🚀 EEVE-Korean-2.8B-v1.0
EEVE-Korean-2.8B-v1.0 是 microsoft/phi-2 的韩语词汇扩展版本,在多种韩语网络爬取数据集上进行了微调。该模型通过预训练新标记的嵌入并部分微调已有标记的 lm_head 嵌入,同时保留基础模型的原始参数,增强了对韩语的理解。


🚀 快速开始
加入我们的 Discord 社区!
如果您热衷于大语言模型领域,希望交流知识和见解,我们诚挚地邀请您加入我们的 Discord 服务器。需要注意的是,该服务器主要使用韩语交流。大语言模型领域发展迅速,如果不积极分享,我们的集体知识很快就会过时。让我们携手合作,产生更大的影响力!点击此处加入:Discord 链接。
✨ 主要特性
专业团队研发
| 研究人员 |
工程师 |
产品管理 |
用户体验设计 |
郑明浩
金承德
崔承泽 |
金健
里夫基·阿尔菲
韩相勋
姜贤允 |
许宝京 |
崔恩秀 |
模型优势
本模型是 microsoft/phi-2 的韩语词汇扩展版本,在 HuggingFace 上的各种韩语网络爬取数据集上进行了专门的微调。我们通过对新标记的嵌入进行预训练,并对已有标记的 lm_head 嵌入进行部分微调,同时保留基础模型的原始参数,从而扩展了模型对韩语的理解。
🔧 技术细节
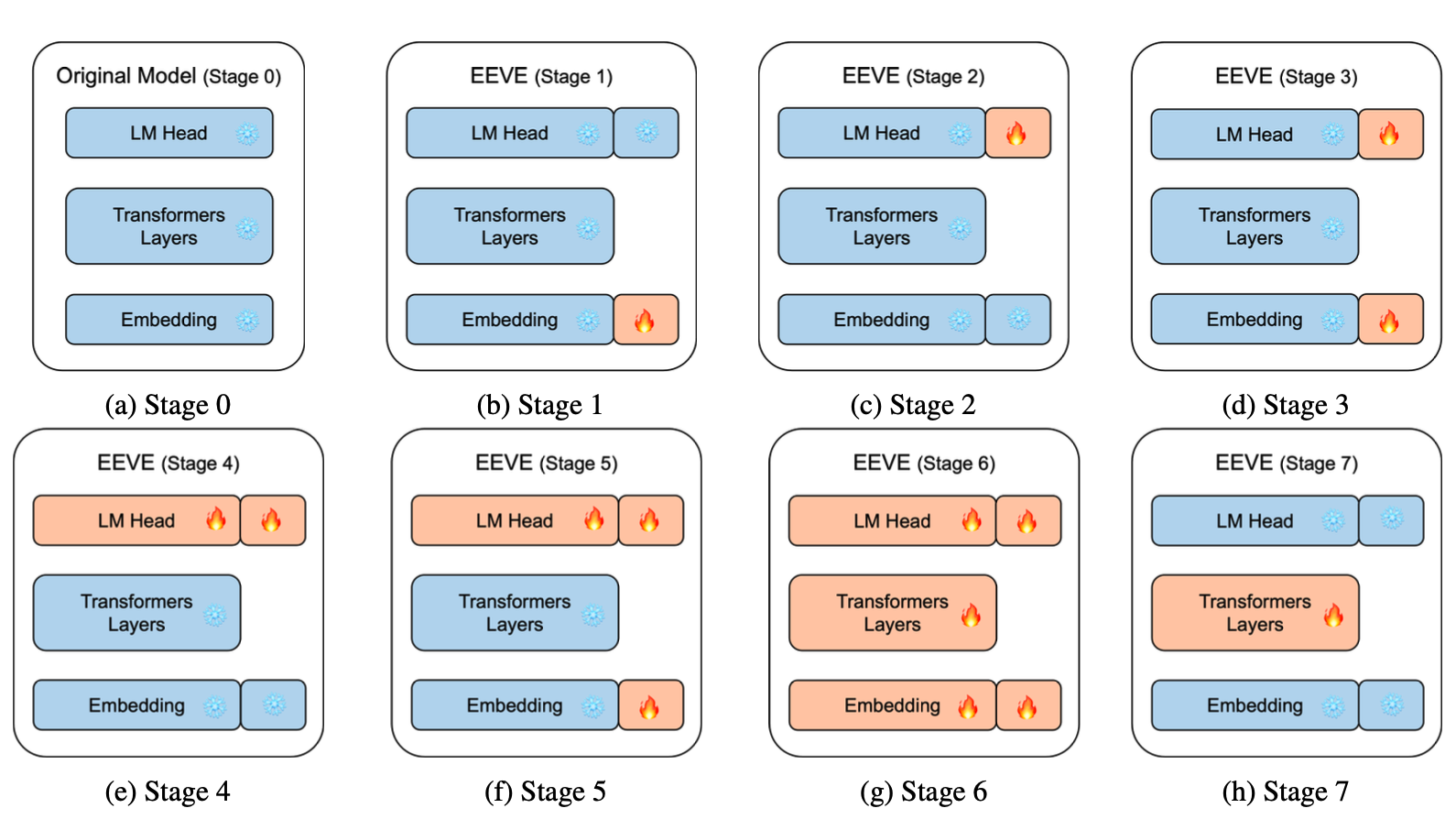
为了将基础模型从英语适配到韩语,我们采用了基于子词的嵌入方法,并进行了七阶段的参数冻结训练过程。这种方法从输入嵌入开始逐步训练到全参数,有效地将模型的词汇扩展到包括韩语。我们的方法通过精心整合新的语言标记,专注于因果语言建模预训练,增强了模型的跨语言适用性。我们利用在英语上训练的基础模型的固有能力,有效地将知识和推理迁移到韩语,优化了适配过程。
更多详细信息,请参考我们的技术报告:Efficient and Effective Vocabulary Expansion Towards Multilingual Large Language Models。
关键代码示例
def freeze_partial_embedding_hook(grad):
grad[:number_of_old_tokens] = 0
return grad
for name, param in model.named_parameters():
if ("lm_head" in name or "embed_tokens" in name) and "original" not in name:
param.requires_grad = True
if "embed_tokens" in name:
param.register_hook(freeze_partial_embedding_hook)
else:
param.requires_grad = False
使用与限制
请记住,此模型尚未进行基于指令的微调训练。虽然它在韩语任务中表现出色,但我们建议针对特定应用进行仔细考虑和进一步训练。
训练详情
我们的模型训练全面而多样:
- 词汇扩展:
我们根据韩语网络语料库中的出现频率,精心挑选了 8960 个韩语标记。这个过程涉及多轮分词器训练、手动筛选和标记频率分析,确保为我们的模型构建丰富且相关的词汇。
- 初始分词器训练:我们在韩语网络语料库上训练了一个中间分词器,词汇量为 40000 个标记。
- 提取新的韩语标记:从中间分词器中,我们识别出所有不在原始 SOLAR 分词器中的韩语标记。
- 手动构建分词器:然后,我们专注于这些新的韩语标记,构建目标分词器。
- 频率分析:使用目标分词器,我们处理了一个 100GB 的韩语语料库,统计每个标记的出现频率。
- 标记列表优化:我们移除了出现次数少于 6000 次的标记,确保为后续模型训练保留足够的标记。
- 单字符添加:统计缺失的韩语单字符,并将出现次数超过 6000 次的字符添加到目标分词器中。
- 迭代优化:我们重复步骤 2 到 6,直到没有需要删除或添加的标记。
- 新标记训练偏差:我们的训练数据偏向于包含更多带有新标记的文本,以实现有效学习。
这种严格的方法确保了模型拥有全面且上下文丰富的韩语词汇。
📄 许可证
本模型采用 Apache-2.0 许可证。
📚 引用
@misc{kim2024efficient,
title={Efficient and Effective Vocabulary Expansion Towards Multilingual Large Language Models},
author={Seungduk Kim and Seungtaek Choi and Myeongho Jeong},
year={2024},
eprint={2402.14714},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多种语言
Transformers 支持多种语言