🚀 CogVLM2-Video-Llama3-Chat
CogVLM2-Video-Llama3-Chat在多個視頻問答任務中表現卓越,能夠在一分鐘內實現視頻理解。本項目提供了示例視頻,展示其視頻理解和視頻時間定位能力。
🚀 快速開始
本倉庫提供的是chat版本模型,支持單輪對話。你可以在我們的 GitHub 上快速安裝Python包依賴並運行模型推理。
✨ 主要特性
- CogVLM2-Video在多個視頻問答任務中達到了先進水平。
- 能夠在一分鐘內實現視頻理解。
- 提供示例視頻,展示視頻理解和視頻時間定位能力。
📊 基準測試
性能圖表
下圖展示了CogVLM2-Video在 MVBench、VideoChatGPT-Bench 和零樣本視頻問答數據集(MSVD-QA、MSRVTT-QA、ActivityNet-QA)上的性能。其中,VCG-* 指的是VideoChatGPTBench,ZS-* 指的是零樣本視頻問答數據集,MV-* 指的是MVBench中的主要類別。
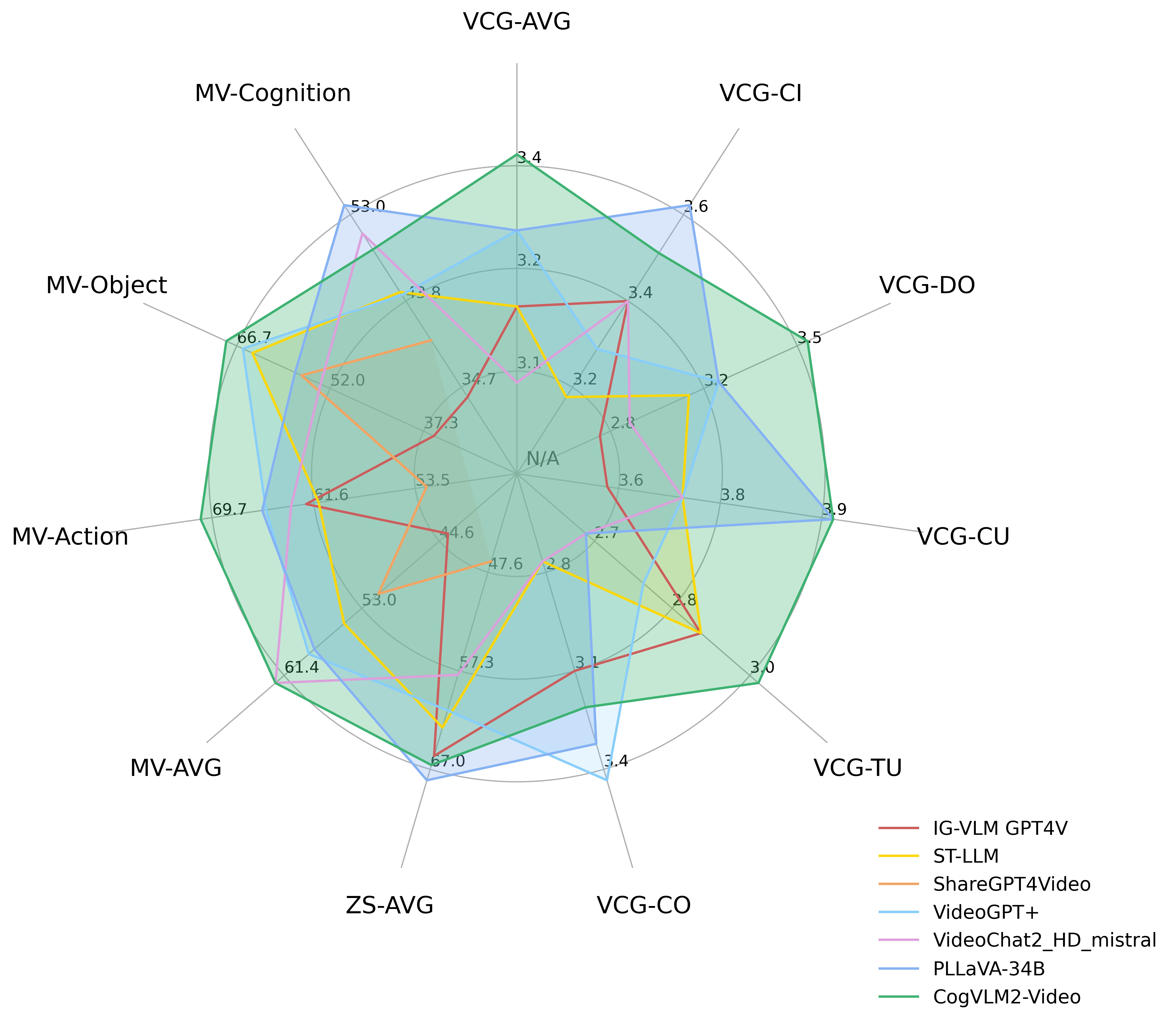
VideoChatGPT-Bench和零樣本視頻問答數據集性能
| 模型 |
VCG平均 |
VCG-CI |
VCG-DO |
VCG-CU |
VCG-TU |
VCG-CO |
ZS平均 |
| IG-VLM GPT4V |
3.17 |
3.40 |
2.80 |
3.61 |
2.89 |
3.13 |
65.70 |
| ST-LLM |
3.15 |
3.23 |
3.05 |
3.74 |
2.93 |
2.81 |
62.90 |
| ShareGPT4Video |
未提供 |
未提供 |
未提供 |
未提供 |
未提供 |
未提供 |
46.50 |
| VideoGPT+ |
3.28 |
3.27 |
3.18 |
3.74 |
2.83 |
3.39 |
61.20 |
| VideoChat2_HD_mistral |
3.10 |
3.40 |
2.91 |
3.72 |
2.65 |
2.84 |
57.70 |
| PLLaVA-34B |
3.32 |
3.60 |
3.20 |
3.90 |
2.67 |
3.25 |
68.10 |
| CogVLM2-Video |
3.41 |
3.49 |
3.46 |
3.87 |
2.98 |
3.23 |
66.60 |
MVBench數據集性能
| 模型 |
平均 |
AA |
AC |
AL |
AP |
AS |
CO |
CI |
EN |
ER |
FA |
FP |
MA |
MC |
MD |
OE |
OI |
OS |
ST |
SC |
UA |
| IG-VLM GPT4V |
43.7 |
72.0 |
39.0 |
40.5 |
63.5 |
55.5 |
52.0 |
11.0 |
31.0 |
59.0 |
46.5 |
47.5 |
22.5 |
12.0 |
12.0 |
18.5 |
59.0 |
29.5 |
83.5 |
45.0 |
73.5 |
| ST-LLM |
54.9 |
84.0 |
36.5 |
31.0 |
53.5 |
66.0 |
46.5 |
58.5 |
34.5 |
41.5 |
44.0 |
44.5 |
78.5 |
56.5 |
42.5 |
80.5 |
73.5 |
38.5 |
86.5 |
43.0 |
58.5 |
| ShareGPT4Video |
51.2 |
79.5 |
35.5 |
41.5 |
39.5 |
49.5 |
46.5 |
51.5 |
28.5 |
39.0 |
40.0 |
25.5 |
75.0 |
62.5 |
50.5 |
82.5 |
54.5 |
32.5 |
84.5 |
51.0 |
54.5 |
| VideoGPT+ |
58.7 |
83.0 |
39.5 |
34.0 |
60.0 |
69.0 |
50.0 |
60.0 |
29.5 |
44.0 |
48.5 |
53.0 |
90.5 |
71.0 |
44.0 |
85.5 |
75.5 |
36.0 |
89.5 |
45.0 |
66.5 |
| VideoChat2_HD_mistral |
62.3 |
79.5 |
60.0 |
87.5 |
50.0 |
68.5 |
93.5 |
71.5 |
36.5 |
45.0 |
49.5 |
87.0 |
40.0 |
76.0 |
92.0 |
53.0 |
62.0 |
45.5 |
36.0 |
44.0 |
69.5 |
| PLLaVA-34B |
58.1 |
82.0 |
40.5 |
49.5 |
53.0 |
67.5 |
66.5 |
59.0 |
39.5 |
63.5 |
47.0 |
50.0 |
70.0 |
43.0 |
37.5 |
68.5 |
67.5 |
36.5 |
91.0 |
51.5 |
79.0 |
| CogVLM2-Video |
62.3 |
85.5 |
41.5 |
31.5 |
65.5 |
79.5 |
58.5 |
77.0 |
28.5 |
42.5 |
54.0 |
57.0 |
91.5 |
73.0 |
48.0 |
91.0 |
78.0 |
36.0 |
91.5 |
47.0 |
68.5 |
💻 使用示例
基礎用法
prompt = f"Carefully watch the video and pay attention to the cause and sequence of events, the detail and movement of objects, and the action and pose of persons. Based on your observations, select the best option that accurately addresses the question.\n " + f"{prompt.replace('Short Answer.', '')}\n" + "Short Answer:"
prompt = f"Carefully watch the video and pay attention to the cause and sequence of events, the detail and movement of objects, and the action and pose of persons. Based on your observations, comprehensively answer the following question. Your answer should be long and cover all the related aspects\n " + f"{prompt.replace('Short Answer.', '')}\n" + "Answer:"
prompt = f"The input consists of a sequence of key frames from a video. Answer the question comprehensively including all the possible verbs and nouns that can discribe the events, followed by significant events, characters, or objects that appear throughout the frames.\n " + f"{prompt.replace('Short Answer.', '')}\n" + "Answer:"
評估代碼請參考PLLaVA中的 評估腳本。
📚 詳細文檔
評估細節
我們遵循以往的工作來評估模型的性能。在不同的基準測試中,我們為每個基準測試設計了特定任務的提示:
- MVBench:提示用戶仔細觀看視頻,注意事件的原因和順序、物體的細節和運動以及人物的動作和姿勢,然後根據觀察選擇最佳答案。
- VideoChatGPT-Bench:提示用戶仔細觀看視頻,全面回答問題,答案應涵蓋所有相關方面。
- 零樣本視頻問答:提示用戶根據輸入的視頻關鍵幀序列,全面回答問題,包括所有可能描述事件的動詞和名詞,以及整個幀中出現的重要事件、人物或物體。
訓練細節
訓練公式和超參數請參考我們的技術報告。
📄 許可證
本模型根據CogVLM2 許可證 發佈。對於基於Meta Llama 3構建的模型,請同時遵守 LLAMA3許可證。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多種語言
Transformers 支持多種語言