🚀 Perceiver AR シンボリックオーディオモデル
このモデルは、GiantMIDI-Piano データセットで27エポック(157Mトークン)学習された Perceiver AR シンボリックオーディオモデル(134Mパラメータ)です。相対位置エンコーディングに ロータリー埋め込み を使用しています。これは perceiver-io ライブラリの 学習例 です。
🚀 クイックスタート
このモデルを使用するには、まず perceiver-io ライブラリを拡張機能 audio とともに インストール する必要があります。
pip install perceiver-io[audio]
その後、モデルをPyTorchで使用できます。直接モデルを使用してMIDIファイルを生成するか、symbolic-audio-generation パイプラインを使用してMIDI出力を生成することができます。
✨ 主な機能
ユーザー定義の初期潜在トークン数でオーディオ生成が可能。
Perceiver ARモデルの学習方法を示すデモンストレーション用に主に存在。
📦 インストール
このモデルを使用するには、まず perceiver-io ライブラリを拡張機能 audio とともに インストール する必要があります。
pip install perceiver-io[audio]
💻 使用例
基本的な使用法
import torch
from perceiver.model.audio.symbolic import PerceiverSymbolicAudioModel
from perceiver.data.audio.midi_processor import decode_midi, encode_midi
from pretty_midi import PrettyMIDI
repo_id = "krasserm/perceiver-ar-sam-giant-midi"
model = PerceiverSymbolicAudioModel.from_pretrained(repo_id)
prompt_midi = PrettyMIDI("prompt.mid" )
prompt = torch.tensor(encode_midi(prompt_midi)).unsqueeze(0 )
output = model.generate(prompt, max_new_tokens=64 , num_latents=1 , do_sample=True , top_p=0.95 , temperature=1.0 )
output_midi = decode_midi(output[0 ].cpu().numpy())
type (output_midi)
pretty_midi.pretty_midi.PrettyMIDI
高度な使用法
from transformers import pipeline
from pretty_midi import PrettyMIDI
from perceiver.model.audio import symbolic
repo_id = "krasserm/perceiver-ar-sam-giant-midi"
prompt = PrettyMIDI("prompt.mid" )
audio_generator = pipeline("symbolic-audio-generation" , model=repo_id)
output = audio_generator(prompt, max_new_tokens=64 , num_latents=1 , do_sample=True , top_p=0.95 , temperature=1.0 )
type (output["generated_audio_midi" ])
pretty_midi.pretty_midi.PrettyMIDI
または、fluidsynth を使用してMIDIシンボルをレンダリングしてWAV出力を生成することもできます(注: 以下の例を動作させるにはfluidsynthをインストールする必要があります)。
from transformers import pipeline
from pretty_midi import PrettyMIDI
from perceiver.model.audio import symbolic
repo_id = "krasserm/perceiver-ar-sam-giant-midi"
prompt = PrettyMIDI("prompt.mid" )
audio_generator = pipeline("symbolic-audio-generation" , model=repo_id)
output = audio_generator(prompt, max_new_tokens=64 , num_latents=1 , do_sample=True , top_p=0.95 , temperature=1.0 , render=True )
with open ("generated_audio.wav" , "wb" ) as f:
f.write(output["generated_audio_wav" ])
📚 ドキュメント
モデルの説明
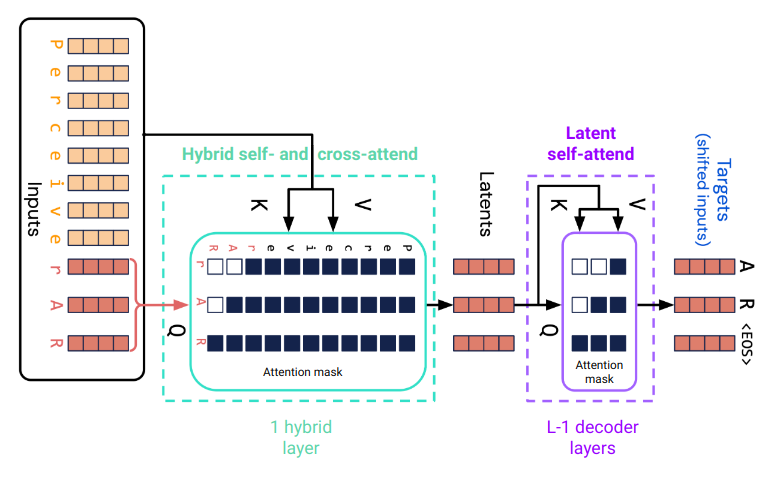
Perceiver ARは、例えばGPT - 2のような単純なデコーダー専用トランスフォーマーの単純な拡張です。両者の核心的な構成要素は、自己注意層とそれに続く位置ごとのMLPからなる デコーダー層 です。自己注意は因果的な注意マスクを使用します。
Perceiver ARは、最初の注意層で入力シーケンスの長いプレフィックスに対してクロス注意を行います。この層は、自己注意とクロス注意のハイブリッド層です。自己注意は入力シーケンスの最後のn位置に対して行われ、因果的な注意マスクが使用されます。クロス注意は最後のn位置から最初のm位置へ行われます。入力シーケンスの長さはm + nです。これにより、Perceiver ARは自己注意のみに基づくデコーダー専用トランスフォーマーよりもはるかに大きなコンテキストを処理することができます。
Fig. 1 . m = 8のプレフィックストークンとn = 3の潜在トークンを持つPerceiver ARの注意。
ハイブリッド注意層の出力は、入力シーケンスの最後のnトークンに対応するn個の潜在配列です。これらは、合計L個の注意層のうちL - 1個のデコーダー層のスタックによってさらに処理されます。最終層(Fig. 1には示されていません)は、各潜在位置のターゲットトークンを予測します。最終層の重みは入力埋め込み層と共有されます。プレフィックスシーケンスへの初期クロス注意を除いて、Perceiver ARはデコーダー専用トランスフォーマーと構造的に同じです。
モデルの学習
このモデルは GiantMIDI-Piano データセットでシンボリックオーディオモデリングのタスクを用いて 学習 されました。学習は27エポック(157Mトークン)行われました。このデータセットは MIDI ファイルから構成されており、Perceiver AR論文 のアプローチを用いてトークン化されています。このアプローチは Huang et al (2019) のセクションA.2で詳細に説明されています。
すべてのハイパーパラメータは 学習スクリプト でまとめられています。コンテキスト長は6144トークンに設定され、2048の潜在位置があり、最大プレフィックス長は4096になります。各例の実際のプレフィックス長は0から4096の間でランダムに選択されました。学習は PyTorch Lightning を使用して行われ、結果のチェックポイントはライブラリ固有の 変換ユーティリティ を使用してこの🤗モデルに変換されました。
想定される用途と制限
このモデルは、ユーザー定義の初期潜在トークン数でオーディオ生成に使用できます。主に perceiver-ioライブラリ でPerceiver ARモデルを学習する方法をデモンストレーションする目的で存在しています。生成されるオーディオサンプルの品質を向上させるには、GiantMIDI-Piano よりもはるかに大きなデータセットで学習する必要があります。
チェックポイントの変換
krasserm/perceiver-ar-sam-giant-midi モデルは、学習チェックポイントから次のように作成されました。
from perceiver.model.audio.symbolic import convert_checkpoint
convert_checkpoint(
save_dir="krasserm/perceiver-ar-sam-giant-midi" ,
ckpt_url="https://martin-krasser.com/perceiver/logs-0.8.0/sam/version_1/checkpoints/epoch=027-val_loss=1.944.ckpt" ,
push_to_hub=True ,
)
🔧 技術詳細
Perceiver ARは、GPT - 2などのデコーダー専用トランスフォーマーの拡張で、最初の注意層で入力シーケンスの長いプレフィックスに対してクロス注意を行うことで、大きなコンテキストを処理できます。相対位置エンコーディングにロータリー埋め込みを使用しています。学習はPyTorch Lightningを使用して行われ、チェックポイントは特定の変換ユーティリティを使用して🤗モデルに変換されました。
📄 ライセンス
このモデルはApache - 2.0ライセンスの下で提供されています。
オーディオサンプル
以下の(手動で選択された)オーディオサンプルは、GiantMIDI-Piano データセットの検証サブセットからの様々なプロンプトを使用して生成されました。入力プロンプトはオーディオ出力に含まれていません。
オーディオサンプル
Top - K
Top - p
温度
プレフィックス長
潜在トークン数
Your browser does not support the audio element. -
0.95
0.95
4096
1
Your browser does not support the audio element. -
0.95
1.0
4096
64
Your browser does not support the audio element. -
0.95
1.0
1024
1
Your browser does not support the audio element. 15
-
1.0
4096
16
Your browser does not support the audio element. -
0.95
1.0
4096
1
引用
@inproceedings{hawthorne2022general,
title={General-purpose, long-context autoregressive modeling with perceiver ar},
author={Hawthorne, Curtis and Jaegle, Andrew and Cangea, C{\u{a}}t{\u{a}}lina and Borgeaud, Sebastian and Nash, Charlie and Malinowski, Mateusz and Dieleman, Sander and Vinyals, Oriol and Botvinick, Matthew and Simon, Ian and others},
booktitle={International Conference on Machine Learning},
pages={8535--8558},
year={2022},
organization={PMLR}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応