%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型概述
模型特點
模型能力
使用案例
🚀 Typhoon-OCR-7B:雙語文檔解析模型
Typhoon-OCR-7B 是一款專門為泰語和英語的現實文檔解析而構建的雙語模型。它受到了類似 olmOCR 模型的啟發,並基於 Qwen2.5-VL-Instruction 開發。該模型能夠高效處理多種類型的文檔,為用戶提供準確的文檔解析服務。
點擊下方鏈接體驗更多:
⚠️ 重要提示
此模型僅適用於特定的提示,使用其他提示可能無法正常工作。
🚀 快速開始
環境準備
確保你已經安裝了必要的依賴庫,你可以使用以下命令安裝 typhoon-ocr 包:
pip install typhoon-ocr
代碼示例
以下是一個簡單的使用示例,展示瞭如何使用 typhoon-ocr 包進行文檔解析:
from typhoon_ocr import ocr_document
# 請設置環境變量 TYPHOON_OCR_API_KEY 或 OPENAI_API_KEY 以使用此函數
markdown = ocr_document("test.png")
print(markdown)
✨ 主要特性
支持現實文檔類型
1. 結構化文檔
支持金融報告、學術論文、書籍、政府表格等結構化文檔。輸出格式豐富多樣:
- 普通文本採用 Markdown 格式。
- 表格採用 HTML 格式(包括合併單元格和複雜佈局)。
- 圖表和圖形使用
<figure>標籤進行結構化視覺理解。
每個圖形都會經過多層解釋:
- 觀察:檢測風景、建築、人物、標誌和嵌入式文本等元素。
- 上下文分析:推斷位置、事件或文檔部分等上下文信息。
- 文本識別:提取和解釋泰語或英語的嵌入式文本(如圖表標籤、標題)。
- 藝術與結構分析:捕捉佈局風格、圖表類型或設計選擇,以體現文檔的基調。
- 最終總結:將所有見解整合到結構化的圖形描述中,用於總結和檢索等任務。
2. 佈局複雜和非正式文檔
支持收據、菜單、門票、信息圖表等佈局複雜和非正式文檔。輸出格式為帶有嵌入式表格和佈局感知結構的 Markdown。
性能表現
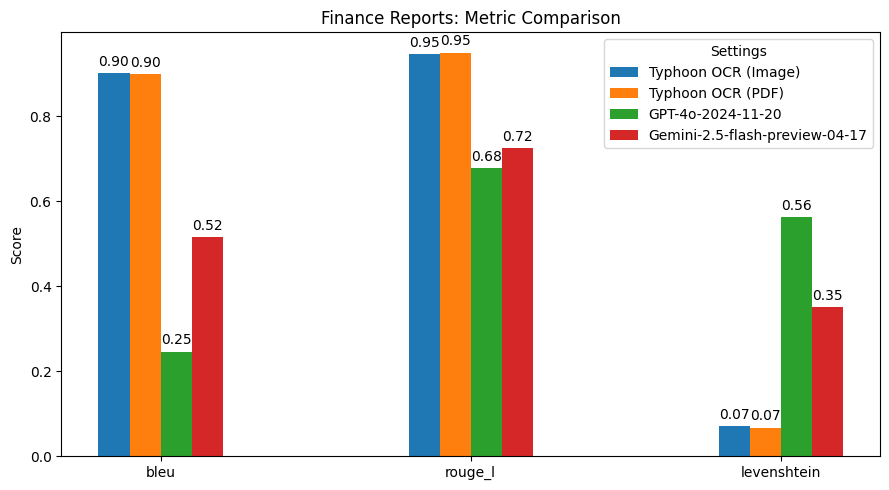
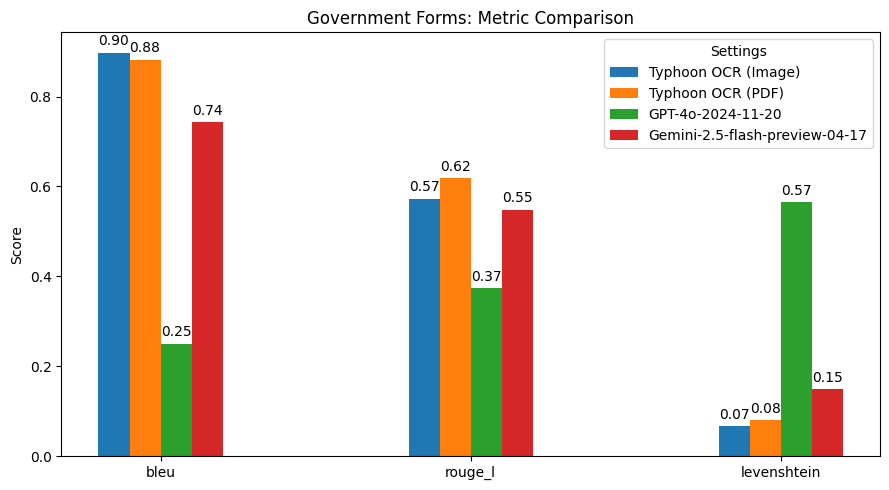
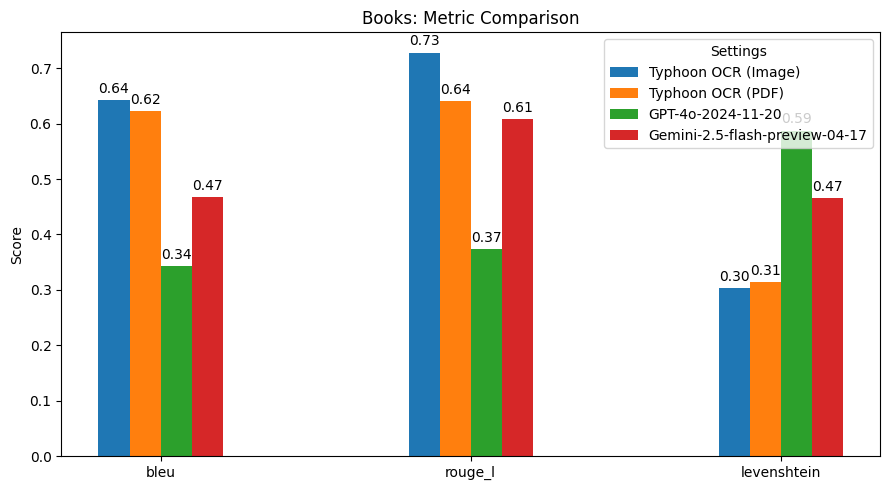
總結髮現
Typhoon OCR 在泰語文檔理解方面優於 GPT - 4o 和 Gemini 2.5 Flash,尤其在處理複雜佈局和混合語言內容的文檔時表現出色。不過,在泰語書籍基準測試中,由於嵌入式圖形的高頻和多樣性,性能略有下降。這也指出了未來的改進方向,即增強模型的圖像理解能力。此版本主要專注於實現高質量的英語和泰語文本 OCR,未來版本可能會擴展到更高級的圖像分析和圖形解釋。
💻 使用示例
基礎用法
from typhoon_ocr import ocr_document
# 請設置環境變量 TYPHOON_OCR_API_KEY 或 OPENAI_API_KEY 以使用此函數
markdown = ocr_document("test.png")
print(markdown)
高級用法
使用 API 進行推理
from typing import Callable
from openai import OpenAI
from PIL import Image
from typhoon_ocr.ocr_utils import render_pdf_to_base64png, get_anchor_text
PROMPTS_SYS = {
"default": lambda base_text: (f"Below is an image of a document page along with its dimensions. "
f"Simply return the markdown representation of this document, presenting tables in markdown format as they naturally appear.\n"
f"If the document contains images, use a placeholder like dummy.png for each image.\n"
f"Your final output must be in JSON format with a single key `natural_text` containing the response.\n"
f"RAW_TEXT_START\n{base_text}\nRAW_TEXT_END"),
"structure": lambda base_text: (
f"Below is an image of a document page, along with its dimensions and possibly some raw textual content previously extracted from it. "
f"Note that the text extraction may be incomplete or partially missing. Carefully consider both the layout and any available text to reconstruct the document accurately.\n"
f"Your task is to return the markdown representation of this document, presenting tables in HTML format as they naturally appear.\n"
f"If the document contains images or figures, analyze them and include the tag <figure>IMAGE_ANALYSIS</figure> in the appropriate location.\n"
f"Your final output must be in JSON format with a single key `natural_text` containing the response.\n"
f"RAW_TEXT_START\n{base_text}\nRAW_TEXT_END"
),
}
def get_prompt(prompt_name: str) -> Callable[[str], str]:
"""
Fetches the system prompt based on the provided PROMPT_NAME.
:param prompt_name: The identifier for the desired prompt.
:return: The system prompt as a string.
"""
return PROMPTS_SYS.get(prompt_name, lambda x: "Invalid PROMPT_NAME provided.")
# Render the first page to base64 PNG and then load it into a PIL image.
image_base64 = render_pdf_to_base64png(filename, page_num, target_longest_image_dim=1800)
image_pil = Image.open(BytesIO(base64.b64decode(image_base64)))
# Extract anchor text from the PDF (first page)
anchor_text = get_anchor_text(filename, page_num, pdf_engine="pdfreport", target_length=8000)
# Retrieve and fill in the prompt template with the anchor_text
prompt_template_fn = get_prompt(task_type)
PROMPT = prompt_template_fn(anchor_text)
messages = [{
"role": "user",
"content": [
{"type": "text", "text": PROMPT},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{image_base64}"}},
],
}]
# send messages to openai compatible api
openai = OpenAI(base_url="https://api.opentyphoon.ai/v1", api_key="TYPHOON_API_KEY")
response = openai.chat.completions.create(
model="typhoon-ocr-preview",
messages=messages,
max_tokens=16384,
temperature=0.1,
top_p=0.6,
extra_body={
"repetition_penalty": 1.2,
},
)
text_output = response.choices[0].message.content
print(text_output)
使用本地模型(需要 GPU)
# Initialize the model
model = Qwen2_5_VLForConditionalGeneration.from_pretrained("scb10x/typhoon-ocr-7b", torch_dtype=torch.bfloat16 ).eval()
processor = AutoProcessor.from_pretrained("scb10x/typhoon-ocr-7b")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# Apply the chat template and processor
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
main_image = Image.open(BytesIO(base64.b64decode(image_base64)))
inputs = processor(
text=[text],
images=[main_image],
padding=True,
return_tensors="pt",
)
inputs = {key: value.to(device) for (key, value) in inputs.items()}
# Generate the output
output = model.generate(
**inputs,
temperature=0.1,
max_new_tokens=12000,
num_return_sequences=1,
repetition_penalty=1.2,
do_sample=True,
)
# Decode the output
prompt_length = inputs["input_ids"].shape[1]
new_tokens = output[:, prompt_length:]
text_output = processor.tokenizer.batch_decode(
new_tokens, skip_special_tokens=True
)
print(text_output[0])
📚 詳細文檔
提示信息
此模型僅適用於以下特定提示,其中 {base_text} 指的是使用 typhoon-ocr 包中的 get_anchor_text 函數從 PDF 元數據中提取的信息。使用其他提示可能無法正常工作。
PROMPTS_SYS = {
"default": lambda base_text: (f"Below is an image of a document page along with its dimensions. "
f"Simply return the markdown representation of this document, presenting tables in markdown format as they naturally appear.\n"
f"If the document contains images, use a placeholder like dummy.png for each image.\n"
f"Your final output must be in JSON format with a single key `natural_text` containing the response.\n"
f"RAW_TEXT_START\n{base_text}\nRAW_TEXT_END"),
"structure": lambda base_text: (
f"Below is an image of a document page, along with its dimensions and possibly some raw textual content previously extracted from it. "
f"Note that the text extraction may be incomplete or partially missing. Carefully consider both the layout and any available text to reconstruct the document accurately.\n"
f"Your task is to return the markdown representation of this document, presenting tables in HTML format as they naturally appear.\n"
f"If the document contains images or figures, analyze them and include the tag <figure>IMAGE_ANALYSIS</figure> in the appropriate location.\n"
f"Your final output must be in JSON format with a single key `natural_text` containing the response.\n"
f"RAW_TEXT_START\n{base_text}\nRAW_TEXT_END"
),
}
生成參數
建議使用以下生成參數。由於這是一個 OCR 模型,不建議使用較高的溫度。請確保溫度設置為 0 或 0.1,不要更高。
temperature=0.1,
top_p=0.6,
repetition_penalty: 1.2
🔧 技術細節
模型信息
| 屬性 | 詳情 |
|---|---|
| 模型類型 | 基於 Qwen2.5-VL-Instruction 的雙語文檔解析模型 |
| 支持語言 | 英語、泰語 |
| 標籤 | OCR、視覺語言、文檔理解、多語言 |
預期用途和侷限性
這是一個特定任務的模型,僅適用於提供的提示。它不包含任何護欄或 VQA 功能。由於大語言模型(LLM)的性質,可能會出現一定程度的幻覺。建議開發人員在特定用例的上下文中仔細評估這些風險。
📄 許可證
文檔中未提及相關許可證信息。
🔗 相關鏈接
📖 引用
如果您發現 Typhoon2 對您的工作有幫助,請使用以下 BibTeX 格式進行引用:
@misc{typhoon2,
title={Typhoon 2: A Family of Open Text and Multimodal Thai Large Language Models},
author={Kunat Pipatanakul and Potsawee Manakul and Natapong Nitarach and Warit Sirichotedumrong and Surapon Nonesung and Teetouch Jaknamon and Parinthapat Pengpun and Pittawat Taveekitworachai and Adisai Na-Thalang and Sittipong Sripaisarnmongkol and Krisanapong Jirayoot and Kasima Tharnpipitchai},
year={2024},
eprint={2412.13702},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.13702},
}