🚀 CogVLM2-Video-Llama3-Chat
CogVLM2-Videoは、複数のビデオ質問応答タスクで最先端の性能を達成します。1分以内でビデオ理解が可能です。
🚀 クイックスタート
CogVLM2-Videoは、複数のビデオ質問応答タスクで最先端の性能を達成します。1分以内でビデオ理解を行うことができます。ここでは、CogVLM2-Videoのビデオ理解とビデオ時間的接地能力を示す2つのサンプルビデオを提供しています。
✨ 主な機能
ベンチマーク
次の図は、CogVLM2-VideoがMVBench、VideoChatGPT-Bench、ゼロショットビデオQAデータセット(MSVD-QA、MSRVTT-QA、ActivityNet-QA)での性能を示しています。ここで、VCG-*はVideoChatGPTBenchを、ZS-*はゼロショットビデオQAデータセットを、MV-*はMVBenchの主要カテゴリを指します。
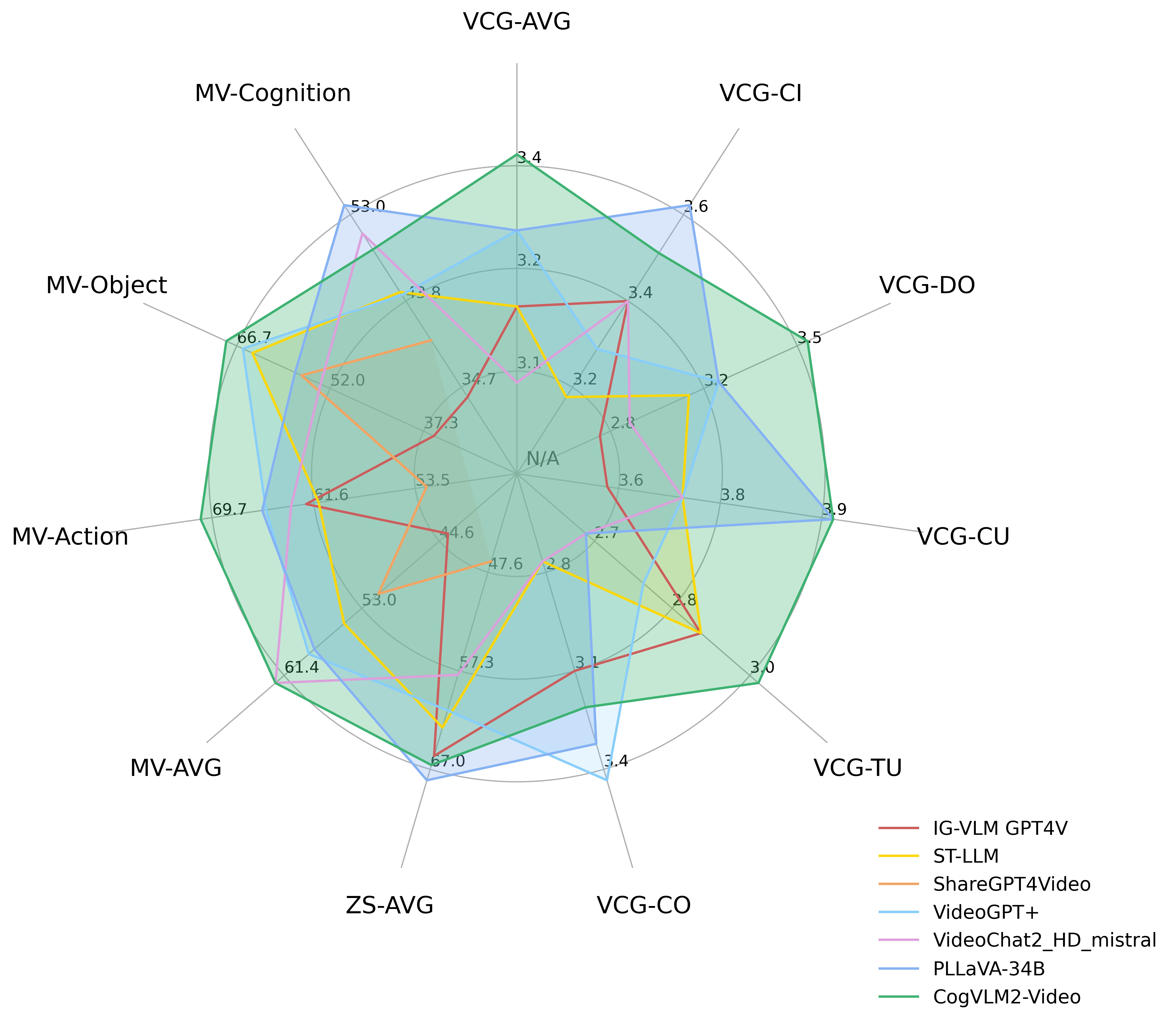
VideoChatGPT-BenchとゼロショットビデオQAデータセットでの性能
| モデル |
VCG-AVG |
VCG-CI |
VCG-DO |
VCG-CU |
VCG-TU |
VCG-CO |
ZS-AVG |
| IG-VLM GPT4V |
3.17 |
3.40 |
2.80 |
3.61 |
2.89 |
3.13 |
65.70 |
| ST-LLM |
3.15 |
3.23 |
3.05 |
3.74 |
2.93 |
2.81 |
62.90 |
| ShareGPT4Video |
N/A |
N/A |
N/A |
N/A |
N/A |
N/A |
46.50 |
| VideoGPT+ |
3.28 |
3.27 |
3.18 |
3.74 |
2.83 |
3.39 |
61.20 |
| VideoChat2_HD_mistral |
3.10 |
3.40 |
2.91 |
3.72 |
2.65 |
2.84 |
57.70 |
| PLLaVA-34B |
3.32 |
3.60 |
3.20 |
3.90 |
2.67 |
3.25 |
68.10 |
| CogVLM2-Video |
3.41 |
3.49 |
3.46 |
3.87 |
2.98 |
3.23 |
66.60 |
MVBenchデータセットでの性能
| モデル |
AVG |
AA |
AC |
AL |
AP |
AS |
CO |
CI |
EN |
ER |
FA |
FP |
MA |
MC |
MD |
OE |
OI |
OS |
ST |
SC |
UA |
| IG-VLM GPT4V |
43.7 |
72.0 |
39.0 |
40.5 |
63.5 |
55.5 |
52.0 |
11.0 |
31.0 |
59.0 |
46.5 |
47.5 |
22.5 |
12.0 |
12.0 |
18.5 |
59.0 |
29.5 |
83.5 |
45.0 |
73.5 |
| ST-LLM |
54.9 |
84.0 |
36.5 |
31.0 |
53.5 |
66.0 |
46.5 |
58.5 |
34.5 |
41.5 |
44.0 |
44.5 |
78.5 |
56.5 |
42.5 |
80.5 |
73.5 |
38.5 |
86.5 |
43.0 |
58.5 |
| ShareGPT4Video |
51.2 |
79.5 |
35.5 |
41.5 |
39.5 |
49.5 |
46.5 |
51.5 |
28.5 |
39.0 |
40.0 |
25.5 |
75.0 |
62.5 |
50.5 |
82.5 |
54.5 |
32.5 |
84.5 |
51.0 |
54.5 |
| VideoGPT+ |
58.7 |
83.0 |
39.5 |
34.0 |
60.0 |
69.0 |
50.0 |
60.0 |
29.5 |
44.0 |
48.5 |
53.0 |
90.5 |
71.0 |
44.0 |
85.5 |
75.5 |
36.0 |
89.5 |
45.0 |
66.5 |
| VideoChat2_HD_mistral |
62.3 |
79.5 |
60.0 |
87.5 |
50.0 |
68.5 |
93.5 |
71.5 |
36.5 |
45.0 |
49.5 |
87.0 |
40.0 |
76.0 |
92.0 |
53.0 |
62.0 |
45.5 |
36.0 |
44.0 |
69.5 |
| PLLaVA-34B |
58.1 |
82.0 |
40.5 |
49.5 |
53.0 |
67.5 |
66.5 |
59.0 |
39.5 |
63.5 |
47.0 |
50.0 |
70.0 |
43.0 |
37.5 |
68.5 |
67.5 |
36.5 |
91.0 |
51.5 |
79.0 |
| CogVLM2-Video |
62.3 |
85.5 |
41.5 |
31.5 |
65.5 |
79.5 |
58.5 |
77.0 |
28.5 |
42.5 |
54.0 |
57.0 |
91.5 |
73.0 |
48.0 |
91.0 |
78.0 |
36.0 |
91.5 |
47.0 |
68.5 |
評価詳細
以前の研究に従って、モデルの性能を評価しています。異なるベンチマークでは、各ベンチマークに対してタスク固有のプロンプトを作成しています。
prompt = f"Carefully watch the video and pay attention to the cause and sequence of events, the detail and movement of objects, and the action and pose of persons. Based on your observations, select the best option that accurately addresses the question.\n " + f"{prompt.replace('Short Answer.', '')}\n" + "Short Answer:"
prompt = f"Carefully watch the video and pay attention to the cause and sequence of events, the detail and movement of objects, and the action and pose of persons. Based on your observations, comprehensively answer the following question. Your answer should be long and cover all the related aspects\n " + f"{prompt.replace('Short Answer.', '')}\n" + "Answer:"
prompt = f"The input consists of a sequence of key frames from a video. Answer the question comprehensively including all the possible verbs and nouns that can discribe the events, followed by significant events, characters, or objects that appear throughout the frames.\n " + f"{prompt.replace('Short Answer.', '')}\n" + "Answer:"
評価コードについては、PLLaVAの評価スクリプトを参照してください。
このモデルの使用方法
このリポジトリはchatバージョンのモデルで、単ラウンドチャットをサポートしています。
githubでPythonパッケージの依存関係をすばやくインストールし、モデル推論を実行することができます。
📄 ライセンス
このモデルはCogVLM2 LICENSEの下で公開されています。Meta Llama 3を使用して構築されたモデルの場合は、LLAMA3_LICENSEにも準拠してください。
トレーニング詳細
トレーニングの公式とハイパーパラメータについては、技術レポートを参照してください。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応