🚀 SigLIP(大型模型)
SigLIP是一個多模態模型,在圖像 - 文本預訓練方面表現出色。它採用了更優的損失函數,能有效提升模型性能,可用於零樣本圖像分類和圖像 - 文本檢索等任務。
🚀 快速開始
SigLIP模型在分辨率為256x256的WebLi數據集上進行了預訓練。它由Zhai等人在論文Sigmoid Loss for Language Image Pre - Training中提出,並首次在[此倉庫](https://github.com/google - research/big_vision)中發佈。
聲明:發佈SigLIP的團隊並未為該模型編寫模型卡片,此模型卡片由Hugging Face團隊編寫。
✨ 主要特性
SigLIP是基於CLIP的多模態模型,採用了更優的損失函數。Sigmoid損失僅在圖像 - 文本對上操作,無需對成對相似度進行全局歸一化。這不僅允許進一步擴大批量大小,而且在小批量大小下也能表現更好。
一位作者對SigLIP的簡要總結可在此處找到。
📚 詳細文檔
預期用途和限制
你可以將原始模型用於零樣本圖像分類和圖像 - 文本檢索等任務。請查看模型中心,以查找你感興趣任務的其他版本。
如何使用
以下是如何使用此模型進行零樣本圖像分類的示例:
基礎用法
from PIL import Image
import requests
from transformers import AutoProcessor, AutoModel
import torch
model = AutoModel.from_pretrained("google/siglip-base-patch16-256")
processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-256")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = ["a photo of 2 cats", "a photo of 2 dogs"]
inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image
probs = torch.sigmoid(logits_per_image)
print(f"{probs[0][0]:.1%} that image 0 is '{texts[0]}'")
高級用法
from transformers import pipeline
from PIL import Image
import requests
image_classifier = pipeline(task="zero-shot-image-classification", model="google/siglip-base-patch16-256")
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
outputs = image_classifier(image, candidate_labels=["2 cats", "a plane", "a remote"])
outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
print(outputs)
更多代碼示例請參考文檔。
🔧 技術細節
訓練數據
SigLIP在WebLI數據集的英文圖像 - 文本對上進行預訓練(Chen等人, 2023)。
預處理
圖像被調整大小/重新縮放至相同分辨率(256x256),並在RGB通道上進行歸一化,均值為(0.5, 0.5, 0.5),標準差為(0.5, 0.5, 0.5)。
文本被分詞並填充到相同長度(64個標記)。
計算資源
該模型在16個TPU - v4芯片上訓練了三天。
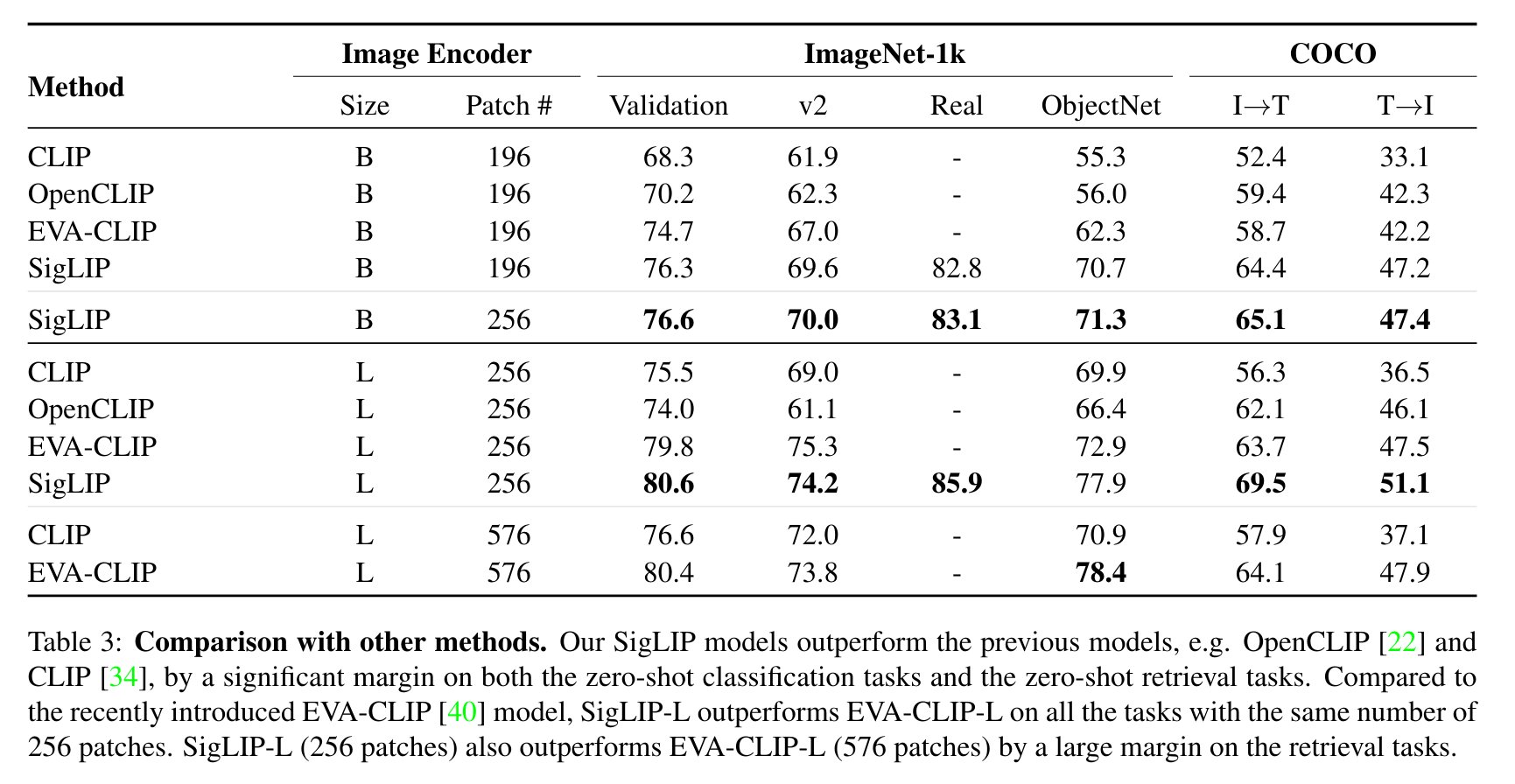
📊 評估結果
以下是SigLIP與CLIP的評估對比(取自論文)。
引用信息
@misc{zhai2023sigmoid,
title={Sigmoid Loss for Language Image Pre-Training},
author={Xiaohua Zhai and Basil Mustafa and Alexander Kolesnikov and Lucas Beyer},
year={2023},
eprint={2303.15343},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
📄 許可證
本模型採用Apache - 2.0許可證。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多種語言
Transformers 支持多種語言