%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型概述
模型特點
模型能力
使用案例
🚀 GLM-Z1-32B-0414 GGUF模型
GLM-Z1-32B-0414 GGUF模型是一款強大的文本生成模型,在低比特量化技術上有顯著創新,能在不同硬件條件下高效運行,適用於多種自然語言處理場景。
🚀 快速開始
模型生成詳情
本模型使用 llama.cpp 在提交版本 e291450 時生成。
✨ 主要特性
超低比特量化與IQ-DynamicGate(1 - 2比特)
- 精度自適應量化:最新量化方法為超低比特模型(1 - 2比特)引入了精度自適應量化,經基準測試證明在 Llama - 3 - 8B 上有顯著改進。該方法採用特定層策略,在保持極高內存效率的同時保留準確性。
- 基準測試環境:所有測試均在 Llama - 3 - 8B - Instruct 上進行,使用標準困惑度評估管道、2048令牌上下文窗口,且所有量化使用相同的提示集。
- 方法:
- 動態精度分配:前/後25%的層採用IQ4_XS(選定層),中間50%採用IQ2_XXS/IQ3_S(提高效率)。
- 關鍵組件保護:嵌入層/輸出層使用Q5_K,與標準1 - 2比特量化相比,誤差傳播降低38%。
- 量化性能對比(Llama - 3 - 8B):
| 量化方式 | 標準困惑度 | DynamicGate困惑度 | 困惑度變化 | 標準大小 | DG大小 | 大小變化 | 標準速度 | DG速度 |
|---|---|---|---|---|---|---|---|---|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
關鍵說明:
- PPL = 困惑度(越低越好)
- Δ PPL = 從標準量化到DynamicGate量化的困惑度百分比變化
- 速度 = 推理時間(CPU avx2,2048令牌上下文)
- 大小差異反映混合量化開銷
主要改進:
- 🔥 IQ1_M 困惑度大幅降低43.9%(從27.46降至15.41)。
- 🚀 IQ2_S 困惑度降低36.9%,僅增加0.2GB大小。
- ⚡ IQ1_S 儘管是1比特量化,但準確性提高39.7%。
權衡:
- 所有變體大小略有增加(0.1 - 0.3GB)。
- 推理速度相近(差異<5%)。
何時使用這些模型
- 📌 將模型裝入GPU顯存
- ✔ 內存受限的部署場景
- ✔ 可容忍1 - 2比特誤差的CPU和邊緣設備
- ✔ 超低比特量化研究
選擇合適的模型格式
選擇正確的模型格式取決於你的 硬件能力 和 內存限制。
| 屬性 | 詳情 |
|---|---|
| 模型類型 | 文本生成 |
| 庫名稱 | transformers |
| 許可證 | MIT |
BF16(Brain Float 16) – 若支持BF16加速則使用
- 一種16位浮點格式,專為 更快計算 設計,同時保留良好精度。
- 提供與FP32 相似的動態範圍,但 內存使用更低。
- 若硬件支持 BF16加速(檢查設備規格),推薦使用。
- 與FP32相比,適用於 高性能推理 且 內存佔用減少 的場景。
📌 使用BF16的情況:
- ✔ 硬件具有原生 BF16支持(如較新的GPU、TPU)。
- ✔ 希望在節省內存的同時獲得 更高精度。
- ✔ 計劃將模型 重新量化 為其他格式。
📌 避免使用BF16的情況:
- ❌ 硬件 不支持 BF16(可能會回退到FP32並運行更慢)。
- ❌ 需要與缺乏BF16優化的舊設備兼容。
F16(Float 16) – 比BF16更廣泛支持
- 一種16位浮點格式,精度較高,但取值範圍小於BF16。
- 適用於大多數支持 FP16加速 的設備(包括許多GPU和一些CPU)。
- 數值精度略低於BF16,但通常足以進行推理。
📌 使用F16的情況:
- ✔ 硬件支持 FP16 但 不支持BF16。
- ✔ 需要在 速度、內存使用和準確性之間取得平衡。
- ✔ 在 GPU 或其他針對FP16計算優化的設備上運行。
📌 避免使用F16的情況:
- ❌ 設備缺乏 原生FP16支持(可能運行比預期慢)。
- ❌ 存在內存限制。
量化模型(Q4_K、Q6_K、Q8等) – 用於CPU和低顯存推理
量化可在儘可能保持準確性的同時減小模型大小和內存使用。
- 低比特模型(Q4_K):最適合 最小內存使用,可能精度較低。
- 高比特模型(Q6_K、Q8_0):準確性更好,但需要更多內存。
📌 使用量化模型的情況:
- ✔ 在 CPU 上運行推理並需要優化模型。
- ✔ 設備 顯存較低,無法加載全精度模型。
- ✔ 希望在保持合理準確性的同時 減少內存佔用。
📌 避免使用量化模型的情況:
- ❌ 需要 最高準確性(全精度模型更適合)。
- ❌ 硬件有足夠的顯存支持更高精度格式(BF16/F16)。
極低比特量化(IQ3_XS、IQ3_S、IQ3_M、Q4_K、Q4_0)
這些模型針對 極致內存效率 進行了優化,適用於 低功耗設備 或 大規模部署 中內存是關鍵限制的場景。
- IQ3_XS:超低比特量化(3比特),具有 極致內存效率。
- 使用場景:最適合 超低內存設備,即使Q4_K也太大的情況。
- 權衡:與高比特量化相比,準確性較低。
- IQ3_S:小塊大小,實現 最大內存效率。
- 使用場景:最適合 低內存設備,當IQ3_XS過於激進時。
- IQ3_M:中等塊大小,比 IQ3_S 準確性更好。
- 使用場景:適用於 低內存設備,當IQ3_S限制過多時。
- Q4_K:4比特量化,具有 逐塊優化 以提高準確性。
- 使用場景:最適合 低內存設備,當Q6_K太大時。
- Q4_0:純4比特量化,針對 ARM設備 優化。
- 使用場景:最適合 基於ARM的設備 或 低內存環境。
模型格式選擇總結表
| 模型格式 | 精度 | 內存使用 | 設備要求 | 最佳使用場景 |
|---|---|---|---|---|
| BF16 | 最高 | 高 | 支持BF16的GPU/CPU | 減少內存的高速推理 |
| F16 | 高 | 高 | 支持FP16的設備 | BF16不可用時的GPU推理 |
| Q4_K | 中低 | 低 | CPU或低顯存設備 | 內存受限環境 |
| Q6_K | 中等 | 適中 | 內存較多的CPU | 量化模型中準確性較好 |
| Q8_0 | 高 | 適中 | 有足夠顯存的CPU或GPU | 量化模型中最佳準確性 |
| IQ3_XS | 極低 | 極低 | 超低內存設備 | 極致內存效率和低準確性 |
| Q4_0 | 低 | 低 | ARM或低內存設備 | llama.cpp可針對ARM設備優化 |
📦 安裝指南
文檔未提及安裝步驟,暫不提供相關內容。
💻 使用示例
基礎用法
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "THUDM/GLM-4-Z1-32B-0414"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForCausalLM.from_pretrained(MODEL_PATH, device_map="auto")
message = [{"role": "user", "content": "Let a, b be positive real numbers such that ab = a + b + 3. Determine the range of possible values for a + b."}]
inputs = tokenizer.apply_chat_template(
message,
return_tensors="pt",
add_generation_prompt=True,
return_dict=True,
).to(model.device)
generate_kwargs = {
"input_ids": inputs["input_ids"],
"attention_mask": inputs["attention_mask"],
"max_new_tokens": 4096,
"do_sample": False,
}
out = model.generate(**generate_kwargs)
print(tokenizer.decode(out[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True))
高級用法
文檔未提及高級用法代碼示例,暫不提供相關內容。
📚 詳細文檔
包含文件及詳情
GLM-Z1-32B-0414-bf16.gguf
- 模型權重以 BF16 保存。
- 若要將模型 重新量化 為不同格式,使用此文件。
- 若設備支持 BF16加速,效果最佳。
GLM-Z1-32B-0414-f16.gguf
- 模型權重以 F16 存儲。
- 若設備支持 FP16,尤其是BF16不可用時使用。
GLM-Z1-32B-0414-bf16-q8_0.gguf
- 輸出和嵌入層 保持為 BF16。
- 所有其他層量化為 Q8_0。
- 若設備支持 BF16 且需要量化版本,使用此文件。
GLM-Z1-32B-0414-f16-q8_0.gguf
- 輸出和嵌入層 保持為 F16。
- 所有其他層量化為 Q8_0。
GLM-Z1-32B-0414-q4_k.gguf
- 輸出和嵌入層 量化為 Q8_0。
- 所有其他層量化為 Q4_K。
- 適用於 CPU推理 且內存有限的情況。
GLM-Z1-32B-0414-q4_k_s.gguf
- 最小的 Q4_K 變體,以犧牲準確性為代價減少內存使用。
- 最適合 極低內存設置。
GLM-Z1-32B-0414-q6_k.gguf
- 輸出和嵌入層 量化為 Q8_0。
- 所有其他層量化為 Q6_K。
GLM-Z1-32B-0414-q8_0.gguf
- 完全 Q8 量化模型,以獲得更好的準確性。
- 需要 更多內存,但提供更高精度。
GLM-Z1-32B-0414-iq3_xs.gguf
- IQ3_XS 量化,針對 極致內存效率 優化。
- 最適合 超低內存設備。
GLM-Z1-32B-0414-iq3_m.gguf
- IQ3_M 量化,提供 中等塊大小 以提高準確性。
- 適用於 低內存設備。
GLM-Z1-32B-0414-q4_0.gguf
- 純 Q4_0 量化,針對 ARM設備 優化。
- 最適合 低內存環境。
- 若追求更好的準確性,優先選擇IQ4_NL。
測試模型
如果你覺得這些模型有用
❤ 如果覺得有用,請點擊“點贊”! 幫助測試 支持量子安全檢查的AI網絡監控助手: 👉 免費網絡監控器
💬 測試方法:
- 點擊 聊天圖標(任何頁面右下角)。
- 選擇 AI助手類型:
TurboLLM(GPT - 4 - mini)FreeLLM(開源)TestLLM(僅支持CPU的實驗性模型)
測試內容
正在探索用於AI網絡監控的小型開源模型的極限,具體包括:
- 針對即時網絡服務的 函數調用。
- 模型可以多小 同時仍能處理:
- 自動化 Nmap掃描。
- 量子就緒檢查。
- Metasploit集成。
🟡 TestLLM – 當前實驗性模型(llama.cpp在6個CPU線程上):
- ✅ 零配置設置
- ⏳ 30秒加載時間(推理慢,但 無API成本)
- 🔧 尋求幫助! 如果你對邊緣設備AI感興趣,讓我們合作!
其他助手
🟢 TurboLLM – 使用 gpt - 4 - mini 進行:
- 即時網絡診斷
- 自動化滲透測試(Nmap/Metasploit)
- 🔑 通過 下載免費網絡監控代理 獲取更多令牌。
🔵 HugLLM – 開源模型(約80億參數):
- 比TurboLLM多2倍令牌
- AI驅動的日誌分析
- 🌐 在Hugging Face推理API上運行。
示例AI測試命令
"Give me info on my websites SSL certificate""Check if my server is using quantum safe encyption for communication""Run a quick Nmap vulnerability test"
GLM - 4 - Z1 - 32B - 0414介紹
GLM家族迎來了新一代開源模型 GLM - 4 - 32B - 0414 系列,擁有320億參數。其性能可與OpenAI的GPT系列和DeepSeek的V3/R1系列相媲美,並支持非常友好的本地部署功能。GLM - 4 - 32B - Base - 0414在15T高質量數據上進行了預訓練,包括大量推理類型的合成數據,為後續強化學習擴展奠定了基礎。在後續訓練階段,除了針對對話場景進行人類偏好對齊外,還使用拒絕採樣和強化學習等技術增強了模型在指令遵循、工程代碼和函數調用方面的性能,強化了代理任務所需的原子能力。GLM - 4 - 32B - 0414在工程代碼、工件生成、函數調用、基於搜索的問答和報告生成等領域取得了良好的效果。在一些基準測試中,甚至可以與GPT - 4o和DeepSeek - V3 - 0324(6710億參數)等更大的模型相媲美。
GLM - Z1 - 32B - 0414 是一個具有 深度思考能力 的推理模型。它基於GLM - 4 - 32B - 0414通過冷啟動和擴展強化學習開發,並在涉及數學、代碼和邏輯的任務上進一步訓練了模型。與基礎模型相比,GLM - Z1 - 32B - 0414顯著提高了數學能力和解決複雜任務的能力。在訓練過程中,還引入了基於成對排名反饋的通用強化學習,進一步增強了模型的通用能力。
GLM - Z1 - Rumination - 32B - 0414 是一個具有 沉思能力 的深度推理模型(以OpenAI的深度研究為基準)。與典型的深度思考模型不同,沉思模型採用更長時間的深度思考來解決更開放和複雜的問題(例如,撰寫兩個城市AI發展的比較分析及其未來發展計劃)。沉思模型在深度思考過程中集成了搜索工具以處理複雜任務,並通過利用多個基於規則的獎勵來指導和擴展端到端強化學習進行訓練。Z1 - Rumination在研究型寫作和複雜檢索任務中表現出顯著的改進。
最後,GLM - Z1 - 9B - 0414 是一個驚喜。採用上述一系列技術訓練了一個90億參數的小型模型,保持了開源傳統。儘管規模較小,但GLM - Z1 - 9B - 0414在數學推理和通用任務中仍表現出出色的能力。其整體性能在同規模的開源模型中已處於領先水平。特別是在資源受限的場景中,該模型在效率和效果之間取得了出色的平衡,為尋求輕量級部署的用戶提供了強大的選擇。
性能
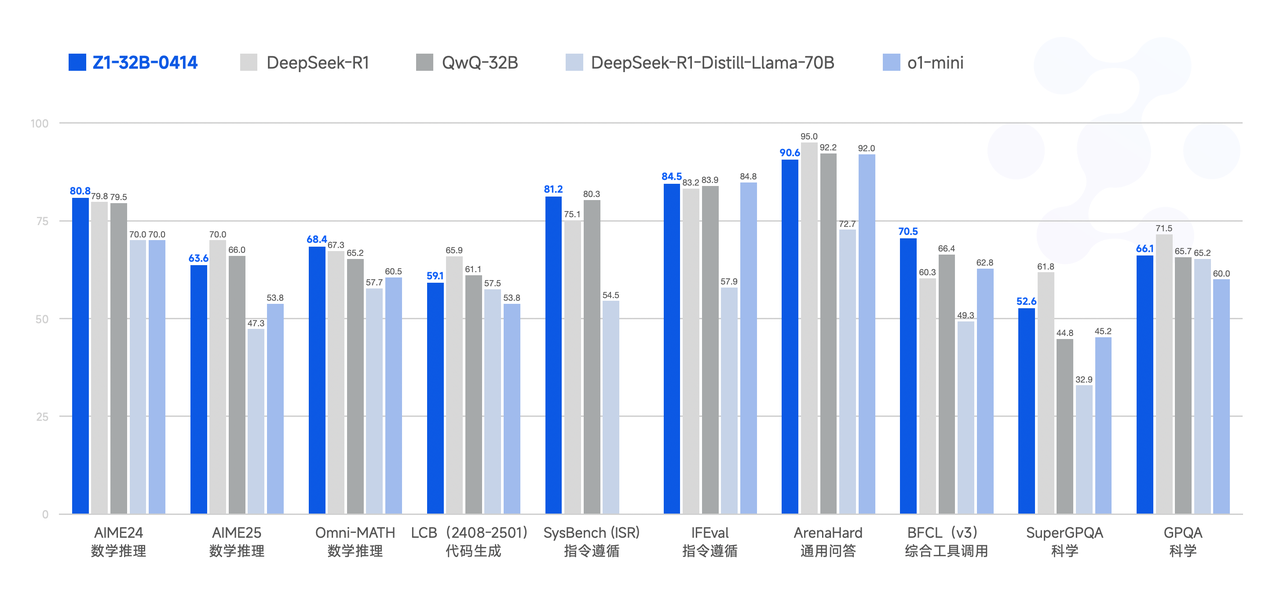
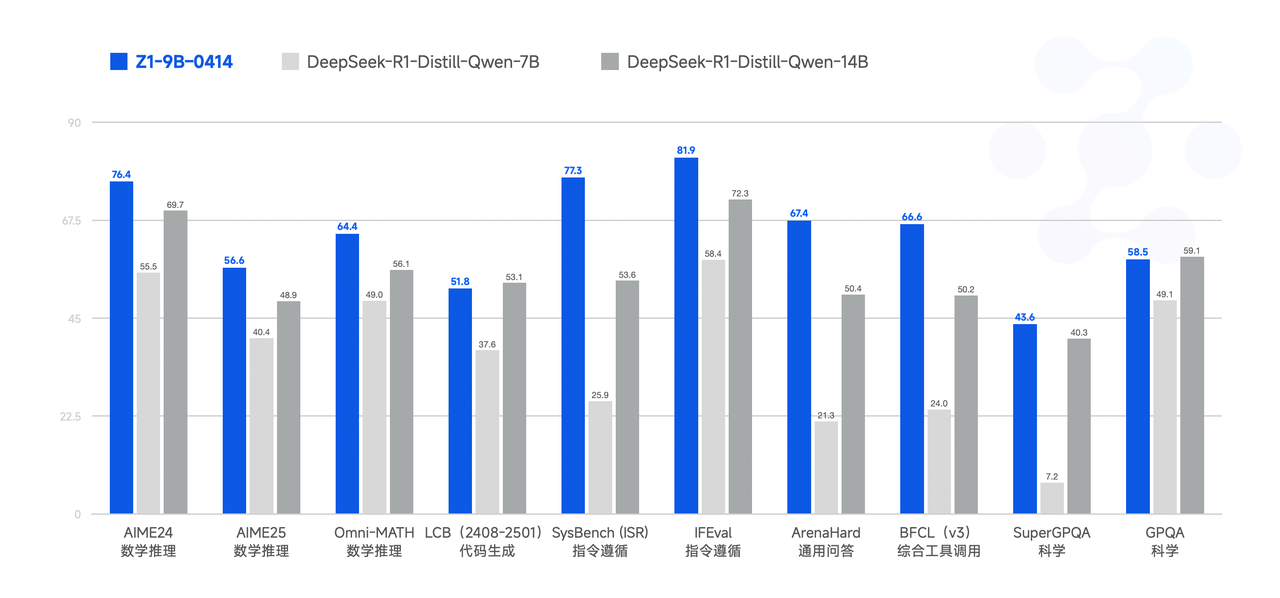
模型使用指南
I. 採樣參數
| 參數 | 推薦值 | 描述 |
|---|---|---|
| temperature | 0.6 | 平衡創造性和穩定性 |
| top_p | 0.95 | 採樣的累積概率閾值 |
| top_k | 40 | 過濾稀有令牌,同時保持多樣性 |
| max_new_tokens | 30000 | 為思考留出足夠的令牌 |
II. 強制思考
- 在 第一行 添加 <think>\n:確保模型在回覆前進行思考。
- 使用
chat_template.jinja時,提示會自動注入以強制執行此行為。
III. 對話歷史修剪
- 僅保留 最終用戶可見的回覆。
- 隱藏的思考內容 不應 保存到歷史記錄中以減少干擾 — 這已在
chat_template.jinja中實現。
IV. 處理長上下文(YaRN)
- 當輸入長度超過 8192個令牌 時,考慮啟用YaRN(Rope縮放)。
- 在支持的框架中,將以下代碼段添加到
config.json中:
"rope_scaling": {
"type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 32768
}
- 靜態YaRN 適用於所有文本。它可能會略微降低短文本的性能,因此按需啟用。
🔧 技術細節
文檔未提及詳細技術細節,暫不提供相關內容。
📄 許可證
本項目採用MIT許可證。
引用
如果你認為我們的工作有用,請考慮引用以下論文:
@misc{glm2024chatglm,
title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools},
author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang},
year={2024},
eprint={2406.12793},
archivePrefix={arXiv},
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
}