Perceiver AR 是对像 GPT - 2 这样的纯仅解码器 Transformer 的简单扩展。两者的核心构建块都是 解码器层,它由一个自注意力层和一个逐位置的多层感知机(MLP)组成。自注意力使用因果注意力掩码。
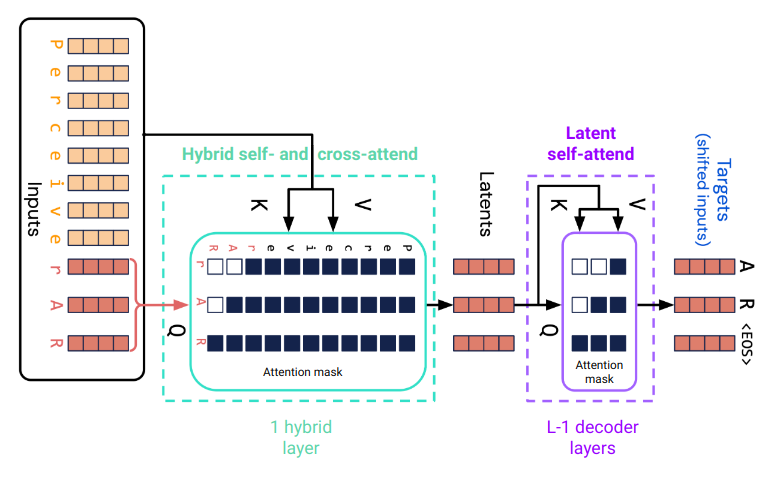
Perceiver AR 在其第一个注意力层中还会对输入序列的较长前缀进行交叉注意力操作。这一层是一个混合的自注意力和交叉注意力层。自注意力作用于输入序列的最后 n 个位置,并使用因果注意力掩码;交叉注意力从最后 n 个位置指向前 m 个位置。输入序列的长度为 m + n。这使得 Perceiver AR 能够处理比仅基于自注意力的解码器 Transformer 大得多的上下文。
图 1. Perceiver AR 中 m = 8 个前缀标记和 n = 3 个潜在标记的注意力机制。
混合注意力层的输出是与输入序列的最后 n 个标记相对应的 n 个潜在数组。这些数组会被一个由 L - 1 个解码器层组成的栈进一步处理,其中注意力层的总数为 L。最后一层(图 1 中未显示)会为每个潜在位置预测目标标记。最后一层的权重与输入嵌入层共享。除了对前缀序列的初始交叉注意力之外,Perceiver AR 在架构上与仅解码器的 Transformer 相同。
krasserm/perceiver - ar - sam - giant - midi 模型是从训练检查点创建的,代码如下:
from perceiver.model.audio.symbolic import convert_checkpoint
convert_checkpoint(
save_dir="krasserm/perceiver-ar-sam-giant-midi",
ckpt_url="https://martin-krasser.com/perceiver/logs-0.8.0/sam/version_1/checkpoints/epoch=027-val_loss=1.944.ckpt",
push_to_hub=True,
)
📄 许可证
本项目采用 Apache - 2.0 许可证。
📚 引用
@inproceedings{hawthorne2022general,
title={General-purpose, long-context autoregressive modeling with perceiver ar},
author={Hawthorne, Curtis and Jaegle, Andrew and Cangea, C{\u{a}}t{\u{a}}lina and Borgeaud, Sebastian and Nash, Charlie and Malinowski, Mateusz and Dieleman, Sander and Vinyals, Oriol and Botvinick, Matthew and Simon, Ian and others},
booktitle={International Conference on Machine Learning},
pages={8535--8558},
year={2022},
organization={PMLR}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多种语言
Transformers 支持多种语言