🚀 用於卡通化的指令調優穩定擴散模型(微調版)
本模型是 Stable Diffusion (v1.5) 的“指令調優”版本。它是在現有的 InstructPix2Pix 檢查點基礎上進行微調得到的。
🚀 快速開始
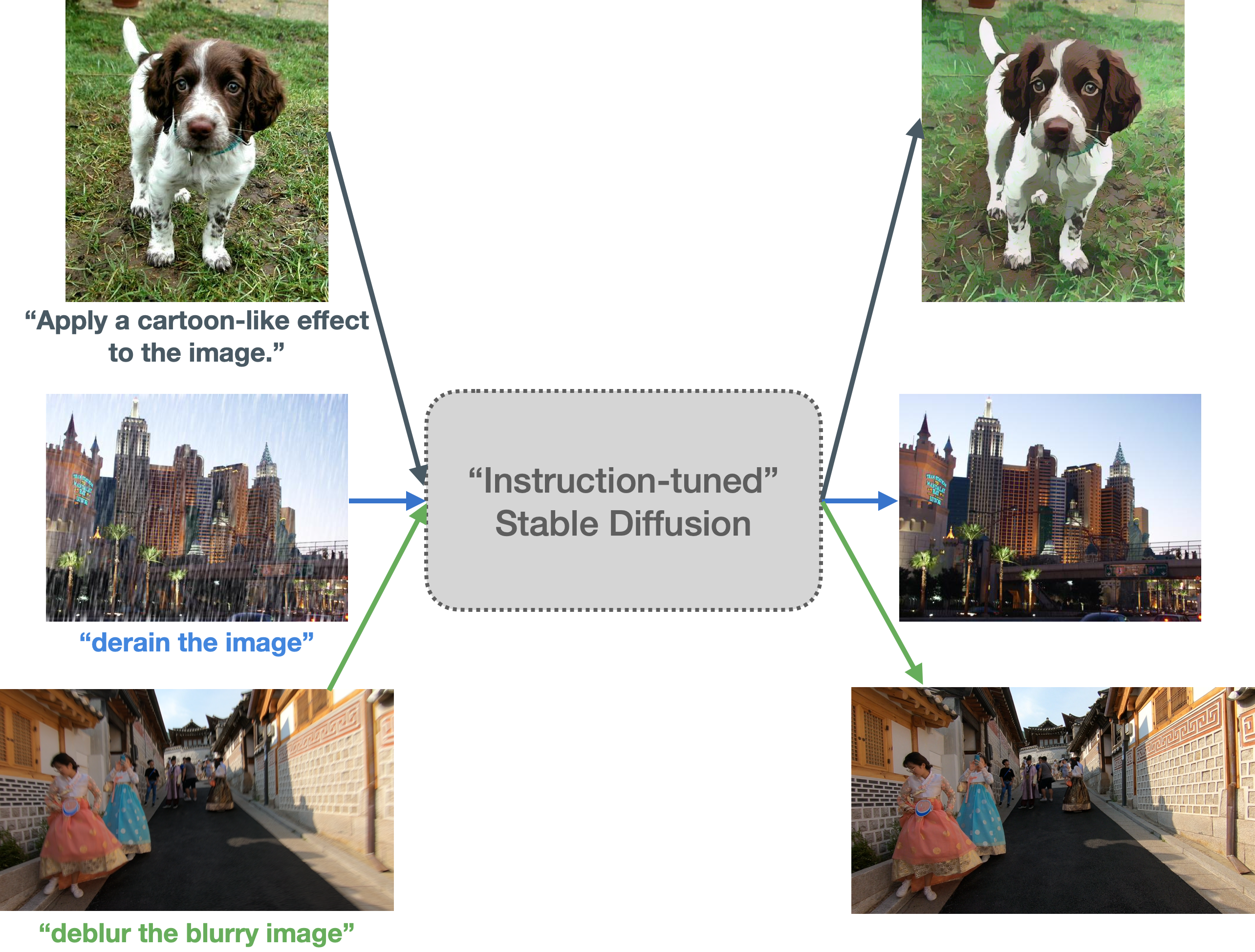
本模型可用於根據輸入圖像和輸入提示進行卡通化處理。以下是使用該模型的示例代碼:
import torch
from diffusers import StableDiffusionInstructPix2PixPipeline
from diffusers.utils import load_image
model_id = "instruction-tuning-sd/cartoonizer"
pipeline = StableDiffusionInstructPix2PixPipeline.from_pretrained(
model_id, torch_dtype=torch.float16, use_auth_token=True
).to("cuda")
image_path = "https://hf.co/datasets/diffusers/diffusers-images-docs/resolve/main/mountain.png"
image = load_image(image_path)
image = pipeline("Cartoonize the following image", image=image).images[0]
image.save("image.png")
✨ 主要特性
此模型的動機部分源自 FLAN,部分源自 InstructPix2Pix。主要思路是先創建一個指令提示數據集(如我們的博客所述),然後進行 InstructPix2Pix 風格的訓練。最終目標是讓 Stable Diffusion 更好地遵循涉及圖像變換相關操作的特定指令。
更多信息請參考 此文章。
📚 詳細文檔
訓練過程和結果
訓練是在 instruction-tuning-sd/cartoonization 數據集上進行的。更多信息請參考 此倉庫。訓練日誌可在 這裡 找到。
以下是該模型生成的一些結果:

預期用途和侷限性
你可以使用該模型根據輸入圖像和輸入提示進行卡通化處理。關於侷限性、誤用、惡意使用、超出範圍使用的注意事項,請參考 此模型卡片。
📄 許可證
本項目採用 MIT 許可證。
📚 引用
FLAN
@inproceedings{
wei2022finetuned,
title={Finetuned Language Models are Zero-Shot Learners},
author={Jason Wei and Maarten Bosma and Vincent Zhao and Kelvin Guu and Adams Wei Yu and Brian Lester and Nan Du and Andrew M. Dai and Quoc V Le},
booktitle={International Conference on Learning Representations},
year={2022},
url={https://openreview.net/forum?id=gEZrGCozdqR}
}
InstructPix2Pix
@InProceedings{
brooks2022instructpix2pix,
author = {Brooks, Tim and Holynski, Aleksander and Efros, Alexei A.},
title = {InstructPix2Pix: Learning to Follow Image Editing Instructions},
booktitle = {CVPR},
year = {2023},
}
Stable Diffusion 指令調優博客
@article{
Paul2023instruction-tuning-sd,
author = {Paul, Sayak},
title = {Instruction-tuning Stable Diffusion with InstructPix2Pix},
journal = {Hugging Face Blog},
year = {2023},
note = {https://huggingface.co/blog/instruction-tuning-sd},
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多種語言
Transformers 支持多種語言