🚀 hubert-base-ch-speech-emotion-recognition
本模型以 [TencentGameMate/chinese-hubert-base](TencentGameMate/chinese-hubert-base · Hugging Face) 作为预训练模型,在 CASIA 数据集上进行训练。CASIA 数据集提供了 1200 个由演员用中文演绎 6 种不同情感的录音样本(该数据集官网共提供 9600 条数据,我使用的数据集可能并不完整),这 6 种情感分别为:
emotions = ['anger', 'fear', 'happy', 'neutral', 'sad', 'surprise']
🚀 快速开始
模型使用
import os
import random
import librosa
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import AutoConfig, Wav2Vec2FeatureExtractor, HubertPreTrainedModel, HubertModel
model_name_or_path = "xmj2002/hubert-base-ch-speech-emotion-recognition"
duration = 6
sample_rate = 16000
config = AutoConfig.from_pretrained(
pretrained_model_name_or_path=model_name_or_path,
)
def id2class(id):
if id == 0:
return "angry"
elif id == 1:
return "fear"
elif id == 2:
return "happy"
elif id == 3:
return "neutral"
elif id == 4:
return "sad"
else:
return "surprise"
def predict(path, processor, model):
speech, sr = librosa.load(path=path, sr=sample_rate)
speech = processor(speech, padding="max_length", truncation=True, max_length=duration * sr,
return_tensors="pt", sampling_rate=sr).input_values
with torch.no_grad():
logit = model(speech)
score = F.softmax(logit, dim=1).detach().cpu().numpy()[0]
id = torch.argmax(logit).cpu().numpy()
print(f"file path: {path} \t predict: {id2class(id)} \t score:{score[id]} ")
class HubertClassificationHead(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.dropout = nn.Dropout(config.classifier_dropout)
self.out_proj = nn.Linear(config.hidden_size, config.num_class)
def forward(self, x):
x = self.dense(x)
x = torch.tanh(x)
x = self.dropout(x)
x = self.out_proj(x)
return x
class HubertForSpeechClassification(HubertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.hubert = HubertModel(config)
self.classifier = HubertClassificationHead(config)
self.init_weights()
def forward(self, x):
outputs = self.hubert(x)
hidden_states = outputs[0]
x = torch.mean(hidden_states, dim=1)
x = self.classifier(x)
return x
processor = Wav2Vec2FeatureExtractor.from_pretrained(model_name_or_path)
model = HubertForSpeechClassification.from_pretrained(
model_name_or_path,
config=config,
)
model.eval()
file_path = [f"test_data/{path}" for path in os.listdir("test_data")]
path = random.sample(file_path, 1)[0]
predict(path, processor, model)
训练设置
- 数据集分割比例:训练集 : 验证集 : 测试集 = 0.6 : 0.2 : 0.2
- 随机种子:34
- 批量大小:36
- 学习率:2e - 4
- 优化器:AdamW(betas=(0.93, 0.98), weight_decay=0.2)
- 调度器:Step_LR(step_size=10, gamma=0.3)
- 分类器丢弃率:0.1
- 优化器参数:
for name, param in model.named_parameters():
if "hubert" in name:
parameter.append({'params': param, 'lr': 0.2 * lr})
else:
parameter.append({'params': param, "lr": lr})
评估指标
- 测试集损失:0.1165
- 测试集准确率:0.972
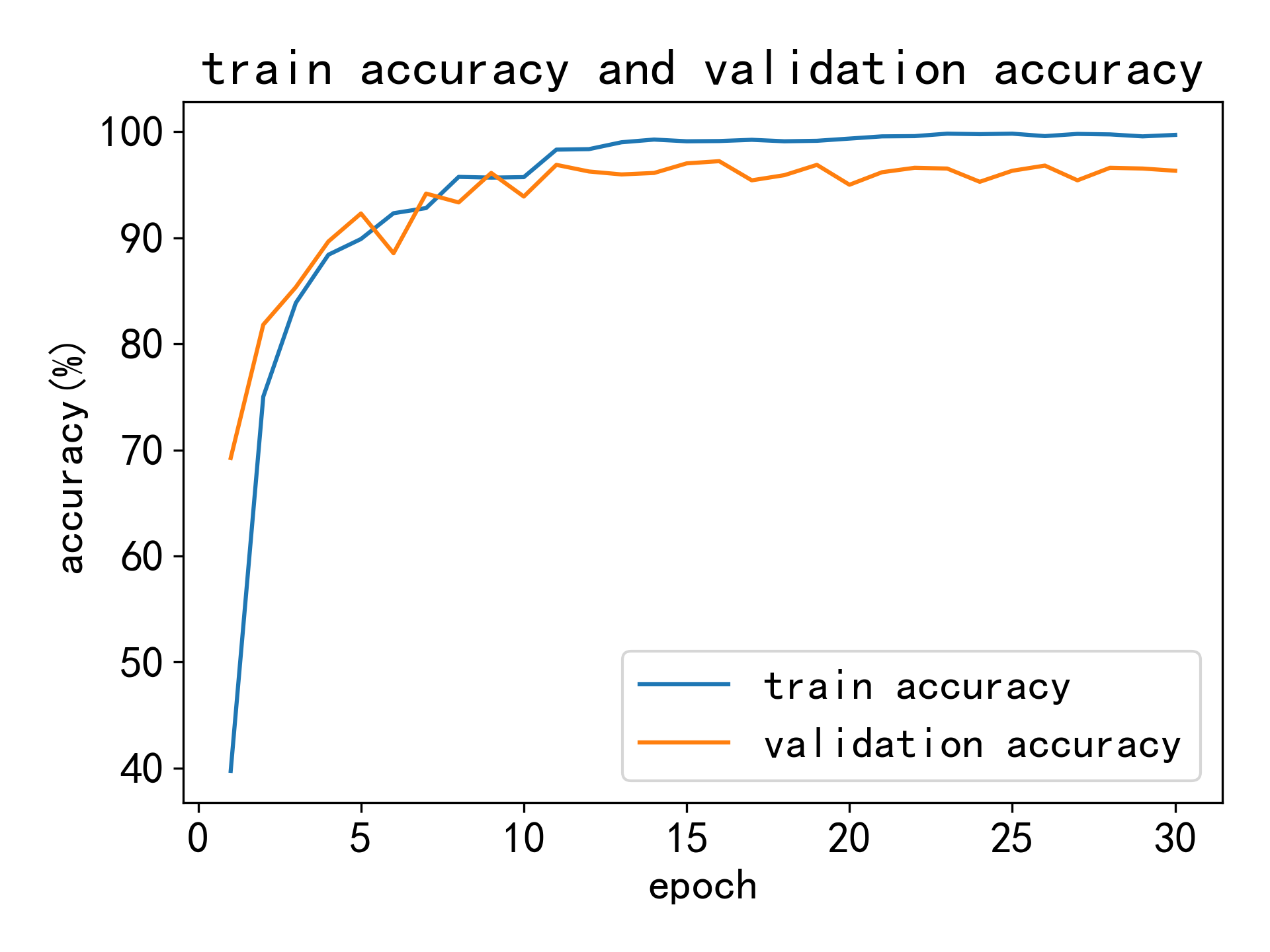
训练集和验证集准确率曲线
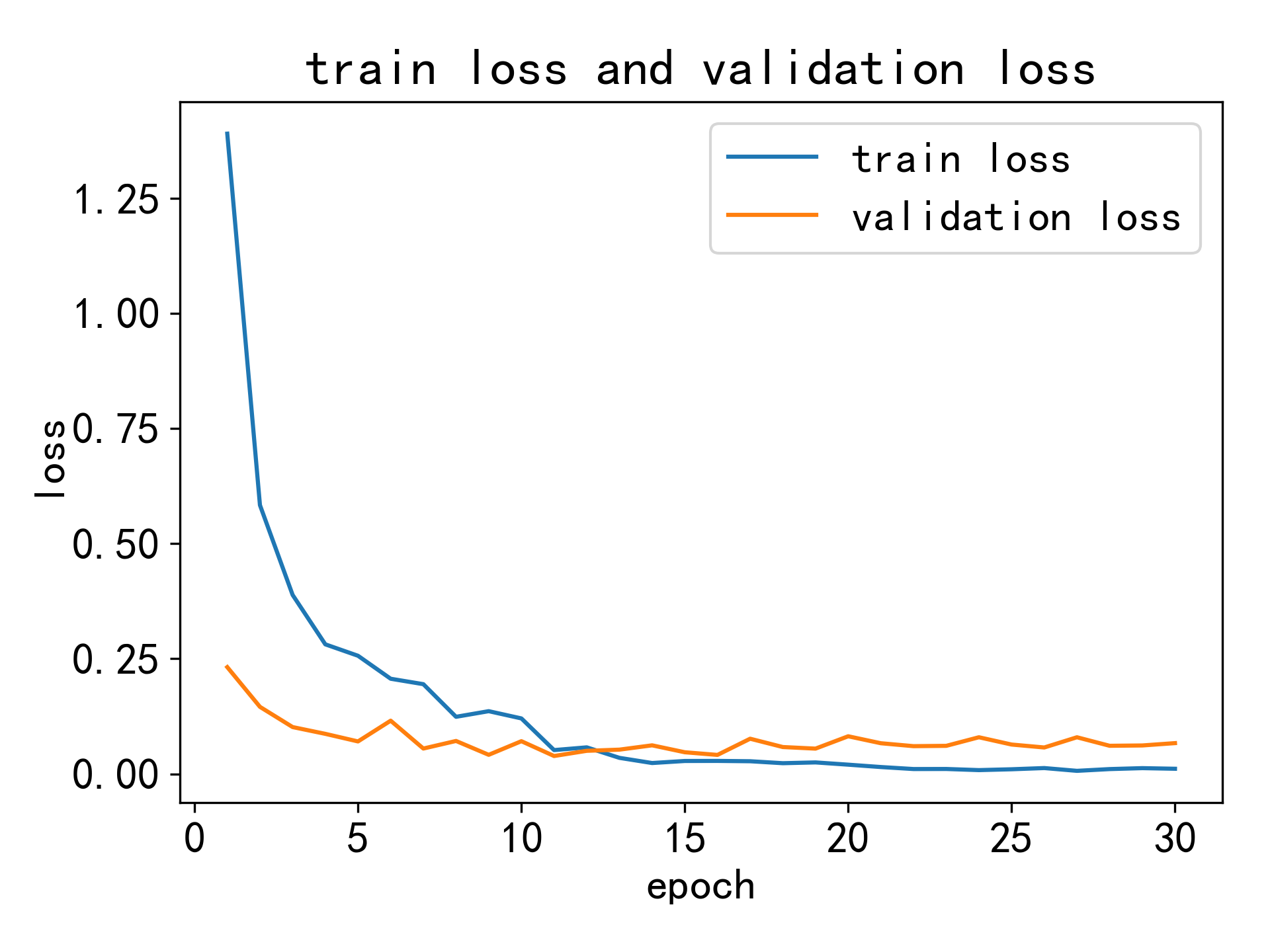
训练集和验证集损失曲线
📄 许可证
本项目采用 Apache - 2.0 许可证。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 PyTorch
PyTorch Transformers 支持多种语言
Transformers 支持多种语言