🚀 SpaceTimeGPT - 視頻字幕生成模型
SpaceTimeGPT 是一個能夠進行空間和時間推理的視頻描述生成模型。它可以對輸入的視頻進行分析,並輸出描述視頻中事件的句子。
🔍 項目信息
| 屬性 |
詳情 |
| 數據集 |
HuggingFaceM4/vatex |
| 語言 |
英語 |
| 評估指標 |
BLEU、METEOR、ROUGE |
| 任務類型 |
視頻文本到文本 |
| 推理功能 |
支持 |
| 標籤 |
視頻字幕生成 |
📊 模型評估結果
| 模型名稱 |
任務類型 |
數據集 |
評估指標 |
值 |
驗證狀態 |
| Caelen |
視頻字幕生成 |
VATEX |
CIDEr |
67.3 |
未驗證 |
🚀 快速開始

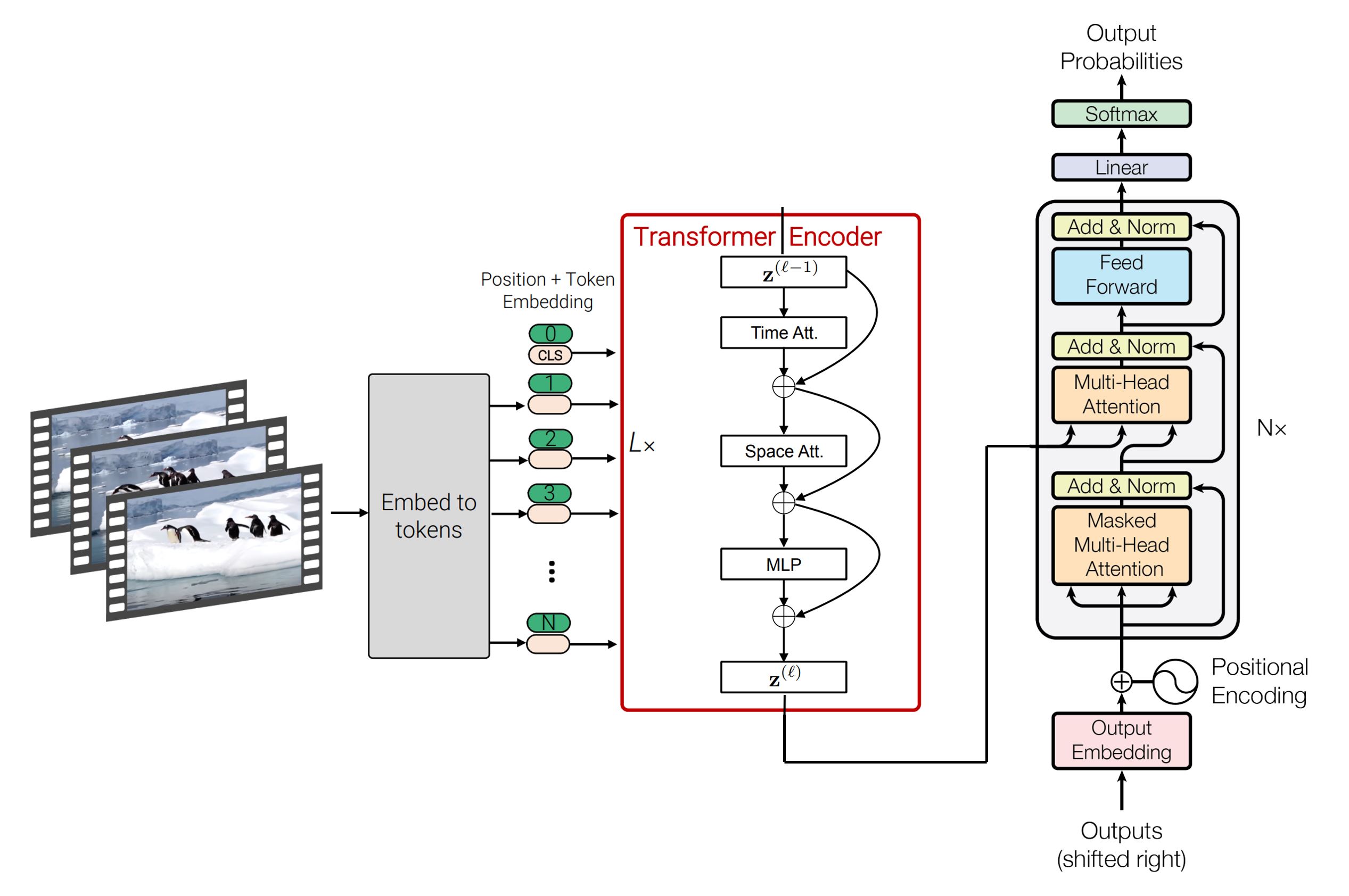
(部分圖表來自 1, 2, 3)
SpaceTimeGPT 是一個能夠進行空間和時間推理的視頻描述生成模型。給定一個視頻,模型會採樣並分析八幀圖像,然後通過自迴歸生成視頻中所發生事件的句子描述。
🏗️ 架構與訓練
編碼器和解碼器分別使用預訓練的視頻分類和句子補全權重進行初始化。通過編碼器 - 解碼器交叉注意力機制來統一視覺和語言領域。該模型在視頻字幕生成任務上進行了端到端的微調。更多詳細信息請參考 GitHub 倉庫。
💻 使用示例
基礎用法
import av
import numpy as np
import torch
from transformers import AutoImageProcessor, AutoTokenizer, VisionEncoderDecoderModel
device = "cuda" if torch.cuda.is_available() else "cpu"
image_processor = AutoImageProcessor.from_pretrained("MCG-NJU/videomae-base")
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = VisionEncoderDecoderModel.from_pretrained("Neleac/timesformer-gpt2-video-captioning").to(device)
video_path = "never_gonna_give_you_up.mp4"
container = av.open(video_path)
seg_len = container.streams.video[0].frames
clip_len = model.config.encoder.num_frames
indices = set(np.linspace(0, seg_len, num=clip_len, endpoint=False).astype(np.int64))
frames = []
container.seek(0)
for i, frame in enumerate(container.decode(video=0)):
if i in indices:
frames.append(frame.to_ndarray(format="rgb24"))
gen_kwargs = {
"min_length": 10,
"max_length": 20,
"num_beams": 8,
}
pixel_values = image_processor(frames, return_tensors="pt").pixel_values.to(device)
tokens = model.generate(pixel_values, **gen_kwargs)
caption = tokenizer.batch_decode(tokens, skip_special_tokens=True)[0]
print(caption)
🧑💻 作者信息
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 支持多種語言
Transformers 支持多種語言