%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

模型概述
模型特點
模型能力
使用案例
🚀 Jais系列模型介紹
Jais系列模型是一套全面的英阿雙語大語言模型(LLM)。這些模型在優化阿拉伯語性能的同時,也具備出色的英語處理能力。我們發佈了兩種基礎模型變體,包括:
- 從頭開始預訓練的模型(
jais-family-*)。 - 基於Llama - 2進行自適應預訓練的模型(
jais-adapted-*)。
在本次發佈中,我們推出了涵蓋8種規模、共計20個模型,參數範圍從5.9億到700億,使用多達16萬億阿拉伯語、英語和代碼數據的標記進行訓練。該系列的所有預訓練模型都使用精心策劃的阿拉伯語和英語指令數據進行了指令微調(*-chat),以用於對話。
我們希望這次廣泛的發佈能夠加速阿拉伯語自然語言處理(NLP)的研究,併為阿拉伯語使用者和雙語社區帶來眾多下游應用。我們為阿拉伯語模型成功展示的訓練和自適應技術,也可擴展到其他中低資源語言。
✨ 主要特性
- 雙語能力:在英語和阿拉伯語上都有出色的表現,尤其針對阿拉伯語進行了優化。
- 多種模型變體:提供從頭預訓練和基於Llama - 2自適應預訓練的模型,滿足不同需求。
- 廣泛的模型規模:從5.9億到700億參數,涵蓋多種計算資源和應用場景。
- 指令微調:所有模型都經過指令微調,適用於對話場景。
📦 安裝指南
文檔未提及具體安裝步驟,此處跳過。
💻 使用示例
基礎用法
# -*- coding: utf-8 -*-
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_path = "inceptionai/jais-family-13b"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto", trust_remote_code=True)
def get_response(text, tokenizer=tokenizer, model=model):
input_ids = tokenizer(text, return_tensors="pt").input_ids
inputs = input_ids.to(device)
input_len = inputs.shape[-1]
generate_ids = model.generate(
inputs,
top_p=0.9,
temperature=0.3,
max_length=2048,
min_length=input_len + 4,
repetition_penalty=1.2,
do_sample=True,
)
response = tokenizer.batch_decode(
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
)[0]
return response
text = "عاصمة دولة الإمارات العربية المتحدة ه"
print(get_response(text))
text = "The capital of UAE is"
print(get_response(text))
📚 詳細文檔
Jais系列模型詳情
| 屬性 | 詳情 |
|---|---|
| 開發者 | Inception, Cerebras Systems |
| 語言 | 阿拉伯語(現代標準阿拉伯語)和英語 |
| 輸入 | 僅文本數據 |
| 輸出 | 模型生成文本 |
| 模型規模 | 5.9億、13億、27億、67億、70億、130億、300億、700億 |
| 演示 | 點擊此處訪問即時演示 |
| 許可證 | Apache 2.0 |
預訓練模型
| 預訓練模型 | 微調模型 | 規模(參數) | 上下文長度(標記) |
|---|---|---|---|
| jais-family-30b-16k | Jais-family-30b-16k-chat | 300億 | 16384 |
| jais-family-30b-8k | Jais-family-30b-8k-chat | 300億 | 8192 |
| jais-family-13b | Jais-family-13b-chat | 130億 | 2048 |
| jais-family-6p7b | Jais-family-6p7b-chat | 67億 | 2048 |
| jais-family-2p7b | Jais-family-2p7b-chat | 27億 | 2048 |
| jais-family-1p3b | Jais-family-1p3b-chat | 13億 | 2048 |
| jais-family-590m | Jais-family-590m-chat | 5.9億 | 2048 |
自適應預訓練模型
| 自適應預訓練模型 | 微調模型 | 規模(參數) | 上下文長度(標記) |
|---|---|---|---|
| jais-adapted-70b | Jais-adapted-70b-chat | 700億 | 4096 |
| jais-adapted-13b | Jais-adapted-13b-chat | 130億 | 4096 |
| jais-adapted-7b | Jais-adapted-7b-chat | 70億 | 4096 |
模型架構
本系列的所有模型都是自迴歸語言模型,採用基於Transformer的僅解碼器架構(GPT - 3)。
Jais模型(jais-family-*)是從頭開始訓練的,採用了SwiGLU非線性激活函數和ALiBi位置編碼。這些架構改進使模型能夠在長序列長度上進行外推,從而提高上下文處理能力和精度。
Jais自適應模型(jais-adapted-*)是基於Llama - 2構建的,它採用了旋轉位置編碼(RoPE)和分組查詢注意力(Grouped Query Attention)。我們引入了使用阿拉伯語數據的分詞器擴展,將計算效率提高了3倍以上。具體來說,我們將Jais - 30b詞彙表中的32000個新阿拉伯語標記添加到Llama - 2分詞器中。為了初始化這些新的阿拉伯語標記嵌入,我們首先使用兩個詞彙表中共享的英語標記集,學習從Jais - 30b嵌入空間到Llama嵌入空間的線性投影。然後,將這個學習到的投影應用於將現有的Jais - 30b阿拉伯語嵌入轉換為Llama - 2嵌入空間。
訓練詳情
預訓練數據
Jais系列模型使用多達16萬億不同的英語、阿拉伯語和代碼數據標記進行訓練。數據來源包括:
- 網絡:我們使用了公開可用的網頁、維基百科文章、新聞文章和阿拉伯語及英語的社交網絡內容。
- 代碼:為了增強模型的推理能力,我們納入了各種編程語言的代碼數據。
- 書籍:我們使用了一些公開可用的阿拉伯語和英語書籍數據,這有助於改善長距離上下文建模和連貫的故事講述。
- 科學文獻:納入了一部分arXiv論文,以提高推理和長上下文處理能力。
- 合成數據:我們使用內部機器翻譯系統將英語翻譯成阿拉伯語,以增加阿拉伯語數據的數量。我們僅對高質量的英語資源(如英語維基百科和英語書籍)進行此操作。
我們對訓練數據進行了廣泛的預處理和去重。對於阿拉伯語,我們使用了自定義的預處理管道來過濾高質量的語言數據。有關此管道的更多信息,請參閱Jais論文。
- Jais預訓練模型(
jais-family-*):根據我們之前在Jais中進行的語言對齊混合實驗,我們使用了1:2:0.4的阿拉伯語:英語:代碼數據比例。這種從頭開始預訓練的方法解決了阿拉伯語數據稀缺的問題,同時提高了兩種語言的性能。 - Jais自適應預訓練模型(
jais-adapted-*):對於基於Llama - 2的自適應預訓練,我們使用了約3340億阿拉伯語標記的更大阿拉伯語數據集,並與英語和代碼數據混合。我們根據不同的模型規模調整混合比例,以在保持英語性能的同時引入強大的阿拉伯語能力。
| 預訓練模型 | 英語數據(標記) | 阿拉伯語數據(標記) | 代碼數據(標記) | 總數據(標記) |
|---|---|---|---|---|
| jais-family-30b-16k | 9800億 | 4900億 | 1960億 | 16.66萬億 |
| jais-family-30b-8k | 8820億 | 4410億 | 1770億 | 15萬億 |
| jais-family-13b | 2830億 | 1410億 | 560億 | 4.8萬億 |
| jais-family-6p7b | 2830億 | 1410億 | 560億 | 4.8萬億 |
| jais-family-2p7b | 2830億 | 1410億 | 560億 | 4.8萬億 |
| jais-family-1p3b | 2830億 | 1410億 | 560億 | 4.8萬億 |
| jais-family-590m | 2830億 | 1410億 | 560億 | 4.8萬億 |
| jais-adapted-70b | 330億 | 3340億 | 40億 | 3.71萬億 |
| jais-adapted-13b | 1270億 | 1400億 | 130億 | 2.8萬億 |
| jais-adapted-7b | 180億 | 190億 | 20億 | 3900億 |
微調數據
Jais系列的所有聊天模型都使用單輪和多輪設置下的阿拉伯語和英語提示 - 響應數據對進行微調。數據來源包括經過篩選的開源微調數據集,以確保主題和風格的多樣性。此外,還納入了內部精心策劃的人工數據,以增強文化適應性。這些數據還補充了使用合成方法(包括機器翻譯、蒸餾和模型自對話)生成的內容。總體而言,我們更新的指令微調數據集分別包含約1000萬和400萬英語和阿拉伯語的提示 - 響應數據對。
訓練過程
- 預訓練(
jais-family-*模型):在預訓練過程中,文檔被打包成由EOS標記分隔的序列,模型進行自迴歸訓練,並將損失應用於所有標記。對於jais - 30b模型,通過在訓練中納入精心策劃的長上下文文檔,上下文長度從2k逐步擴展到8K再到16K。這種漸進式擴展利用了較短上下文長度下更快的初始訓練速度,同時在訓練過程的後期逐漸擴展對更大上下文長度的支持。 - 自適應預訓練(
jais-adapted-*模型):在自適應預訓練中,我們首先按照模型架構中所述初始化新的分詞器和阿拉伯語嵌入。在訓練中,我們採用了兩階段方法來克服新阿拉伯語嵌入中觀察到的較高範數問題。在第一階段,模型的主幹被凍結,使用來自英語和阿拉伯語雙語語料庫的約150億標記訓練嵌入。在第二階段,主幹解凍,並對所有參數進行連續預訓練。 - 指令微調:每個訓練示例由單輪或多輪提示及其響應組成。與每個序列一個示例不同,示例被打包在一起,同時在提示標記上屏蔽損失。這種方法通過允許每批處理更多示例來加速訓練。
訓練超參數:Jais - family - 13b
| 超參數 | 值 |
|---|---|
| 精度 | fp32 |
| 優化器 | AdamW |
| 學習率 | 0到0.01563(<=95個熱身步驟) 0.01563到0.00085(>95且<=122162個步驟) |
| 權重衰減 | 0.1 |
| 批量大小 | 1920 |
| 上下文長度 | 2048 |
| 步數 | 122162 |
計算基礎設施
訓練過程在Condor Galaxy(CG)超級計算機平臺上進行。一個CG包含64個Cerebras CS - 2晶圓級引擎(WSE - 2),每個引擎具有40GB的SRAM,總計算能力達到960 PetaFLOP/s。
評估
我們使用LM - harness在零樣本設置下對Jais模型進行了全面評估,重點關注英語和阿拉伯語。評估標準涵蓋多個維度,包括:
- 知識:模型回答事實性問題的能力。
- 推理:模型回答需要推理的問題的能力。
- 錯誤信息/偏差:評估模型生成虛假或誤導性信息的傾向以及其中立性。
阿拉伯語評估結果
| 模型 | 平均得分 | ArabicMMLU* | MMLU | EXAMS* | LitQA* | agqa | agrc | Hellaswag | PIQA | BoolQA | Situated QA | ARC - C | OpenBookQA | TruthfulQA | CrowS - Pairs |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| jais - family - 30b - 16k | 49.2 | 44.0 | 33.4 | 40.9 | 60 | 47.8 | 49.3 | 60.9 | 68.6 | 70.3 | 41.6 | 38.7 | 31.8 | 45.2 | 57 |
| jais - family - 30b - 8k | 49.7 | 46.0 | 34 | 42 | 60.6 | 47.6 | 50.4 | 60.4 | 69 | 67.7 | 42.2 | 39.2 | 33.8 | 45.1 | 57.3 |
| jais - family - 13b | 46.1 | 34.0 | 30.3 | 42.7 | 58.3 | 40.5 | 45.5 | 57.3 | 68.1 | 63.1 | 41.6 | 35.3 | 31.4 | 41 | 56.1 |
| jais - family - 6p7b | 44.6 | 32.2 | 29.9 | 39 | 50.3 | 39.2 | 44.1 | 54.3 | 66.8 | 66.5 | 40.9 | 33.5 | 30.4 | 41.2 | 55.4 |
| jais - family - 2p7b | 41.0 | 29.5 | 28.5 | 36.1 | 45.7 | 32.4 | 40.8 | 44.2 | 62.5 | 62.2 | 39.2 | 27.4 | 28.2 | 43.6 | 53.6 |
| jais - family - 1p3b | 40.8 | 28.9 | 28.5 | 34.2 | 45.7 | 32.4 | 40.8 | 44.2 | 62.5 | 62.2 | 39.2 | 27.4 | 28.2 | 43.6 | 53.6 |
| jais - family - 590m | 39.7 | 31.2 | 27 | 33.1 | 41.7 | 33.8 | 38.8 | 38.2 | 60.7 | 62.2 | 37.9 | 25.5 | 27.4 | 44.7 | 53.3 |
| jais - family - 30b - 16k - chat | 51.6 | 59.9 | 34.6 | 40.2 | 58.9 | 46.8 | 54.7 | 56.2 | 64.4 | 76.7 | 55.9 | 40.8 | 30.8 | 49.5 | 52.9 |
| jais - family - 30b - 8k - chat | 51.4 | 61.2 | 34.2 | 40.2 | 54.3 | 47.3 | 53.6 | 60 | 63.4 | 76.8 | 54.7 | 39.5 | 30 | 50.7 | 54.3 |
| jais - family - 13b - chat | 50.3 | 58.2 | 33.9 | 42.9 | 53.1 | 46.8 | 51.7 | 59.3 | 65.4 | 75.2 | 51.2 | 38.4 | 29.8 | 44.8 | 53.8 |
| jais - family - 6p7b - chat | 48.7 | 55.7 | 32.8 | 37.7 | 49.7 | 40.5 | 50.1 | 56.2 | 62.9 | 79.4 | 52 | 38 | 30.4 | 44.7 | 52 |
| jais - family - 2p7b - chat | 45.6 | 50.0 | 31.5 | 35.9 | 41.1 | 37.3 | 42.1 | 48.6 | 63.7 | 74.4 | 50.9 | 35.3 | 31.2 | 44.5 | 51.3 |
| jais - family - 1p3b - chat | 42.7 | 42.2 | 30.1 | 33.6 | 40.6 | 34.1 | 41.2 | 43 | 63.6 | 69.3 | 44.9 | 31.6 | 28 | 45.6 | 50.4 |
| jais - family - 590m - chat | 37.8 | 39.1 | 28 | 29.5 | 33.1 | 30.8 | 36.4 | 30.3 | 57.8 | 57.2 | 40.5 | 25.9 | 26.8 | 44.5 | 49.3 |
| 自適應模型 | 平均得分 | ArabicMMLU* | MMLU | EXAMS* | LitQA* | agqa | agrc | Hellaswag | PIQA | BoolQA | Situated QA | ARC - C | OpenBookQA | TruthfulQA | CrowS - Pairs |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| jais - adapted - 70b | 51.5 | 55.9 | 36.8 | 42.3 | 58.3 | 48.6 | 54 | 61.5 | 68.4 | 68.4 | 42.1 | 42.6 | 33 | 50.2 | 58.3 |
| jais - adapted - 13b | 46.6 | 44.7 | 30.6 | 37.7 | 54.3 | 43.8 | 48.3 | 54.9 | 67.1 | 64.5 | 40.6 | 36.1 | 32 | 43.6 | 54.00 |
| jais - adapted - 7b | 42.0 | 35.9 | 28.9 | 36.7 | 46.3 | 34.1 | 40.3 | 45 | 61.3 | 63.8 | 38.1 | 29.7 | 30.2 | 44.3 | 53.6 |
| jais - adapted - 70b - chat | 52.9 | 66.8 | 34.6 | 42.5 | 62.9 | 36.8 | 48.6 | 64.5 | 69.7 | 82.8 | 49.3 | 44.2 | 32.2 | 53.3 | 52.4 |
| jais - adapted - 13b - chat | 50.3 | 59.0 | 31.7 | 37.5 | 56.6 | 41.9 | 51.7 | 58.8 | 67.1 | 78.2 | 45.9 | 41 | 34.2 | 48.3 | 52.1 |
| jais - adapted - 7b - chat | 46.1 | 51.3 | 30 | 37 | 48 | 36.8 | 48.6 | 51.1 | 62.9 | 72.4 | 41.3 | 34.6 | 30.4 | 48.6 | 51.8 |
阿拉伯語基準測試使用內部機器翻譯模型進行翻譯,並由阿拉伯語語言學家審核。帶有星號(*)的基準測試是原生阿拉伯語測試;有關更多詳細信息,請參閱Jais論文。此外,我們還納入了ArabicMMLU,這是一個基於地區知識的原生阿拉伯語基準測試。
英語評估結果
| 模型 | 平均得分 | MMLU | RACE | Hellaswag | PIQA | BoolQA | SIQA | ARC - Challenge | OpenBookQA | Winogrande | TruthfulQA | CrowS - Pairs |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| jais - family - 30b - 16k | 59.3 | 42.2 | 40.5 | 79.7 | 80.6 | 78.7 | 48.8 | 50.3 | 44.2 | 71.6 | 43.5 | 72.6 |
| jais - family - 30b - 8k | 58.8 | 42.3 | 40.3 | 79.1 | 80.5 | 80.9 | 49.3 | 48.4 | 43.2 | 70.6 | 40.3 | 72.3 |
| jais - family - 13b | 54.6 | 32.3 | 39 | 72 | 77.4 | 73.9 | 47.9 | 43.2 | 40 | 67.1 | 36.1 | 71.7 |
| jais - family - 6p7b | 53.1 | 32 | 38 | 69.3 | 76 | 71.7 | 47.1 | 40.3 | 37.4 | 65.1 | 34.4 | 72.5 |
| jais - family - 2p7b | 51 | 29.4 | 38 | 62.7 | 74.1 | 67.4 | 45.6 | 35.1 | 35.6 | 62.9 | 40.1 | 70.2 |
| jais - family - 1p3b | 48.7 | 28.2 | 35.4 | 55.4 | 72 | 62.7 | 44.9 | 30.7 | 36.2 | 60.9 | 40.4 | 69 |
| jais - family - 590m | 45.2 | 27.8 | 32.9 | 46.1 | 68.1 | 60.4 | 43.2 | 25.6 | 30.8 | 55.8 | 40.9 | 65.3 |
| jais - family - 30b - 16k - chat | 58.8 | 42 | 41.1 | 76.2 | 73.3 | 84.6 | 60.3 | 48.4 | 40.8 | 68.2 | 44.8 | 67 |
| jais - family - 30b - 8k - chat | 60.3 | 40.6 | 47.1 | 78.9 | 72.7 | 90.6 | 60 | 50.1 | 43.2 | 70.6 | 44.9 | 64.2 |
| jais - family - 13b - chat | 57.5 | 36.6 | 42.6 | 75 | 75.8 | 87.6 | 54.4 | 47.9 | 42 | 65 | 40.6 | 64.5 |
| jais - family - 6p7b - chat | 56 | 36.6 | 41.3 | 72 | 74 | 86.9 | 55.4 | 44.6 | 40 | 62.4 | 41 | 62.2 |
| jais - family - 2p7b - chat | 52.8 | 32.7 | 40.4 | 62.2 | 71 | 84.1 | 54 | 37.2 | 36.8 | 61.4 | 40.9 | 59.8 |
| jais - family - 1p3b - chat | 49.3 | 31.9 | 37.4 | 54.5 | 70.2 | 77.8 | 49.8 | 34.4 | 35.6 | 52.7 | 37.2 | 60.8 |
| jais - family - 590m - chat | 42.6 | 27.9 | 33.4 | 33.1 | 63.7 | 60.1 | 45.3 | 26.7 | 25.8 | 50.5 | 44.5 | 57.7 |
| 自適應模型 | 平均得分 | MMLU | RACE | Hellaswag | PIQA | BoolQA | SIQA | ARC - Challenge | OpenBookQA | Winogrande | TruthfulQA | CrowS - Pairs |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| jais - adapted - 70b | 60.1 | 40.4 | 38.5 | 81.2 | 81.1 | 81.2 | 48.1 | 50.4 | 45 | 75.8 | 45.7 | 74 |
| jais - adapted - 13b | 56 | 33.8 | 39.5 | 76.5 | 78.6 | 77.8 | 44.6 | 45.9 | 44.4 | 71.4 | 34.6 | 69 |
| jais - adapted - 7b | 55.7 | 32.2 | 39.8 | 75.3 | 78.8 | 75.7 | 45.2 | 42.8 | 43 | 68 | 38.3 | 73.1 |
| jais - adapted - 70b - chat | 61.4 | 38.7 | 42.9 | 82.7 | 81.2 | 89.6 | 52.9 | 54.9 | 44.4 | 75.7 | 44 | 68.8 |
| jais - adapted - 13b - chat | 58.5 | 34.9 | 42.4 | 79.6 | 79.7 | 88.2 | 50.5 | 48.5 | 42.4 | 70.3 | 42.2 | 65.1 |
| jais - adapted - 7b - chat | 58.5 | 33.8 | 43.9 | 77.8 | 79.4 | 87.1 | 47.3 | 46.9 | 43.4 | 69.9 | 42 | 72.4 |
GPT - 4評估
除了LM - harness評估外,我們還使用GPT - 4作為評判進行了開放式生成評估。我們在Vicuna測試集的一組固定的80個提示上,測量了模型在阿拉伯語和英語中的成對勝率。英語提示由我們的內部語言學家翻譯成阿拉伯語。
在以下內容中,我們將本次發佈的Jais系列模型與之前發佈的版本進行了比較:
 GPT - 4作為評判對Jais在阿拉伯語和英語中的評估。Jais系列模型在兩種語言的生成能力上明顯優於之前的Jais模型。
GPT - 4作為評判對Jais在阿拉伯語和英語中的評估。Jais系列模型在兩種語言的生成能力上明顯優於之前的Jais模型。
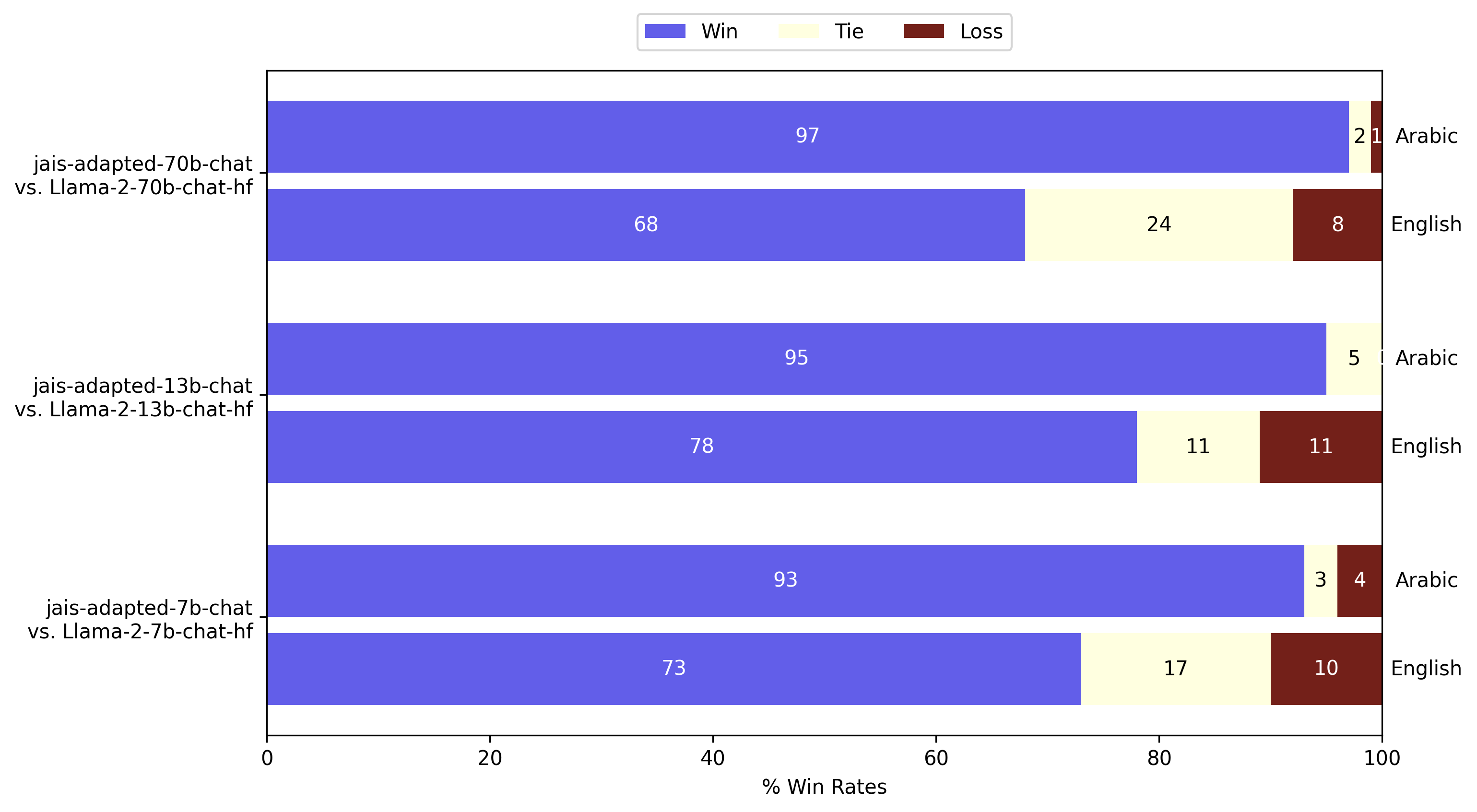 GPT - 4作為評判對自適應Jais在阿拉伯語和英語中的評估。與Llama - 2指令模型相比,阿拉伯語的生成質量顯著提高,同時英語也有所改進。
GPT - 4作為評判對自適應Jais在阿拉伯語和英語中的評估。與Llama - 2指令模型相比,阿拉伯語的生成質量顯著提高,同時英語也有所改進。
除了成對比較,我們還按照MT - bench風格對答案進行了1到10分的單答案評分。
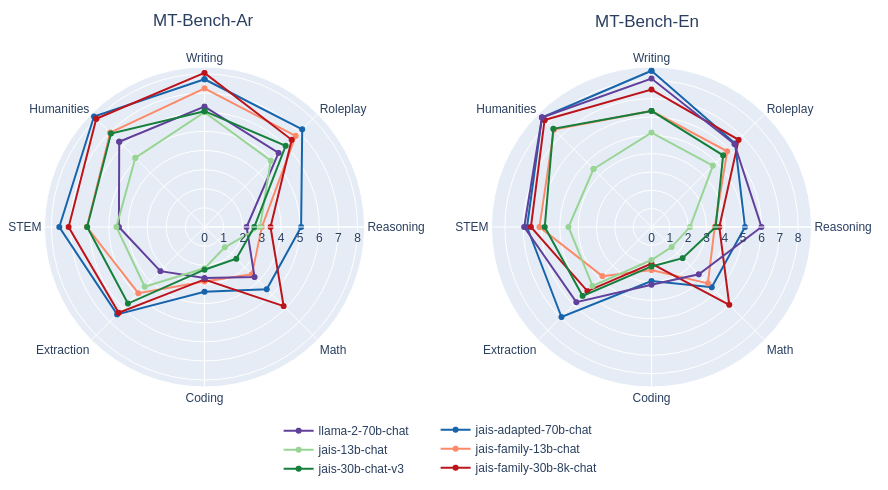 MT - bench風格對Jais和自適應Jais在阿拉伯語和英語中的單答案評分評估。與早期版本的相應模型進行了比較。響應的質量評級總體上有所提高,尤其是在阿拉伯語方面有顯著提升。
MT - bench風格對Jais和自適應Jais在阿拉伯語和英語中的單答案評分評估。與早期版本的相應模型進行了比較。響應的質量評級總體上有所提高,尤其是在阿拉伯語方面有顯著提升。
🔧 技術細節
文檔中關於技術細節的描述已在前面詳細闡述,此處不再重複。
📄 許可證
本項目採用Apache 2.0許可證。你可以在此處獲取許可證副本。除非適用法律要求或書面同意,否則本項目按“原樣”分發,不提供任何形式的明示或暗示保證。請參閱許可證條款以瞭解具體的語言權限和限制。
預期用途
我們以完全開源的許可證發佈Jais系列模型。我們歡迎所有反饋和合作機會。這個雙語模型套件的參數範圍從5.9億到700億,適用於廣泛的用例。一些潛在的下游應用包括:
- 研究:Jais系列為阿拉伯語研究人員和NLP從業者提供了計算高效和先進的模型規模,可用於自然語言理解和生成任務、雙語預訓練和自適應預訓練模型中文化對齊的機制解釋性分析,以及阿拉伯文化和語言現象的定量研究。
- 商業用途:Jais 30B和70B聊天模型非常適合直接用於聊天應用,通過適當的提示或針對特定任務進行進一步微調。可用於開發面向阿拉伯語用戶的聊天助手、進行情感分析以瞭解當地市場和客戶趨勢,以及對阿拉伯語 - 英語雙語文檔進行摘要。
我們希望受益於該模型的受眾包括:
- 學術界:從事阿拉伯語自然語言處理研究的人員。
- 企業:針對阿拉伯語用戶的公司。
- 開發者:在應用中集成阿拉伯語能力的開發者。
超出預期的使用場景
雖然Jais系列模型是強大的阿拉伯語和英語雙語模型,但瞭解其侷限性和潛在的濫用情況至關重要。禁止以任何違反適用法律法規的方式使用該模型。以下是一些不應使用該模型的場景示例:
- 惡意使用:不得使用該模型生成有害、誤導性或不適當的內容,包括但不限於生成或推廣仇恨言論、暴力或歧視性內容,傳播錯誤信息或虛假新聞,以及參與或推廣非法活動。
- 敏感信息處理:不應使用該模型處理或生成個人、機密或敏感信息。
- 跨語言通用性:Jais系列模型是雙語模型,針對阿拉伯語和英語進行了優化,不應假定其在其他語言或方言上具有同等的熟練程度。
- 高風險決策:在沒有人工監督的情況下,不應使用該模型進行高風險決策,如醫療、法律、金融或安全關鍵決策。
偏差、風險和侷限性
Jais系列模型使用公開可用的數據進行訓練,部分數據由Inception整理。我們採用了不同的技術來減少模型中的偏差。雖然已經努力最小化偏差,但與所有大語言模型一樣,該模型可能仍會表現出一些偏差。
微調後的變體是作為面向阿拉伯語和英語使用者的AI助手進行訓練的。聊天模型僅限於對這兩種語言的查詢生成響應,可能無法對其他語言的查詢生成適當的響應。
使用Jais時,你應承認並接受,與任何大語言模型一樣,它可能會生成不正確、誤導性和/或冒犯性的信息或內容。這些信息不構成建議,不應以任何方式依賴,我們也不對其使用產生的任何內容或後果負責。我們正在不斷努力開發更強大的模型,歡迎對該模型提供任何反饋。
總結
我們發佈了Jais系列阿拉伯語和英語雙語模型。廣泛的預訓練模型規模、將以英語為中心的模型適應阿拉伯語的方法,以及對所有規模模型的微調,為阿拉伯語環境下的商業和學術應用解鎖了眾多用例。
通過這次發佈,我們旨在使大語言模型更易於阿拉伯語NLP研究人員和公司使用,提供比以英語為中心的模型更好地理解阿拉伯文化的原生阿拉伯語模型。我們為預訓練、微調以及適應阿拉伯語所採用的策略可擴展到其他中低資源語言,為滿足當地語境的語言聚焦和易用模型鋪平了道路。
引用信息
@misc{sengupta2023jais,
title={Jais and Jais-chat: Arabic-Centric Foundation and Instruction-Tuned Open Generative Large Language Models},
author={Neha Sengupta, Sunil Kumar Sahu, Bokang Jia, Satheesh Katipomu, Haonan Li, Fajri Koto, William Marshall, Gurpreet Gosal, Cynthia Liu, Zhiming Chen, Osama Mohammed Afzal, Samta Kamboj, Onkar Pandit, Rahul Pal, Lalit Pradhan, Zain Muhammad Mujahid, Massa Baali, Xudong Han, Sondos Mahmoud Bsharat, Alham Fikri Aji, Zhiqiang Shen, Zhengzhong Liu, Natalia Vassilieva, Joel Hestness, Andy Hock, Andrew Feldman, Jonathan Lee, Andrew Jackson, Hector Xuguang Ren, Preslav Nakov, Timothy Baldwin and Eric Xing},
year={2023},
eprint={2308.16149},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@article{jaisfamilymodelcard,
title={Jais Family Model Card},
author={Inception},
year={2024},
url = {https://huggingface.co/inceptionai/jais-family-30b-16k-chat/blob/main/README.md}
}