参数会从GGUF文件中读取,并由llama.cpp自动设置。- 如果你想进行聊天式对话,将
-p <PROMPT>参数替换为-i -ins。
更多参数及使用方法,请参考 llama.cpp文档。
在text-generation-webui中运行
更多说明请参考:text-generation-webui/docs/llama.cpp.md。
在Python代码中运行
你可以使用 llama-cpp-python 或 ctransformers 库从Python中使用GGUF模型。
使用ctransformers加载模型
安装包
根据你的系统运行以下命令之一:
# 无GPU加速的基础ctransformers
pip install ctransformers
# 或使用CUDA GPU加速
pip install ctransformers[cuda]
# 或使用AMD ROCm GPU加速(仅适用于Linux)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# 或使用Metal GPU加速(仅适用于macOS系统)
CT_METAL=1 pip install ctransformers --no-binary ctransformers
简单的ctransformers示例代码
from ctransformers import AutoModelForCausalLM
# 将gpu_layers设置为要卸载到GPU的层数。如果你的系统没有GPU加速,请将其设置为0。
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Mistral-7B-OpenOrca-GGUF", model_file="mistral-7b-openorca.Q4_K_M.gguf", model_type="mistral", gpu_layers=50)
print(llm("AI is going to"))
与LangChain一起使用
以下是使用llama-cpp-python和ctransformers与LangChain的指南:
📚 详细文档
关于GGUF
GGUF是llama.cpp团队在2023年8月21日推出的新格式,它是GGML的替代品,目前GGML已不再受llama.cpp支持。
以下是已知支持GGUF的客户端和库的不完全列表:
- llama.cpp:GGUF的源项目,提供CLI和服务器选项。
- text-generation-webui:最广泛使用的Web UI,具有许多功能和强大的扩展,支持GPU加速。
- KoboldCpp:功能齐全的Web UI,支持跨所有平台和GPU架构的GPU加速,尤其适合讲故事。
- LM Studio:适用于Windows和macOS(Silicon)的易于使用且功能强大的本地GUI,支持GPU加速。
- LoLLMS Web UI:一个很棒的Web UI,具有许多有趣和独特的功能,包括一个完整的模型库,便于模型选择。
- Faraday.dev:一个有吸引力且易于使用的基于角色的聊天GUI,适用于Windows和macOS(Silicon和Intel),支持GPU加速。
- ctransformers:一个支持GPU加速、LangChain和OpenAI兼容AI服务器的Python库。
- llama-cpp-python:一个支持GPU加速、LangChain和OpenAI兼容API服务器的Python库。
- candle:一个Rust机器学习框架,专注于性能,包括GPU支持和易用性。
可用的仓库
- 用于GPU推理的AWQ模型
- 用于GPU推理的GPTQ模型,具有多种量化参数选项
- 用于CPU+GPU推理的2、3、4、5、6和8位GGUF模型
- OpenOrca的原始未量化fp16 PyTorch格式模型,用于GPU推理和进一步转换
提示模板:ChatML
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
兼容性
这些量化的GGUFv2文件与2023年8月27日之后的llama.cpp版本兼容(提交号:d0cee0d)。
它们也与许多第三方UI和库兼容,请参阅本README顶部的列表。
量化方法说明
点击查看详情
新的量化方法如下:
- GGML_TYPE_Q2_K:“type-1” 2位量化,超级块包含16个块,每个块有16个权重。块的缩放和最小值用4位量化,最终每个权重有效使用2.5625位(bpw)。
- GGML_TYPE_Q3_K:“type-0” 3位量化,超级块包含16个块,每个块有16个权重。缩放用6位量化,最终使用3.4375 bpw。
- GGML_TYPE_Q4_K:“type-1” 4位量化,超级块包含8个块,每个块有32个权重。缩放和最小值用6位量化,最终使用4.5 bpw。
- GGML_TYPE_Q5_K:“type-1” 5位量化,与GGML_TYPE_Q4_K具有相同的超级块结构,最终使用5.5 bpw。
- GGML_TYPE_Q6_K:“type-0” 6位量化,超级块包含16个块,每个块有16个权重。缩放用8位量化,最终使用6.5625 bpw。
请参考下面的“提供的文件”表,了解哪些文件使用了哪些方法以及如何使用。
提供的文件
| 名称 | 量化方法 | 位数 | 大小 | 所需最大RAM | 使用场景 |
|---|---|---|---|---|---|
| mistral-7b-openorca.Q2_K.gguf | Q2_K | 2 | 3.08 GB | 5.58 GB | 最小,但质量损失显著,不建议用于大多数场景 |
| mistral-7b-openorca.Q3_K_S.gguf | Q3_K_S | 3 | 3.16 GB | 5.66 GB | 非常小,但质量损失高 |
| mistral-7b-openorca.Q3_K_M.gguf | Q3_K_M | 3 | 3.52 GB | 6.02 GB | 非常小,但质量损失高 |
| mistral-7b-openorca.Q3_K_L.gguf | Q3_K_L | 3 | 3.82 GB | 6.32 GB | 小,但质量损失较大 |
| mistral-7b-openorca.Q4_0.gguf | Q4_0 | 4 | 4.11 GB | 6.61 GB | 旧版本;小,但质量损失非常高,建议使用Q3_K_M |
| mistral-7b-openorca.Q4_K_S.gguf | Q4_K_S | 4 | 4.14 GB | 6.64 GB | 小,但质量损失更大 |
| mistral-7b-openorca.Q4_K_M.gguf | Q4_K_M | 4 | 4.37 GB | 6.87 GB | 中等,质量平衡,推荐使用 |
| mistral-7b-openorca.Q5_0.gguf | Q5_0 | 5 | 5.00 GB | 7.50 GB | 旧版本;中等,质量平衡,建议使用Q4_K_M |
| mistral-7b-openorca.Q5_K_S.gguf | Q5_K_S | 5 | 5.00 GB | 7.50 GB | 大,质量损失低,推荐使用 |
| mistral-7b-openorca.Q5_K_M.gguf | Q5_K_M | 5 | 5.13 GB | 7.63 GB | 大,质量损失非常低,推荐使用 |
| mistral-7b-openorca.Q6_K.gguf | Q6_K | 6 | 5.94 GB | 8.44 GB | 非常大,质量损失极低 |
| mistral-7b-openorca.Q8_0.gguf | Q8_0 | 8 | 7.70 GB | 10.20 GB | 非常大,质量损失极低,但不建议使用 |
注意:上述RAM数字假设没有进行GPU卸载。如果将层卸载到GPU,将减少RAM使用,转而使用VRAM。
🔧 技术细节
原始模型信息
| 属性 | 详情 |
|---|---|
| 模型创建者 | OpenOrca |
| 原始模型 | Mistral 7B OpenOrca |
| 模型类型 | mistral |
| 训练数据 | Open-Orca/OpenOrca |
| 推理 | false |
| 语言 | en |
| 库名称 | transformers |
| 许可证 | apache-2.0 |
| 量化者 | TheBloke |
评估结果
HuggingFace排行榜性能
使用HuggingFace排行榜的评估方法和工具进行评估,发现该模型在基础模型的基础上有显著提升。在HF排行榜评估中,达到了基础模型性能的105%,平均得分为65.33。
发布时,该模型击败了所有7B模型,以及除一个13B模型之外的所有其他模型。
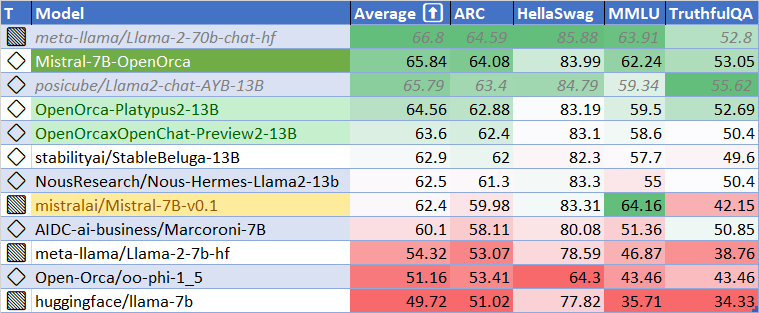
| 指标 | 值 |
|---|---|
| MMLU (5-shot) | 61.73 |
| ARC (25-shot) | 63.57 |
| HellaSwag (10-shot) | 83.79 |
| TruthfulQA (0-shot) | 52.24 |
| 平均值 | 65.33 |
AGIEval性能
与基础Mistral-7B模型(使用LM Evaluation Harness)进行比较,发现该模型在AGI评估中达到了基础模型性能的129%,平均得分为0.397。同时,显著优于官方的mistralai/Mistral-7B-Instruct-v0.1微调模型,达到了其性能的119%。
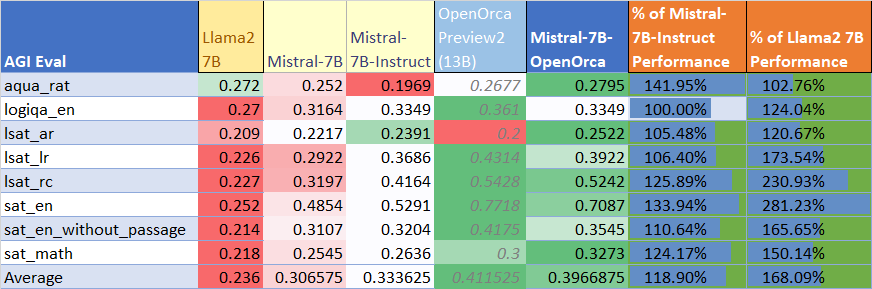
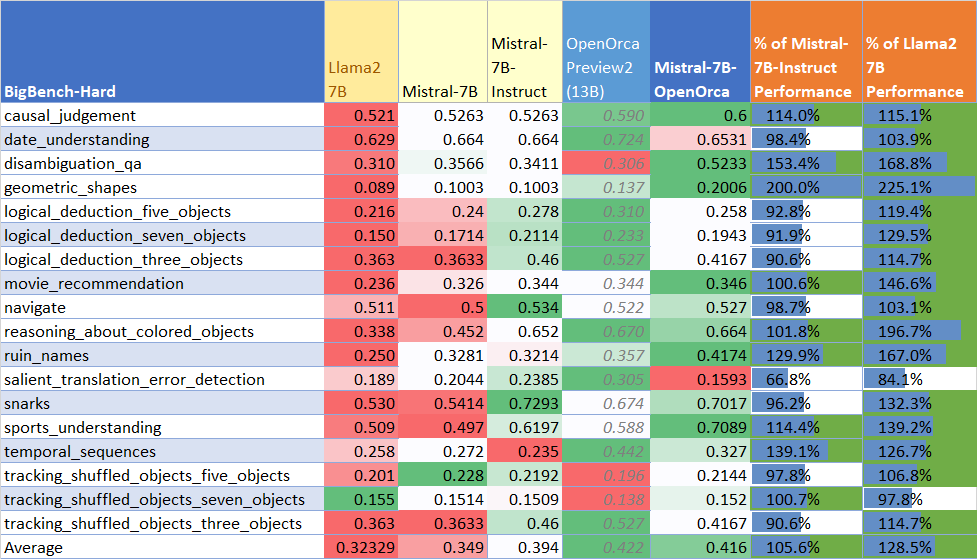
BigBench-Hard性能
该模型在BigBench-Hard评估中达到了基础模型性能的119%,平均得分为0.416。
训练信息
使用8个A6000 GPU进行了62小时的训练,在一次训练运行中对数据集进行了4个epoch的全量微调。训练成本约为400美元。
引用信息
@software{lian2023mistralorca1
title = {MistralOrca: Mistral-7B Model Instruct-tuned on Filtered OpenOrcaV1 GPT-4 Dataset},
author = {Wing Lian and Bleys Goodson and Guan Wang and Eugene Pentland and Austin Cook and Chanvichet Vong and "Teknium"},
year = {2023},
publisher = {HuggingFace},
journal = {HuggingFace repository},
howpublished = {\url{https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca},
}
@misc{mukherjee2023orca,
title={Orca: Progressive Learning from Complex Explanation Traces of GPT-4},
author={Subhabrata Mukherjee and Arindam Mitra and Ganesh Jawahar and Sahaj Agarwal and Hamid Palangi and Ahmed Awadallah},
year={2023},
eprint={2306.02707},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{longpre2023flan,
title={The Flan Collection: Designing Data and Methods for Effective Instruction Tuning},
author={Shayne Longpre and Le Hou and Tu Vu and Albert Webson and Hyung Won Chung and Yi Tay and Denny Zhou and Quoc V. Le and Barret Zoph and Jason Wei and Adam Roberts},
year={2023},
eprint={2301.13688},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
📄 许可证
本项目使用apache-2.0许可证。
💬 Discord
如需进一步支持,或讨论这些模型和人工智能相关话题,请加入:TheBloke AI的Discord服务器
🙏 感谢与贡献
感谢 chirper.ai 团队!感谢 gpus.llm-utils.org 的Clay!
很多人询问是否可以进行贡献。我很乐意提供模型并帮助大家,也希望能有更多时间投入其中,并开展新的项目,如微调/训练。
如果你有能力且愿意贡献,我将非常感激,这将帮助我继续提供更多模型,并开展新的人工智能项目。
捐赠者将在所有人工智能/大语言模型/模型相关问题和请求上获得优先支持,访问私人Discord房间,以及其他福利。
- Patreon: https://patreon.com/TheBlokeAI
- Ko-Fi: https://ko-fi.com/TheBlokeAI
特别感谢:Aemon Algiz。
Patreon特别提及:Pierre Kircher、Stanislav Ovsiannikov、Michael Levine、Eugene Pentland、Andrey、준교 김、Randy H、Fred von Graf、Artur Olbinski、Caitlyn Gatomon、terasurfer、Jeff Scroggin、James Bentley、Vadim、Gabriel Puliatti、Harry Royden McLaughlin、Sean Connelly、Dan Guido、Edmond Seymore、Alicia Loh、subjectnull、AzureBlack、Manuel Alberto Morcote、Thomas Belote、Lone Striker、Chris Smitley、Vitor Caleffi、Johann-Peter Hartmann、Clay Pascal、biorpg、Brandon Frisco、sidney chen、transmissions 11、Pedro Madruga、jinyuan sun、Ajan Kanaga、Emad Mostaque、Trenton Dambrowitz、Jonathan Leane、Iucharbius、usrbinkat、vamX、George Stoitzev、Luke Pendergrass、theTransient、Olakabola、Swaroop Kallakuri、Cap'n Zoog、Brandon Phillips、Michael Dempsey、Nikolai Manek、danny、Matthew Berman、Gabriel Tamborski、alfie_i、Raymond Fosdick、Tom X Nguyen、Raven Klaugh、LangChain4j、Magnesian、Illia Dulskyi、David Ziegler、Mano Prime、Luis Javier Navarrete Lozano、Erik Bjäreholt、阿明、Nathan Dryer、Alex、Rainer Wilmers、zynix、TL、Joseph William Delisle、John Villwock、Nathan LeClaire、Willem Michiel、Joguhyik、GodLy、OG、Alps Aficionado、Jeffrey Morgan、ReadyPlayerEmma、Tiffany J. Kim、Sebastain Graf、Spencer Kim、Michael Davis、webtim、Talal Aujan、knownsqashed、John Detwiler、Imad Khwaja、Deo Leter、Jerry Meng、Elijah Stavena、Rooh Singh、Pieter、SuperWojo、Alexandros Triantafyllidis、Stephen Murray、Ai Maven、ya boyyy、Enrico Ros、Ken Nordquist、Deep Realms、Nicholas、Spiking Neurons AB、Elle、Will Dee、Jack West、RoA、Luke @flexchar、Viktor Bowallius、Derek Yates、Subspace Studios、jjj、Toran Billups、Asp the Wyvern、Fen Risland、Ilya、NimbleBox.ai、Chadd、Nitin Borwankar、Emre、Mandus、Leonard Tan、Kalila、K、Trailburnt、S_X、Cory Kujawski
感谢所有慷慨的赞助者和捐赠者!再次感谢a16z的慷慨资助。