%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型概述
模型特點
模型能力
使用案例
🚀 Hymba-1.5B-Instruct
Hymba-1.5B-Instruct 是一個基於 15 億參數的模型,它在多種複雜重要任務上表現出色,如數學推理、函數調用和角色扮演等,並且可用於商業用途。
🚀 快速開始
步驟 1:環境搭建
由於 Hymba-1.5B-Instruct 使用了 FlexAttention,它依賴於 Pytorch2.5 和其他相關依賴項,我們提供兩種方式來搭建環境:
- [本地安裝] 使用我們提供的
setup.sh安裝相關包(支持 CUDA 12.1/12.4):
wget --header="Authorization: Bearer YOUR_HF_TOKEN" https://huggingface.co/nvidia/Hymba-1.5B-Base/resolve/main/setup.sh
bash setup.sh
- [Docker] 我們提供了一個已安裝所有 Hymba 依賴項的 Docker 鏡像。你可以使用以下命令下載我們的 Docker 鏡像並啟動容器:
docker pull ghcr.io/tilmto/hymba:v1
docker run --gpus all -v /home/$USER:/home/$USER -it ghcr.io/tilmto/hymba:v1 bash
步驟 2:與 Hymba-1.5B-Instruct 聊天
環境搭建完成後,你可以使用以下腳本與我們的模型進行對話:
from transformers import AutoModelForCausalLM, AutoTokenizer, StopStringCriteria, StoppingCriteriaList
import torch
# 加載分詞器和模型
repo_name = "nvidia/Hymba-1.5B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(repo_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(repo_name, trust_remote_code=True)
model = model.cuda().to(torch.bfloat16)
# 與 Hymba 對話
prompt = input()
messages = [
{"role": "system", "content": "You are a helpful assistant."}
]
messages.append({"role": "user", "content": prompt})
# 應用聊天模板
tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt").to('cuda')
stopping_criteria = StoppingCriteriaList([StopStringCriteria(tokenizer=tokenizer, stop_strings="</s>")])
outputs = model.generate(
tokenized_chat,
max_new_tokens=256,
do_sample=False,
temperature=0.7,
use_cache=True,
stopping_criteria=stopping_criteria
)
input_length = tokenized_chat.shape[1]
response = tokenizer.decode(outputs[0][input_length:], skip_special_tokens=True)
print(f"Model response: {response}")
Hymba-1.5B-Instruct 使用的提示模板如下,該模板已集成到分詞器中,可以使用 tokenizer.apply_chat_template 應用:
<extra_id_0>System
{system prompt}
<extra_id_1>User
<tool> ... </tool>
<context> ... </context>
{prompt}
<extra_id_1>Assistant
<toolcall> ... </toolcall>
<extra_id_1>Tool
{tool response}
<extra_id_1>Assistant\n
✨ 主要特性
- 多任務處理能力:Hymba-1.5B-Instruct 能夠處理多種複雜和重要的任務,如數學推理、函數調用和角色扮演等。
- 高性能表現:該模型在各項任務中均超越了流行的小型語言模型,實現了最高的平均性能。
- 商業可用性:此模型可用於商業用途。
📦 安裝指南
環境搭建
- 本地安裝:使用提供的
setup.sh腳本安裝相關依賴(支持 CUDA 12.1/12.4)。
wget --header="Authorization: Bearer YOUR_HF_TOKEN" https://huggingface.co/nvidia/Hymba-1.5B-Base/resolve/main/setup.sh
bash setup.sh
- Docker 安裝:下載並使用預配置的 Docker 鏡像。
docker pull ghcr.io/tilmto/hymba:v1
docker run --gpus all -v /home/$USER:/home/$USER -it ghcr.io/tilmto/hymba:v1 bash
💻 使用示例
基礎用法
from transformers import AutoModelForCausalLM, AutoTokenizer, StopStringCriteria, StoppingCriteriaList
import torch
# 加載分詞器和模型
repo_name = "nvidia/Hymba-1.5B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(repo_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(repo_name, trust_remote_code=True)
model = model.cuda().to(torch.bfloat16)
# 與 Hymba 對話
prompt = input()
messages = [
{"role": "system", "content": "You are a helpful assistant."}
]
messages.append({"role": "user", "content": prompt})
# 應用聊天模板
tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt").to('cuda')
stopping_criteria = StoppingCriteriaList([StopStringCriteria(tokenizer=tokenizer, stop_strings="</s>")])
outputs = model.generate(
tokenized_chat,
max_new_tokens=256,
do_sample=False,
temperature=0.7,
use_cache=True,
stopping_criteria=stopping_criteria
)
input_length = tokenized_chat.shape[1]
response = tokenizer.decode(outputs[0][input_length:], skip_special_tokens=True)
print(f"Model response: {response}")
📚 詳細文檔
模型概述
Hymba-1.5B-Instruct 是一個 15 億參數的模型,它基於 Hymba-1.5B-Base 進行微調,使用了開源指令數據集和內部收集的合成數據集的組合。該模型通過監督微調(Supervised Fine-Tuning)和直接偏好優化(Direct Preference Optimization)進行微調。
- 模型開發者:NVIDIA
- 模型訓練時間:2024 年 9 月 4 日至 2024 年 11 月 10 日
- 許可證:該模型根據 NVIDIA 開放模型許可協議 發佈。
模型架構
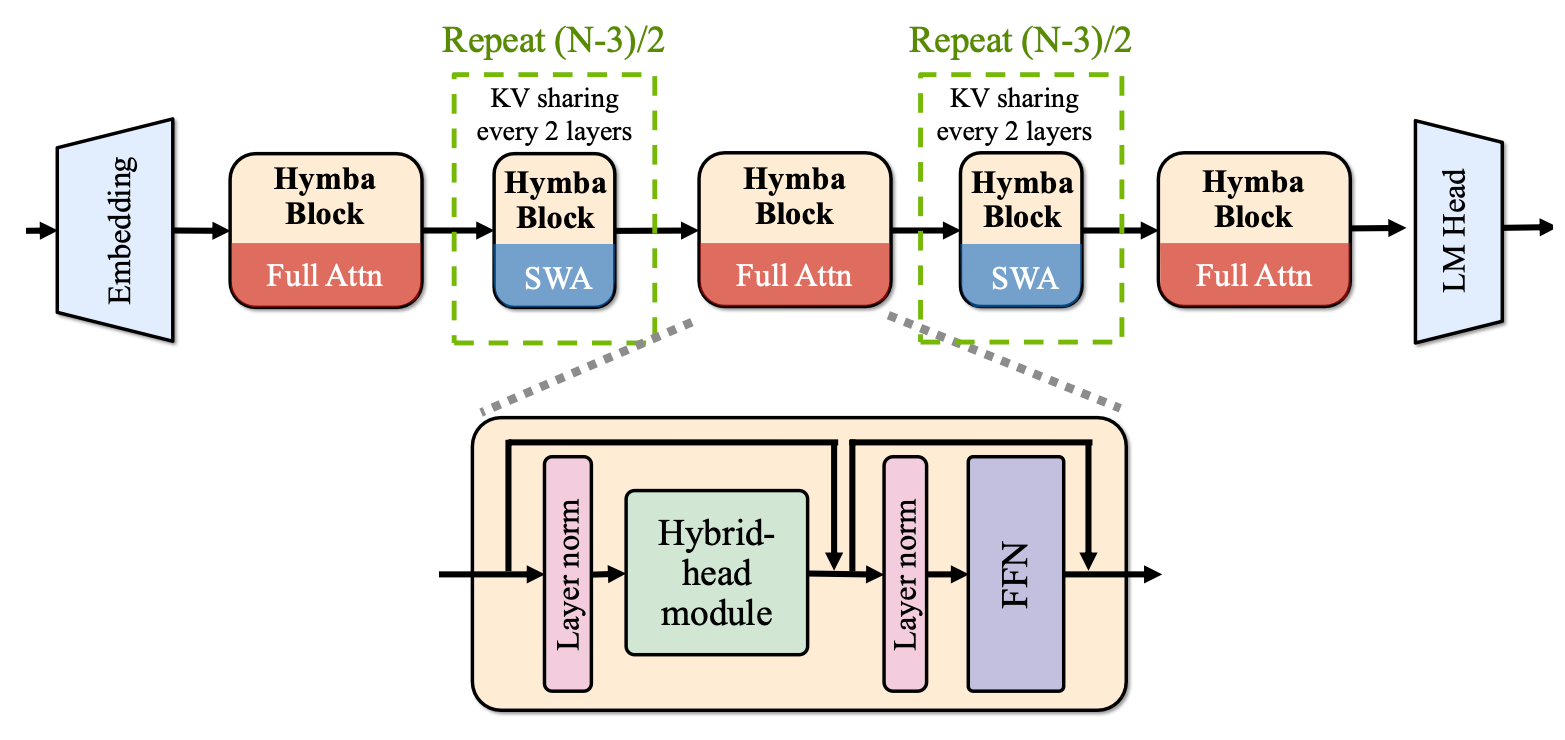
Hymba-1.5B-Instruct 的模型嵌入大小為 1600,有 25 個注意力頭,MLP 中間維度為 5504,總共 32 層,16 個 SSM 狀態,3 個全注意力層,其餘為滑動窗口注意力。與標準的 Transformer 不同,Hymba 中的每個注意力層都有標準注意力頭和 Mamba 頭的混合組合,並且並行運行。此外,它還使用了分組查詢注意力(Grouped-Query Attention,GQA)和旋轉位置嵌入(Rotary Position Embeddings,RoPE)。 該架構的特點包括:
- 融合注意力頭和 SSM 頭:在同一層內融合注意力頭和 SSM 頭,對相同輸入進行並行和互補處理。
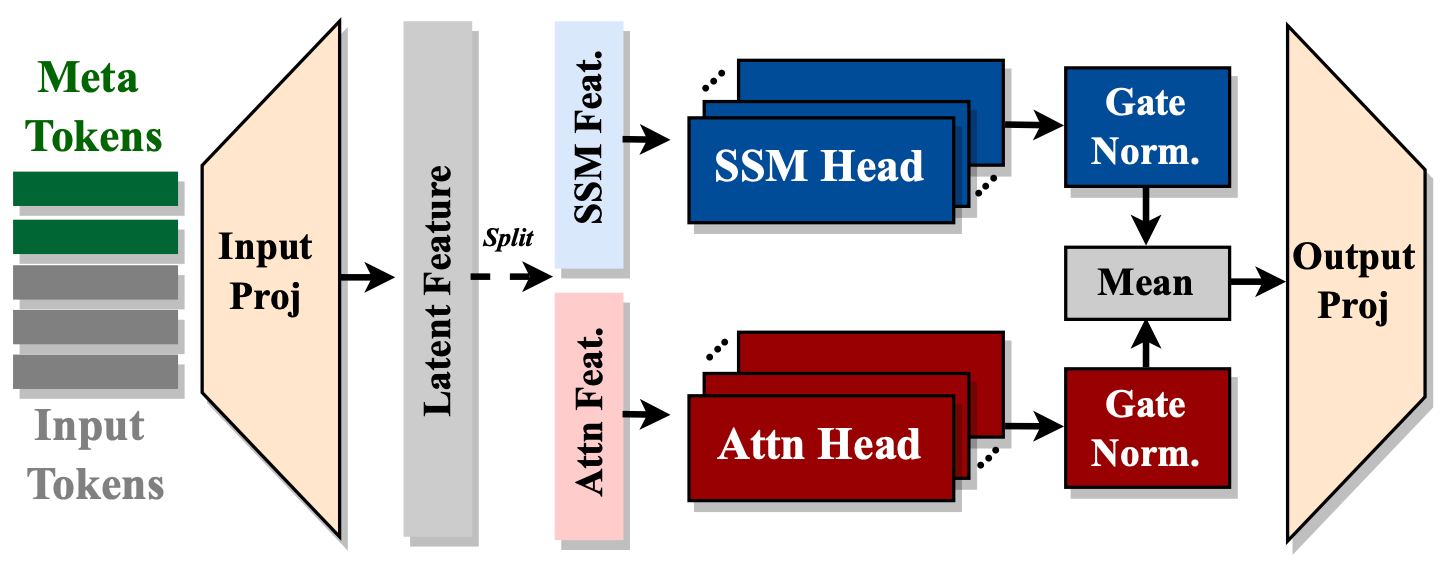
- 引入元令牌:在輸入序列前添加元令牌,與所有後續令牌進行交互,從而存儲重要信息並減輕注意力中的“強制關注”負擔。
- 集成跨層 KV 共享和全局 - 局部注意力:進一步提高內存和計算效率。
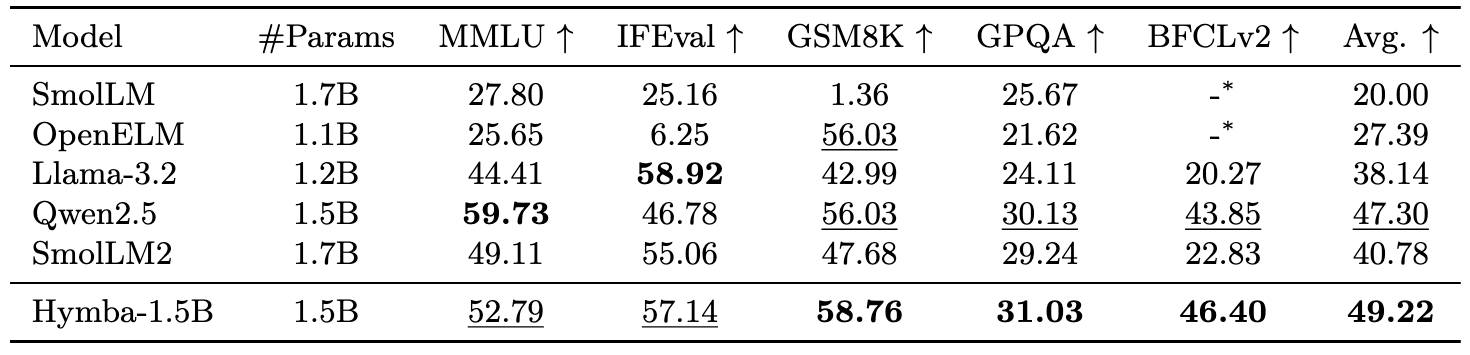
性能亮點
Hymba-1.5B-Instruct 在各項任務中均超越了流行的小型語言模型,實現了最高的平均性能。
模型微調
LMFlow 是一個用於微調大語言模型的完整管道。以下步驟提供了一個如何使用 LMFlow 微調 Hymba-1.5B-Base 模型的示例:
- 使用 Docker
docker pull ghcr.io/tilmto/hymba:v1
docker run --gpus all -v /home/$USER:/home/$USER -it ghcr.io/tilmto/hymba:v1 bash
- 安裝 LMFlow
git clone https://github.com/OptimalScale/LMFlow.git
cd LMFlow
conda create -n lmflow python=3.9 -y
conda activate lmflow
conda install mpi4py
pip install -e .
- 使用以下命令微調模型
cd LMFlow
bash ./scripts/run_finetune_hymba.sh
使用 LMFlow,你還可以在自定義數據集上微調模型。你只需要將數據集轉換為 LMFlow 數據格式。除了全量微調,你還可以使用 DoRA、LoRA、LISA、Flash Attention 等加速技術對 Hymba 進行高效微調。更多詳細信息,請參考 Hymba 的 LMFlow 文檔。
侷限性
該模型在包含有毒語言、不安全內容和社會偏見的數據上進行訓練,這些數據最初是從互聯網上爬取的。因此,該模型可能會放大這些偏見並返回有毒響應,尤其是在輸入有毒提示時。即使提示本身不包含任何明確的冒犯性內容,該模型也可能生成不準確的答案,遺漏關鍵信息,或包含無關或冗餘的文本,產生社會不可接受或不期望的文本。 測試表明,該模型容易受到越獄攻擊。如果在 RAG 或智能體環境中使用此模型,我們建議使用強大的輸出驗證控制,以確保用戶控制的模型輸出的安全風險與預期用例一致。
倫理考慮
NVIDIA 認為可信 AI 是一項共同責任,我們已經制定了政策和實踐,以支持廣泛的 AI 應用開發。當根據我們的服務條款下載或使用該模型時,開發者應與內部模型團隊合作,確保該模型符合相關行業和用例的要求,並解決不可預見的產品濫用問題。 請 在此 報告安全漏洞或 NVIDIA AI 相關問題。
引用
@misc{dong2024hymbahybridheadarchitecturesmall,
title={Hymba: A Hybrid-head Architecture for Small Language Models},
author={Xin Dong and Yonggan Fu and Shizhe Diao and Wonmin Byeon and Zijia Chen and Ameya Sunil Mahabaleshwarkar and Shih-Yang Liu and Matthijs Van Keirsbilck and Min-Hung Chen and Yoshi Suhara and Yingyan Lin and Jan Kautz and Pavlo Molchanov},
year={2024},
eprint={2411.13676},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2411.13676},
}
🔧 技術細節
Hymba-1.5B-Instruct 的模型嵌入大小為 1600,有 25 個注意力頭,MLP 中間維度為 5504,總共 32 層,16 個 SSM 狀態,3 個全注意力層,其餘為滑動窗口注意力。與標準的 Transformer 不同,Hymba 中的每個注意力層都有標準注意力頭和 Mamba 頭的混合組合,並且並行運行。此外,它還使用了分組查詢注意力(Grouped-Query Attention,GQA)和旋轉位置嵌入(Rotary Position Embeddings,RoPE)。該架構通過融合注意力頭和 SSM 頭、引入元令牌以及集成跨層 KV 共享和全局 - 局部注意力等方式,提高了模型的性能和效率。
📄 許可證
該模型根據 NVIDIA 開放模型許可協議 發佈。
📋 模型信息
| 屬性 | 詳情 |
|---|---|
| 基礎模型 | nvidia/Hymba-1.5B-Base |
| 庫名稱 | transformers |
| 許可證 | 其他 |
| 許可證名稱 | nvidia-open-model-license |
| 許可證鏈接 | https://developer.download.nvidia.com/licenses/nvidia-open-model-license-agreement-june-2024.pdf |
| 任務類型 | 文本生成 |
⚠️ 重要提示
該模型在包含有毒語言、不安全內容和社會偏見的數據上進行訓練,可能會放大這些偏見並返回有毒響應。此外,該模型容易受到越獄攻擊,在使用時建議使用強大的輸出驗證控制。
💡 使用建議
當使用該模型時,開發者應與內部模型團隊合作,確保該模型符合相關行業和用例的要求,並解決不可預見的產品濫用問題。同時,建議在 RAG 或智能體環境中使用強大的輸出驗證控制,以確保安全。