🚀 Wav2Vec2-XLS-R-2B-EN-15
这是Facebook基于Wav2Vec2 XLS - R微调的用于语音翻译的模型,能将英语语音翻译成多种书面语言。
支持语言和数据集
| 属性 |
详情 |
| 支持语言 |
多语言,包括英语(en)、德语(de)、土耳其语(tr)、波斯语(fa)、瑞典语(sv)、蒙古语(mn)、中文(zh)、威尔士语(cy)、加泰罗尼亚语(ca)、斯洛文尼亚语(sl)、爱沙尼亚语(et)、印尼语(id)、阿拉伯语(ar)、泰米尔语(ta)、拉脱维亚语(lv)、日语(ja) |
| 数据集 |
common_voice、multilingual_librispeech、covost2 |
| 标签 |
speech、xls_r、automatic - speech - recognition、xls_r_translation |
| 任务类型 |
自动语音识别 |
| 许可证 |
apache - 2.0 |
模型架构

这是一个SpeechEncoderDecoderModel模型。编码器从facebook/wav2vec2-xls-r-2b检查点进行热启动,解码器从facebook/mbart-large-50检查点进行热启动。因此,该编码器 - 解码器模型在Covost2数据集的15个en -> {lang}翻译对上进行了微调。
该模型可以将英语口语翻译成以下书面语言{lang}:
en -> {de, tr, fa, sv - SE, mn, zh - CN, cy, ca, sl, et, id, ar, ta, lv, ja}
更多信息,请参考官方XLS - R论文的5.1.1节。
🚀 快速开始
演示
你可以在此空间测试该模型。你可以选择目标语言,录制一些英语音频,然后坐等检查点对输入的翻译效果。
示例
由于这是一个标准的序列到序列的Transformer模型,你可以使用generate方法,将语音特征传递给模型来生成转录内容。
你可以通过ASR管道直接使用该模型。默认情况下,检查点将把英语口语翻译成书面德语。要更改书面目标语言,你需要将正确的forced_bos_token_id传递给generate(...),以使解码器针对正确的目标语言进行条件设置。
要根据你选择的语言ID选择正确的forced_bos_token_id,请使用以下映射:
MAPPING = {
"de": 250003,
"tr": 250023,
"fa": 250029,
"sv": 250042,
"mn": 250037,
"zh": 250025,
"cy": 250007,
"ca": 250005,
"sl": 250052,
"et": 250006,
"id": 250032,
"ar": 250001,
"ta": 250044,
"lv": 250017,
"ja": 250012,
}
例如,如果你想翻译成瑞典语,可以这样做:
from datasets import load_dataset
from transformers import pipeline
forced_bos_token_id = MAPPING["sv"]
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-2b-en-to-15", feature_extractor="facebook/wav2vec2-xls-r-2b-en-to-15")
translation = asr(audio_file, forced_bos_token_id=forced_bos_token_id)
或者按以下步骤逐步操作:
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-2b-en-to-15")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-2b-en-to-15")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
forced_bos_token_id = MAPPING["sv"]
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"], forced_bos_token_id=forced_bos_token)
transcription = processor.batch_decode(generated_ids)
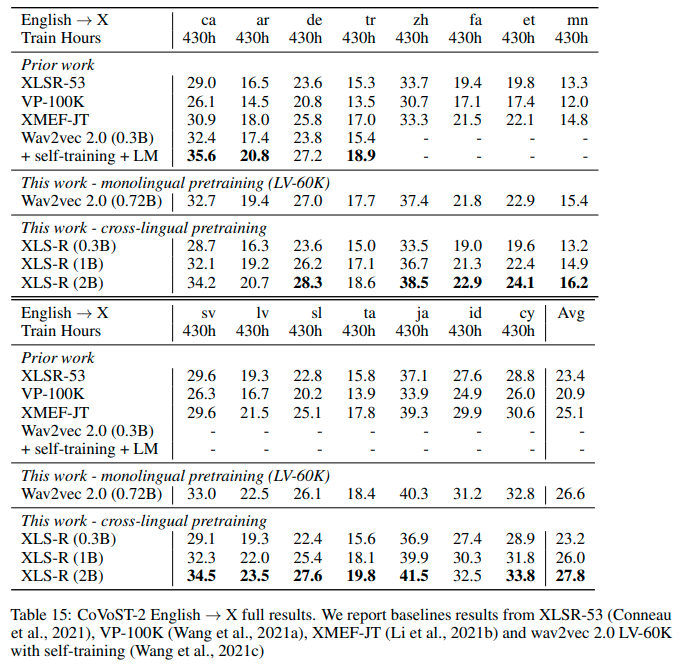
🔍 结果 en -> {lang}
查看此模型在Covost2上的性能,请参考**XLS - R (2B)**行。
更多用于{lang} -> en语音翻译的XLS - R模型
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多种语言
Transformers 支持多种语言