🚀 SpaceTimeGPT - 视频字幕生成模型
SpaceTimeGPT 是一个能够进行空间和时间推理的视频描述生成模型。它可以对输入的视频进行分析,并输出描述视频中事件的句子。
🔍 项目信息
| 属性 |
详情 |
| 数据集 |
HuggingFaceM4/vatex |
| 语言 |
英语 |
| 评估指标 |
BLEU、METEOR、ROUGE |
| 任务类型 |
视频文本到文本 |
| 推理功能 |
支持 |
| 标签 |
视频字幕生成 |
📊 模型评估结果
| 模型名称 |
任务类型 |
数据集 |
评估指标 |
值 |
验证状态 |
| Caelen |
视频字幕生成 |
VATEX |
CIDEr |
67.3 |
未验证 |
🚀 快速开始

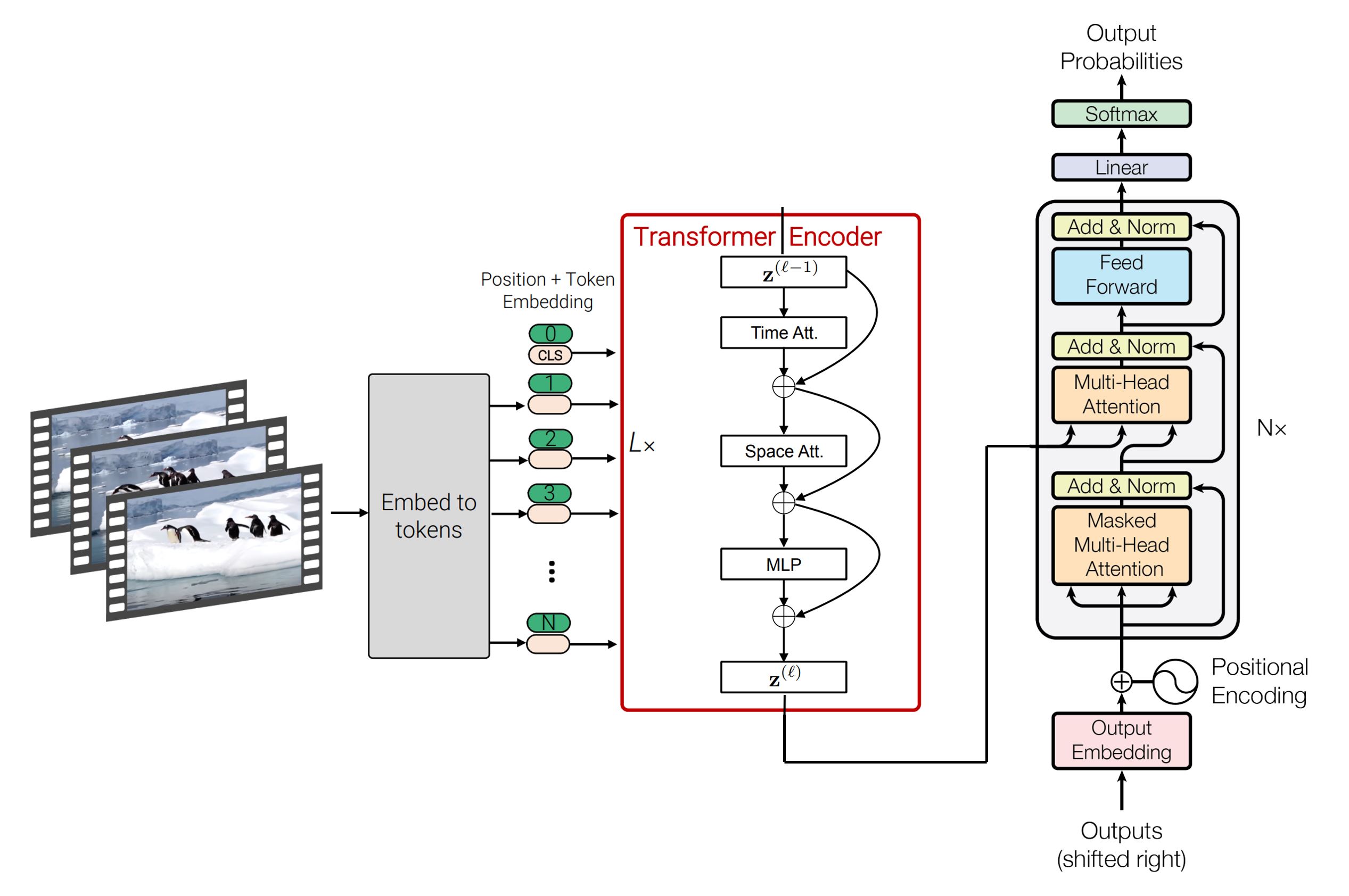
(部分图表来自 1, 2, 3)
SpaceTimeGPT 是一个能够进行空间和时间推理的视频描述生成模型。给定一个视频,模型会采样并分析八帧图像,然后通过自回归生成视频中所发生事件的句子描述。
🏗️ 架构与训练
编码器和解码器分别使用预训练的视频分类和句子补全权重进行初始化。通过编码器 - 解码器交叉注意力机制来统一视觉和语言领域。该模型在视频字幕生成任务上进行了端到端的微调。更多详细信息请参考 GitHub 仓库。
💻 使用示例
基础用法
import av
import numpy as np
import torch
from transformers import AutoImageProcessor, AutoTokenizer, VisionEncoderDecoderModel
device = "cuda" if torch.cuda.is_available() else "cpu"
image_processor = AutoImageProcessor.from_pretrained("MCG-NJU/videomae-base")
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = VisionEncoderDecoderModel.from_pretrained("Neleac/timesformer-gpt2-video-captioning").to(device)
video_path = "never_gonna_give_you_up.mp4"
container = av.open(video_path)
seg_len = container.streams.video[0].frames
clip_len = model.config.encoder.num_frames
indices = set(np.linspace(0, seg_len, num=clip_len, endpoint=False).astype(np.int64))
frames = []
container.seek(0)
for i, frame in enumerate(container.decode(video=0)):
if i in indices:
frames.append(frame.to_ndarray(format="rgb24"))
gen_kwargs = {
"min_length": 10,
"max_length": 20,
"num_beams": 8,
}
pixel_values = image_processor(frames, return_tensors="pt").pixel_values.to(device)
tokens = model.generate(pixel_values, **gen_kwargs)
caption = tokenizer.batch_decode(tokens, skip_special_tokens=True)[0]
print(caption)
🧑💻 作者信息
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 支持多种语言
Transformers 支持多种语言