🚀 Kandinsky 2.2
Kandinsky繼承了Dall - E 2和潛在擴散模型的最佳實踐,並引入了一些新的理念。它利用CLIP模型作為文本和圖像編碼器,並在CLIP模態的潛在空間之間採用擴散圖像先驗(映射)。這種方法提升了模型的視覺表現,為圖像融合和文本引導的圖像操作開闢了新的可能性。
🚀 快速開始
Kandinsky 2.2可在diffusers中使用!
pip install diffusers transformers accelerate
✨ 主要特性
Kandinsky繼承了Dall - E 2和潛在擴散模型的優點,同時引入新思想。它使用CLIP模型進行文本和圖像編碼,並通過擴散圖像先驗提升視覺性能,在圖像與文本融合及文本引導的圖像操作方面具有獨特優勢。
💻 使用示例
基礎用法
文本引導的圖像修復生成
from diffusers import AutoPipelineForInpainting
from diffusers.utils import load_image
import torch
import numpy as np
pipe = AutoPipelineForInpainting.from_pretrained("kandinsky-community/kandinsky-2-2-decoder-inpaint", torch_dtype=torch.float16)
pipe.enable_model_cpu_offload()
prompt = "a hat"
init_image = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/cat.png"
)
mask = np.zeros((768, 768), dtype=np.float32)
mask[:250, 250:-250] = 1
out = pipe(
prompt=prompt,
image=init_image,
mask_image=mask,
height=768,
width=768,
num_inference_steps=150,
)
image = out.images[0]
image.save("cat_with_hat.png")

高級用法
Kandinsky圖像修復管道的重大變更
我們在以下拉取請求中對Kandinsky圖像修復管道進行了重大更改:https://github.com/huggingface/diffusers/pull/4207。之前,我們接受的掩碼格式是黑色像素表示被屏蔽區域,這與diffusers中的所有其他管道不一致。現在,我們在Kandinsky中更改了掩碼格式,使用白色像素表示被屏蔽區域。
如果您在生產環境中使用Kandinsky圖像修復,請將掩碼更新為以下形式:
import PIL.ImageOps
mask = PIL.ImageOps.invert(mask)
mask = 1 - mask
🔧 技術細節
概述
Kandinsky 2.1是一個基於unCLIP和潛在擴散的文本條件擴散模型,由基於Transformer的圖像先驗模型、Unet擴散模型和解碼器組成。
模型架構如下圖所示 - 左側的圖表描述了訓練圖像先驗模型的過程,中間的圖是文本到圖像的生成過程,右側的圖是圖像插值。
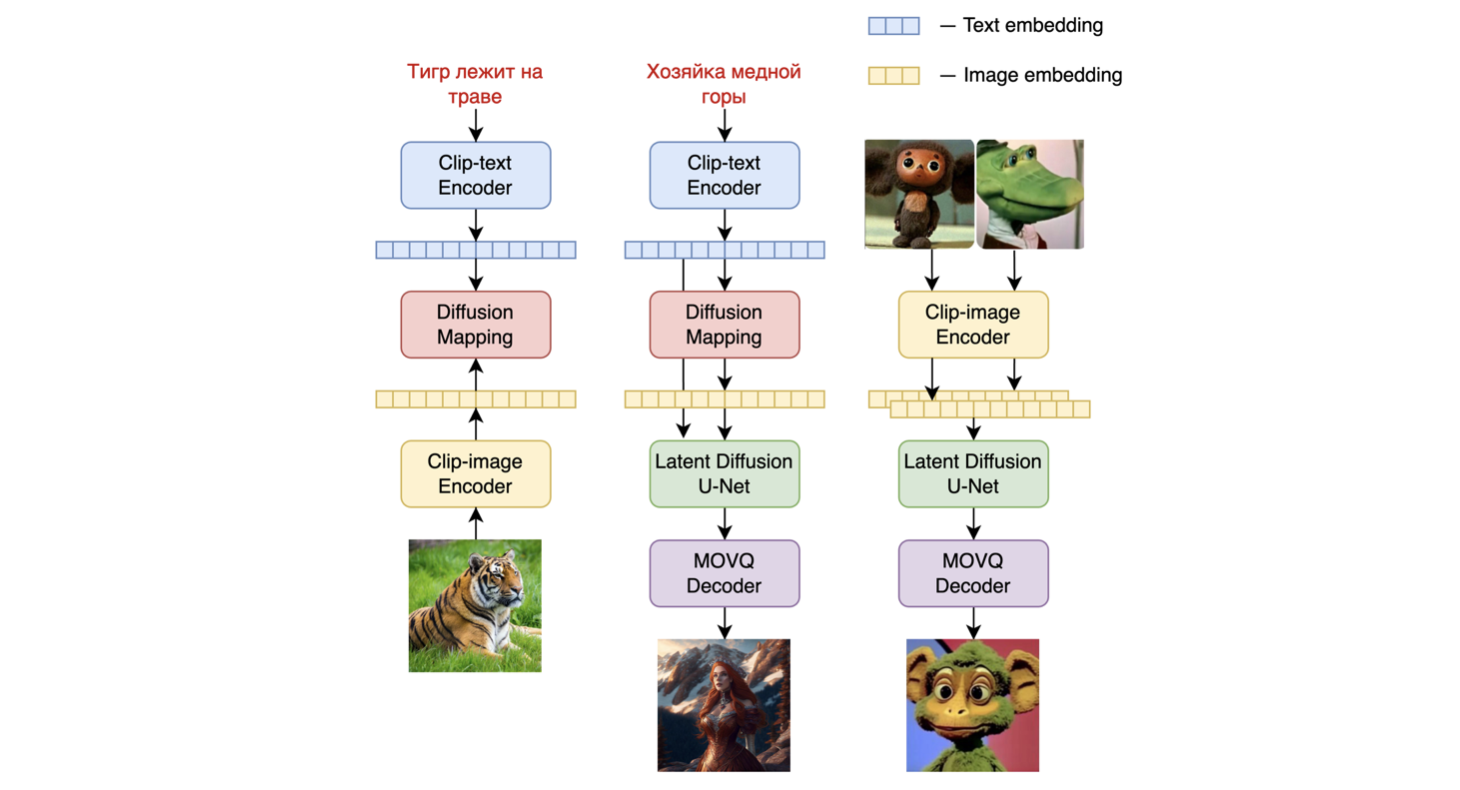
具體而言,圖像先驗模型在使用預訓練的[mCLIP模型](https://huggingface.co/M - CLIP/XLM - Roberta - Large - Vit - L - 14)生成的CLIP文本和圖像嵌入上進行訓練。訓練好的圖像先驗模型用於為輸入文本提示生成mCLIP圖像嵌入。輸入文本提示及其mCLIP圖像嵌入都用於擴散過程。[MoVQGAN](https://openreview.net/forum?id=Qb - AoSw4Jnm)模型作為模型的最後一個模塊,將潛在表示解碼為實際圖像。
詳細信息
模型的圖像先驗訓練在LAION Improved Aesthetics數據集上進行,然後在[LAION HighRes數據](https://huggingface.co/datasets/laion/laion - high - resolution)上進行微調。
主要的文本到圖像擴散模型基於來自[LAION HighRes數據集](https://huggingface.co/datasets/laion/laion - high - resolution)的1.7億個文本 - 圖像對進行訓練(一個重要條件是存在分辨率至少為768x768的圖像)。使用1.7億個文本 - 圖像對是因為我們保留了Kandinsky 2.0的Unet擴散塊,這使我們無需從頭開始訓練它。此外,在微調階段,使用了一個從開放源單獨收集的包含200萬個非常高質量的高分辨率圖像及其描述的數據集(COYO、動漫、俄羅斯地標等)。
評估
我們在COCO_30k數據集上以零樣本模式定量測量Kandinsky 2.1的性能。下表展示了FID值。
生成模型在COCO_30k上的FID指標值
|
FID (30k) |
| eDiff - I (2022) |
6.95 |
| Image (2022) |
7.27 |
| Kandinsky 2.1 (2023) |
8.21 |
| Stable Diffusion 2.1 (2022) |
8.59 |
| GigaGAN, 512x512 (2023) |
9.09 |
| DALL - E 2 (2022) |
10.39 |
| GLIDE (2022) |
12.24 |
| Kandinsky 1.0 (2022) |
15.40 |
| DALL - E (2021) |
17.89 |
| Kandinsky 2.0 (2022) |
20.00 |
| GLIGEN (2022) |
21.04 |
更多信息,請參考即將發佈的技術報告。
📄 許可證
本項目採用Apache 2.0許可證。
📚 引用
如果您在研究中發現此倉庫有用,請引用:
@misc{kandinsky 2.2,
title = {kandinsky 2.2},
author = {Arseniy Shakhmatov, Anton Razzhigaev, Aleksandr Nikolich, Vladimir Arkhipkin, Igor Pavlov, Andrey Kuznetsov, Denis Dimitrov},
year = {2023},
howpublished = {},
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 支持多種語言
Transformers 支持多種語言