🚀 OpenHands Critic Model
OpenHands Critic Model是一個用於研究的模型,在軟件工程基準測試中取得了優異成績。它藉助推理時間縮放和評估模型,在SWE - Bench Verified上達到了先進水平,為解決實際軟件工程挑戰提供了有力支持。
🚀 快速開始
本模型嚴格用於研究,目前還不兼容OpenHands應用程序。有關此模型的完整信息,包括其功能和限制,請參閱我們的詳細博客文章。
你可以通過以下方式體驗OpenHands:
- 使用OpenHands雲服務:最簡單的入門方式是使用我們的全託管雲解決方案,它提供50美元的免費信用額度、無縫的GitHub集成、移動支持以及如上下文壓縮等優化功能,隨時可用。
- 參與開源貢獻:給我們的GitHub倉庫加星、提出問題或發送拉取請求,助力開源人工智能軟件開發的發展。
- 加入我們的社區:在Slack上與我們交流,閱讀我們的文檔,並及時瞭解我們的最新動態。
✨ 主要特性
在SWE - Bench上取得先進成果
OpenHands在SWE - Bench Verified上達到了新的里程碑,取得了先進的成果。
推理時間縮放
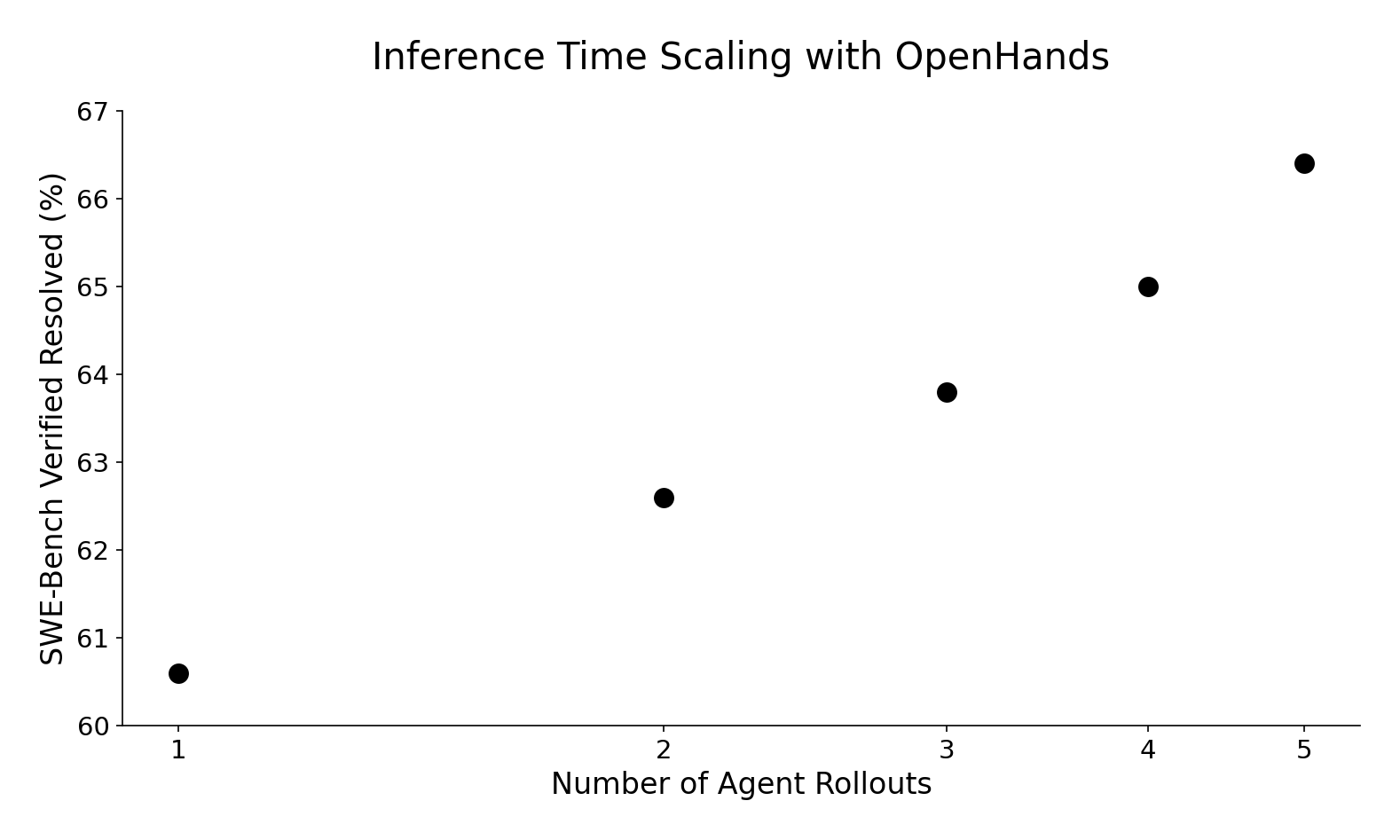
對於具有挑戰性的軟件工程任務,多次嘗試解決方案並選擇最佳方案可以獲得更好的結果。具體步驟如下:
- 對於每個SWE - Bench問題,使用Claude 3.7 Sonnet以採樣溫度1.0多次運行OpenHands代理,生成多個解決方案和代碼補丁。
- 訓練一個“評估模型”,評估每個解決方案並預測其是否為好的解決方案。
- 過濾掉未通過迴歸和重現測試的代碼補丁。
- 從得分最高的軌跡中選擇解決方案作為最終答案。
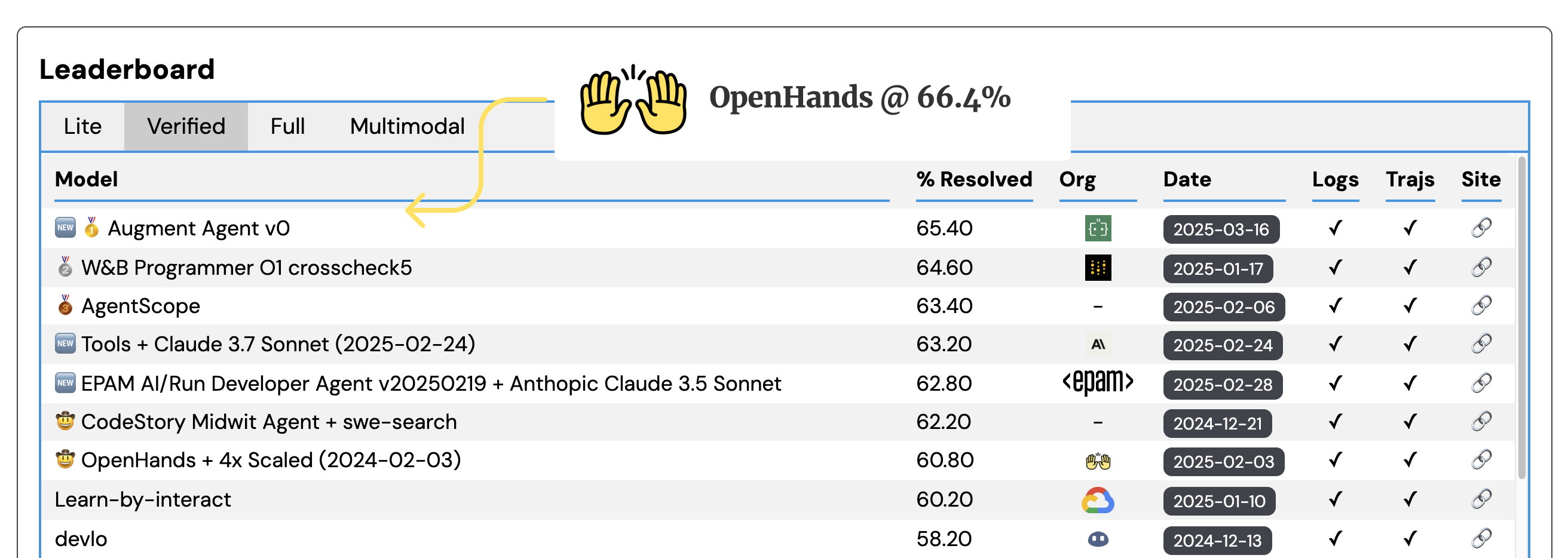
這種推理時間縮放方法使我們在不修改底層代理模型和框架的情況下取得了顯著更好的結果。從單次軌跡推出的60.6%到五次嘗試的66.4%,性能呈對數線性提升,這將使我們的提交在排行榜上名列前茅!
訓練專用評估模型
與基於提示的重排序策略不同,我們訓練了一個專用的評估模型,該模型提供了更有效的結果。訓練過程如下:
- 從[SWE - Gym](https://github.com/SWE - Gym/SWE - Gym)中推出代理軌跡,以避免數據洩漏。
- 實施時間差分(TD)學習目標,將單元測試執行的軌跡級成功信號反向傳播到每個軌跡。
- 在最後一層添加回歸頭以預測獎勵值。
TD學習目標特別強大,因為它有助於模型理解哪些行動對最終結果有貢獻:
$$
r_t = \gamma r_{t + 1}
$$
其中$r_t$是時間步$t$的獎勵(即代理產生的第$t$個動作),$\gamma$是折扣因子。該過程從最終獎勵$r_T$開始,$r_T$由對完整解決方案運行單元測試確定 - 通過所有測試為1,失敗為0。然後將此終端獎勵反向傳播到軌跡中,每個先前步驟都乘以$\gamma$。我們使用$\gamma = 0.99$。
我們使用veRL對[Qwen 2.5 Coder Instruct 32B](https://huggingface.co/Qwen/Qwen2.5 - Coder - 32B - Instruct)進行微調作為評估模型。在推理過程中,我們使用[修改版的vLLM](https://github.com/xingyaoww/vllm/tree/add - token - classification - support)來服務此模型進行評估(有趣的是:OpenHands代理本身編寫了那裡的大部分功能[代碼](https://github.com/vllm - project/vllm/compare/main...xingyaoww:vllm:add - token - classification - support))。
我們將評估模型[公開發布在Hugging Face上](https://huggingface.co/all - hands/openhands - critic - 32b - exp - 20250417),供希望探索其功能或在我們的工作基礎上進行拓展的研究人員使用。
評估模型的優勢和應用前景
- 泛化實用性:基於提示工程的重排序器可以提高基準測試分數,但難以保證在現實世界中的泛化能力。我們相信,有了足夠的數據,訓練有素的評估模型可以推廣到SWE - Bench之外的各種軟件工程場景,使其成為解決日常編碼任務中實際問題的有價值工具。
- 利用中間獎勵進行未來改進:雖然我們目前的實現側重於從多個軌跡中選擇最佳完整解決方案,但每個軌跡中預測的中間獎勵為增強我們的代理能力開闢了令人興奮的可能性。
- 一步前瞻採樣:允許我們在每個步驟評估多個潛在動作,使用評估模型的分數選擇最有前途的前進路徑(實驗性[PR](https://github.com/All - Hands - AI/OpenHands/pull/7770))。
- 即時錯誤恢復:是我們正在探索的另一個領域,評估模型可以識別獎勵下降並幫助代理在解決方案過程中糾正方向([問題](https://github.com/All - Hands - AI/OpenHands/issues/2221))。
📦 安裝指南
暫未提供相關安裝步驟。
💻 使用示例
暫未提供相關代碼示例。
📚 詳細文檔
SWE - Bench和OpenHands
SWE - bench是評估大語言模型(LLMs)解決實際軟件工程挑戰能力的最流行基準。它由GitHub上12個流行Python倉庫的問題和相應的拉取請求組成,要求系統生成代碼補丁以解決指定問題。我們評估的已驗證子集由500個精心挑選的測試用例組成,這些測試用例已由[人類軟件開發人員](https://openai.com/index/introducing - swe - bench - verified/)手動審核,以驗證它們具有適當範圍的單元測試和明確的問題描述。
由於其現實性以及能夠自主解決實際軟件開發挑戰的AI代理可能帶來的巨大好處,它在學術界和工業界被廣泛用作衡量AI編碼代理能力的黃金標準。
我們正在開發[OpenHands](https://github.com/All - Hands - AI/OpenHands)開源軟件開發代理,它在該數據集上的性能目前為60.6%,相當不錯!
🔧 技術細節
評估模型訓練
- 數據來源:從[SWE - Gym](https://github.com/SWE - Gym/SWE - Gym)中推出代理軌跡,避免數據洩漏。
- 學習目標:實施時間差分(TD)學習目標,將單元測試執行的軌跡級成功信號反向傳播到每個軌跡。
- 模型結構:在最後一層添加回歸頭以預測獎勵值。
推理過程
使用[修改版的vLLM](https://github.com/xingyaoww/vllm/tree/add - token - classification - support)來服務評估模型進行評估。
📄 許可證
本模型採用MIT許可證。
📋 模型信息
| 屬性 |
詳情 |
| 模型類型 |
令牌分類 |
| 基礎模型 |
Qwen/Qwen2.5 - Coder - 32B - Instruct |
| 標籤 |
agent、coding |
⚠️ 重要提示
本模型嚴格用於研究,目前還不兼容OpenHands應用程序。
💡 使用建議
如果你對評估模型的能力感興趣或想在我們的工作基礎上進行拓展,可以訪問[Hugging Face上的評估模型](https://huggingface.co/all - hands/openhands - critic - 32b - exp - 20250417)。同時,歡迎參與我們的開源項目,為解決實際軟件工程問題貢獻力量。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

 Transformers 支持多種語言
Transformers 支持多種語言