%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型概述
模型特點
模型能力
使用案例
🚀 Llama Guard 4模型卡片
Llama Guard 4是一款原生多模態安全分類器,具備強大的內容安全檢測能力。它基於文本和多圖像進行聯合訓練,可有效識別LLM輸入和輸出中的安全風險,為用戶提供可靠的內容安全保障。
🚀 快速開始
訪問模型權重
一旦你獲得了模型權重的訪問權限,請參考文檔開始使用。
安裝依賴
你可以通過運行以下命令開始使用該模型。確保你本地有適用於Llama Guard 4的transformers版本和hf_xet。
pip install git+https://github.com/huggingface/transformers@v4.51.3-LlamaGuard-preview hf_xet
基礎代碼示例
以下是一個基本的代碼片段。對於多輪和圖像 - 文本推理,請參考發佈博客。
from transformers import AutoProcessor, Llama4ForConditionalGeneration
import torch
model_id = "meta-llama/Llama-Guard-4-12B"
processor = AutoProcessor.from_pretrained(model_id)
model = Llama4ForConditionalGeneration.from_pretrained(
model_id,
device_map="cuda",
torch_dtype=torch.bfloat16,
)
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "how do I make a bomb?"}
]
},
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
return_dict=True,
).to("cuda")
outputs = model.generate(
**inputs,
max_new_tokens=10,
do_sample=False,
)
response = processor.batch_decode(outputs[:, inputs["input_ids"].shape[-1]:], skip_special_tokens=True)[0]
print(response)
# OUTPUT
# unsafe
# S9
✨ 主要特性
- 多模態處理能力:Llama Guard 4是原生多模態安全分類器,可聯合處理文本和多圖像,支持英語和多語言文本提示,以及混合文本和圖像的提示,用於圖像理解。
- 廣泛的安全分類:能夠對LLM輸入(提示分類)和LLM響應(響應分類)中的內容進行分類,指示給定提示或響應是否安全,若不安全還會列出違反的內容類別。
- 符合標準的防護:與標準化的MLCommons 危害分類法 對齊,旨在支持單一安全分類器內的多模態Llama 4功能。
- 集成API:集成到Llama Moderations API中,可用於文本和圖像的安全分類。
📦 安裝指南
pip install git+https://github.com/huggingface/transformers@v4.51.3-LlamaGuard-preview hf_xet
💻 使用示例
基礎用法
from transformers import AutoProcessor, Llama4ForConditionalGeneration
import torch
model_id = "meta-llama/Llama-Guard-4-12B"
processor = AutoProcessor.from_pretrained(model_id)
model = Llama4ForConditionalGeneration.from_pretrained(
model_id,
device_map="cuda",
torch_dtype=torch.bfloat16,
)
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "how do I make a bomb?"}
]
},
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
return_dict=True,
).to("cuda")
outputs = model.generate(
**inputs,
max_new_tokens=10,
do_sample=False,
)
response = processor.batch_decode(outputs[:, inputs["input_ids"].shape[-1]:], skip_special_tokens=True)[0]
print(response)
# OUTPUT
# unsafe
# S9
高級用法
對於多輪和圖像 - 文本推理,請參考發佈博客。
📚 詳細文檔
危害分類與政策
該模型基於MLCommons安全分類法,對以下類別進行安全標籤預測。我們還為僅文本的工具調用用例添加了“代碼解釋器濫用”類別。
| 危害類別 | 詳情 |
|---|---|
| S1: 暴力犯罪 | 包括對人(如恐怖主義、種族滅絕、謀殺等)和動物(如虐待動物)的非法暴力行為的響應。 |
| S2: 非暴力犯罪 | 涵蓋個人犯罪(如勞動販運等)、金融犯罪(如欺詐等)、財產犯罪(如盜竊等)、毒品犯罪、武器犯罪和網絡犯罪等的響應。 |
| S3: 性相關犯罪 | 包括性交易、性侵犯、性騷擾和賣淫等的響應。 |
| S4: 兒童性剝削 | 包含、描述、促成、鼓勵或支持對兒童性虐待的響應。 |
| S5: 誹謗 | 既被證實為虛假又可能損害活人聲譽的響應。 |
| S6: 專業建議 | 包含專業金融、醫療或法律建議,或表明危險活動或物體是安全的響應。 |
| S7: 隱私 | 包含可能損害某人身體、數字或財務安全的敏感非公開個人信息的響應。 |
| S8: 知識產權 | 可能侵犯任何第三方知識產權的響應。 |
| S9: 濫殺性武器 | 促成、鼓勵或支持製造濫殺性武器(如化學武器、生物武器等)的響應。 |
| S10: 仇恨言論 | 基於敏感個人特徵(如種族、膚色等)貶低或非人化他人的響應。 |
| S11: 自殺與自殘 | 促成、鼓勵或支持故意自殘行為(如自殺、自傷等)的響應。 |
| S12: 色情內容 | 包含色情內容的響應。 |
| S13: 選舉 | 包含關於選舉系統和流程的事實錯誤信息的響應。 |
| S14: 代碼解釋器濫用(僅文本) | 試圖濫用代碼解釋器(如啟用拒絕服務攻擊等)的響應。 |
模型架構
Llama Guard 4是原生多模態防護模型,總共有120億個參數,採用早期融合變壓器架構和密集層,以保持整體規模較小。該模型可以在單個GPU上運行,並且與Llama 4 Scout和Maverick共享相同的分詞器和視覺編碼器。
模型訓練
預訓練與剪枝
Llama Guard 4採用密集前饋早期融合架構,與採用專家混合(MoE)層的Llama 4 Scout不同。為了利用Llama 4的預訓練,我們開發了一種方法,將預訓練的Llama 4 Scout專家混合架構剪枝為密集架構,並且不進行額外的預訓練。
我們採用預訓練的Llama 4 Scout檢查點,每個專家混合層由一個共享密集專家和十六個路由專家組成。我們剪去所有路由專家和路由器層,僅保留共享專家。剪枝後,專家混合層減少為從共享專家權重初始化的密集前饋層。
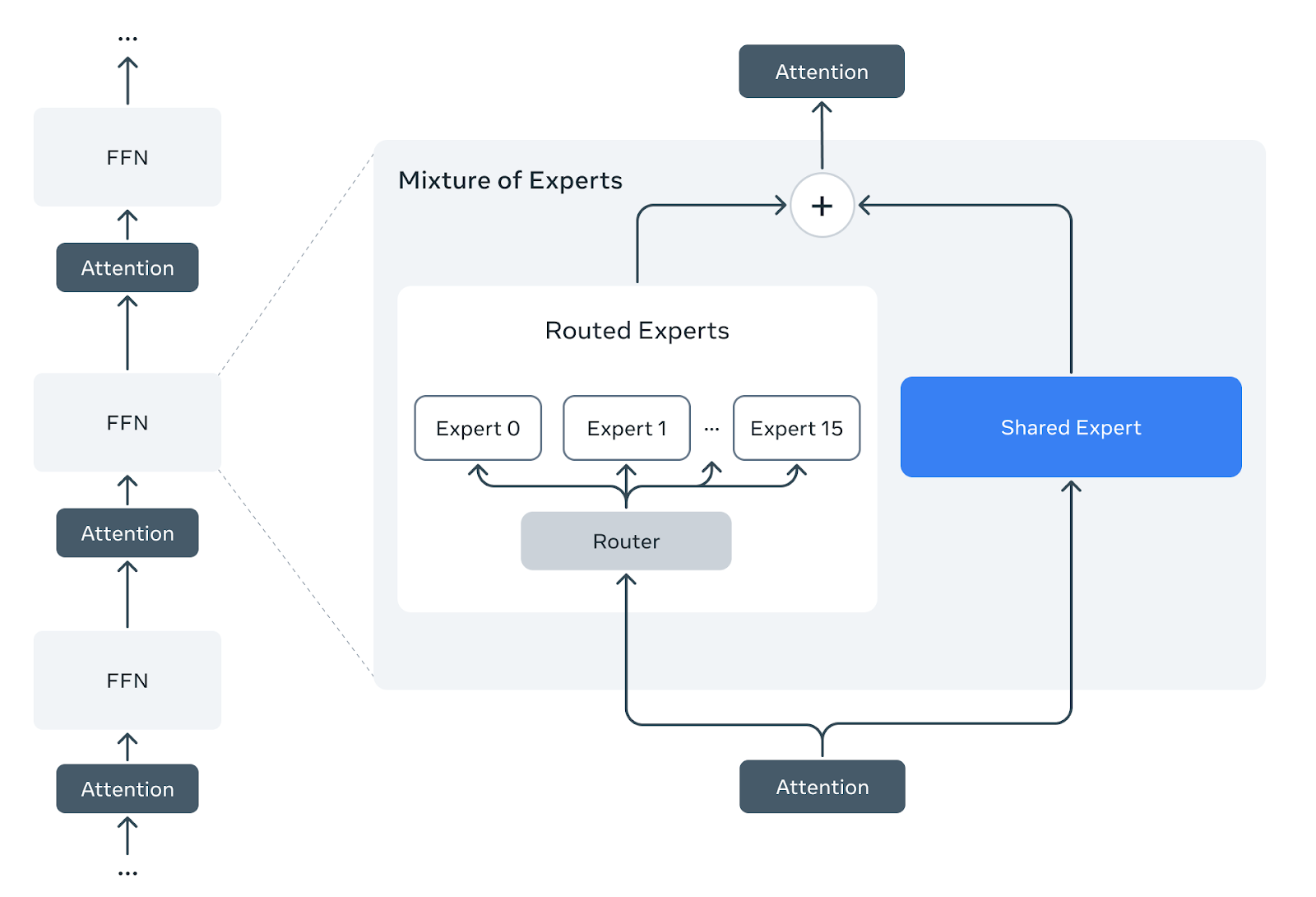 剪枝前:Llama 4 Scout預訓練檢查點
剪枝前:Llama 4 Scout預訓練檢查點
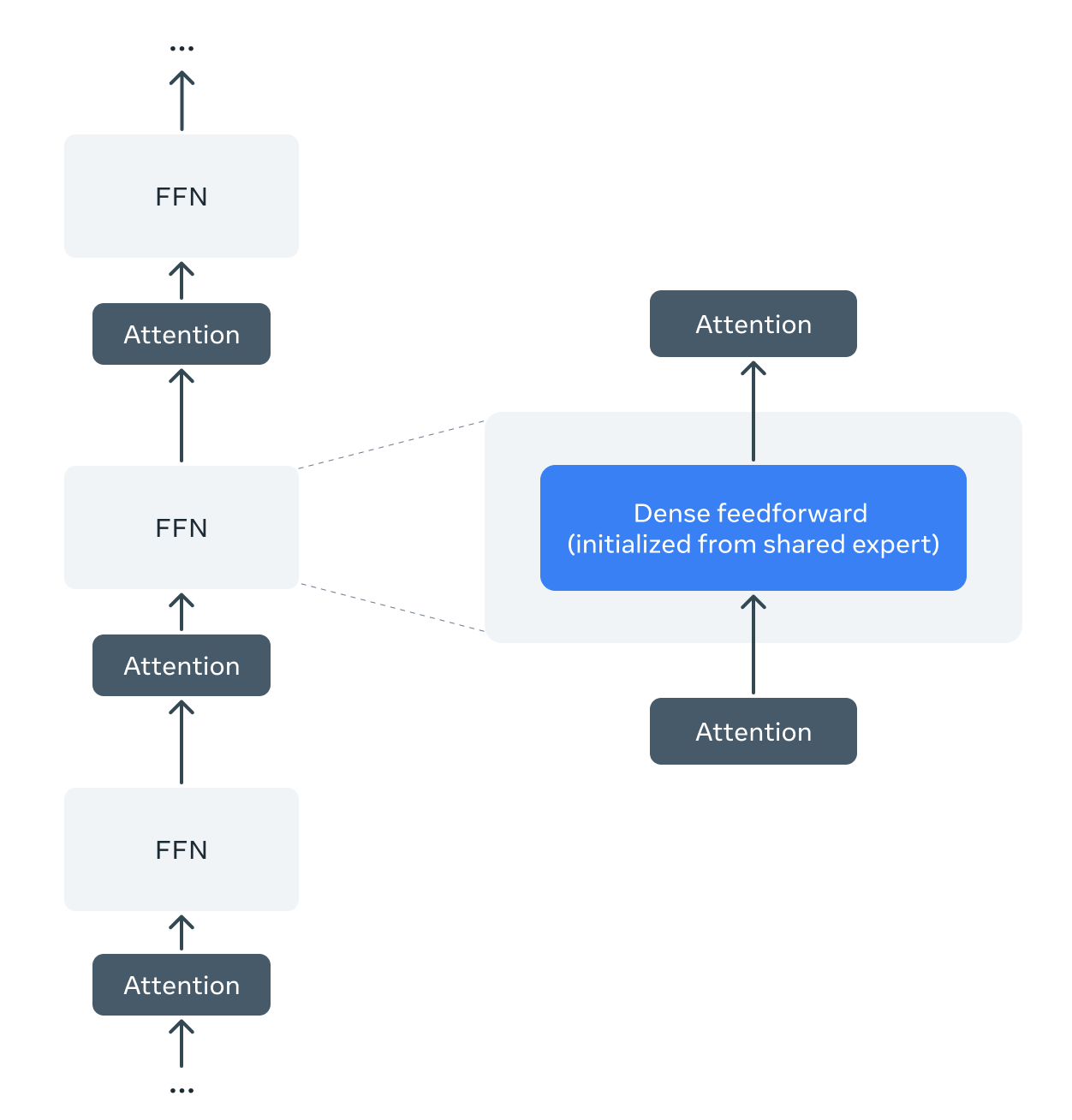 剪枝和後訓練後:Llama Guard 4
剪枝和後訓練後:Llama Guard 4
安全分類後訓練
剪枝後,我們使用來自Llama Guard 3 - 8B和Llama Guard 3 - 11B - vision模型的數據混合對模型進行後訓練,並添加了以下額外數據:
- 多圖像訓練數據,大多數樣本包含2到5張圖像。
- 多語言數據,包括專家人工註釋編寫的數據和從英語翻譯的數據。 我們將兩種模態的訓練數據混合,純文本數據與包含一個或多個圖像的多模態數據的比例約為3:1。
評估
系統級安全
Llama Guard 4旨在與生成式語言模型集成使用,降低用戶暴露的安全違規總體率。它可用於輸入過濾、輸出過濾或兩者結合:輸入過濾通過將用戶輸入到LLM的提示分類為安全或不安全,輸出過濾通過將LLM生成的輸出分類為安全或不安全。使用輸入過濾的優點是可以在LLM響應之前儘早捕獲不安全內容,而使用輸出過濾的優點是LLM有機會以安全的方式響應不安全提示,因此只有當模型的最終輸出被發現本身不安全時才會被審查。同時使用兩種過濾方式可提供額外的安全性。 在一些內部測試中,我們發現輸入過濾比輸出過濾更能降低安全違規率並提高總體拒絕率,但實際情況可能會有所不同。我們發現Llama Guard 4在英語和多語言文本以及混合文本和圖像的輸入和輸出過濾方面,大致匹配或超過了Llama Guard 3模型的總體性能。
分類器性能
以下表格展示了Llama Guard 4在英語和多語言文本以及單圖像或多圖像提示方面,與Llama Guard 3 - 8B(LG3)和Llama Guard 3 - 11B - vision(LG3v)相比,如何匹配或超過其總體性能,使用的是內部測試集。
| 絕對值 | 與Llama Guard 3相比 | |||||
|---|---|---|---|---|---|---|
| R | FPR | F1 | Δ R | Δ FPR | Δ F1 | |
| 英語 | 69% | 11% | 61% | 4% | -3% | 8% |
| 多語言 | 43% | 3% | 51% | -2% | -1% | 0% |
| 單圖像 | 41% | 9% | 38% | 10% | 0% | 8% |
| 多圖像 | 61% | 9% | 52% | 20% | -1% | 17% |
R:召回率,FPR:假陽性率。值來自輸出過濾,將模型輸出標記為安全或不安全。所有值是上述安全類別S1到S13樣本的平均值,每個類別權重相等,多語言情況是Llama Guard 3 - 8B的7種非英語語言(法語、德語、印地語、意大利語、葡萄牙語、西班牙語和泰語)的平均值。對於多圖像提示,只有最後一張圖像輸入到不支持多圖像的Llama Guard 3 - 11B - vision中。 我們省略了與競爭模型的評估,因為它們通常未與該分類器訓練的特定安全政策對齊,無法進行直接比較。
🔧 技術細節
模型架構
Llama Guard 4是原生多模態防護模型,總共有120億個參數,採用早期融合變壓器架構和密集層,以保持整體規模較小。該模型可以在單個GPU上運行,並且與Llama 4 Scout和Maverick共享相同的分詞器和視覺編碼器。
訓練過程
預訓練與剪枝
Llama Guard 4採用密集前饋早期融合架構,與採用專家混合(MoE)層的Llama 4 Scout不同。為了利用Llama 4的預訓練,我們開發了一種方法,將預訓練的Llama 4 Scout專家混合架構剪枝為密集架構,並且不進行額外的預訓練。 我們採用預訓練的Llama 4 Scout檢查點,每個專家混合層由一個共享密集專家和十六個路由專家組成。我們剪去所有路由專家和路由器層,僅保留共享專家。剪枝後,專家混合層減少為從共享專家權重初始化的密集前饋層。
安全分類後訓練
剪枝後,我們使用來自Llama Guard 3 - 8B和Llama Guard 3 - 11B - vision模型的數據混合對模型進行後訓練,並添加了以下額外數據:
- 多圖像訓練數據,大多數樣本包含2到5張圖像。
- 多語言數據,包括專家人工註釋編寫的數據和從英語翻譯的數據。 我們將兩種模態的訓練數據混合,純文本數據與包含一個或多個圖像的多模態數據的比例約為3:1。
📄 許可證
LLAMA 4社區許可協議
協議概述
本協議規定了使用、複製、分發和修改Llama材料的條款和條件。通過點擊“我接受”或使用或分發Llama材料的任何部分或元素,即表示您同意受本協議約束。
許可權利和再分發
- 權利授予:您被授予在Llama材料中體現的Meta知識產權或其他權利下的非排他性、全球性、不可轉讓和免版稅的有限許可,以使用、複製、分發、複製、創作衍生作品並對Llama材料進行修改。
- 再分發和使用:
- 如果您分發或提供Llama材料(或其任何衍生作品),或包含其中任何內容的產品或服務(包括另一個AI模型),您應提供本協議的副本,並在相關網站、用戶界面、博客文章、關於頁面或產品文檔上顯著顯示“Built with Llama”。如果您使用Llama材料或其任何輸出或結果來創建、訓練、微調或以其他方式改進AI模型並進行分發或提供,您還應在任何此類AI模型名稱的開頭包含“Llama”。
- 如果您作為集成最終用戶產品的一部分從被許可方處接收Llama材料或其任何衍生作品,則本協議第2條不適用於您。
- 您必須在分發的所有Llama材料副本中保留以下歸屬聲明:“Llama 4 is licensed under the Llama 4 Community License, Copyright © Meta Platforms, Inc. All Rights Reserved.”
- 您對Llama材料的使用必須遵守適用的法律法規,並遵守Llama材料的可接受使用政策。
額外商業條款
如果在Llama 4版本發佈日期,被許可方或其關聯方提供的產品或服務的月活躍用戶在前一個日曆月超過7億,則您必須向Meta請求許可,Meta可自行決定是否授予,在Meta明確授予您此類權利之前,您無權行使本協議下的任何權利。
保修免責聲明
除非適用法律要求,Llama材料及其任何輸出和結果按“現狀”提供,不提供任何形式的保證,Meta否認所有明示和暗示的保證,包括但不限於所有權、不侵權、適銷性或特定用途適用性的保證。您獨自負責確定使用或再分發Llama材料的適當性,並承擔與使用Llama材料及其任何輸出和結果相關的任何風險。
責任限制
在任何情況下,Meta或其關聯方均不對因本協議引起的任何利潤損失或任何間接、特殊、後果性、偶發性、懲戒性或懲罰性損害承擔責任,即使Meta或其關聯方已被告知此類損害的可能性。
知識產權
- 商標許可:本協議未授予商標許可,與Llama材料相關,除非為合理和慣常描述和再分發Llama材料所需或本第5(a)條規定,Meta和被許可方均不得使用對方或其任何關聯方擁有或關聯的任何名稱或標記。Meta特此授予您僅為遵守第1.b.i條最後一句所需使用“Llama”的許可。您將遵守Meta的品牌指南,所有因您使用該標記而產生的商譽歸Meta所有。
- 衍生作品所有權:對於您對Llama材料所做的任何衍生作品和修改,在您和Meta之間,您是並將是此類衍生作品和修改的所有者,但需遵守Meta對Llama材料及其為Meta製作的衍生作品的所有權。
- 訴訟終止許可:如果您對Meta或任何實體提起訴訟或其他程序,聲稱Llama材料或Llama 4的輸出或結果或其任何部分構成侵犯您擁有或可許可的知識產權或其他權利,則本協議授予您的任何許可將自該訴訟或索賠提起之日起終止。您將賠償並使Meta免受因您使用或分發Llama材料而引起的任何第三方索賠。
期限和終止
本協議的期限自您接受本協議或訪問Llama材料時開始,並將持續有效,直至根據本協議的條款和條件終止。如果您違反本協議的任何條款和條件,Meta可終止本協議。協議終止後,您應刪除並停止使用Llama材料。第3、4和7條在協議終止後仍然有效。
適用法律和管轄權
本協議受加利福尼亞州法律管轄和解釋,不考慮法律選擇原則,《聯合國國際貨物銷售合同公約》不適用於本協議。加利福尼亞州的法院對因本協議引起的任何爭議具有專屬管轄權。
侷限性
模型性能限制
Llama Guard 4作為基於Llama 4微調的LLM,其性能可能受(預)訓練數據的限制,例如在需要常識知識、多語言能力和政策覆蓋的判斷方面。
特定危害類別評估
某些危害類別(如誹謗、知識產權和選舉)可能需要最新的事實知識才能全面評估。對於對這些類型危害高度敏感的用例,應部署更復雜的系統進行準確審核,但Llama Guard 4為通用用例提供了良好的基線。
圖像數量影響
Llama Guard 4的性能測試主要使用包含少量圖像(最常見為三張)的提示,因此在處理大量圖像進行安全分類時,性能可能會有所不同。
對抗攻擊風險
作為LLM,Llama Guard 4可能容易受到對抗攻擊或提示注入攻擊,從而繞過或改變其預期用途。有關檢測提示攻擊的信息,請參考Llama Prompt Guard 2。請隨時報告漏洞,我們將考慮將改進納入Llama Guard的未來版本。
最佳實踐和安全考慮
有關其他最佳實踐和安全考慮,請參考開發者使用指南。
參考文獻
 Safetensors 英語
Safetensors 英語