🚀 LaMini-GPT-1.5B
LaMini-GPT-1.5B是LaMini-LM模型系列中的一員,該模型基於大規模指令進行蒸餾,能有效完成自然語言指令響應任務,在多種NLP下游任務中表現出色。


本模型是論文 "LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions" 中LaMini-LM模型系列的一部分。它是 gpt2-xl 在 LaMini-instruction 數據集 上的微調版本,該數據集包含258萬個用於指令微調的樣本。有關我們數據集的更多信息,請參考 項目倉庫。
你可以查看LaMini-LM系列的其他模型,帶有 ✩ 的模型在其規模/架構下具有最佳的整體性能,因此我們推薦使用它們。更多細節可在我們的論文中查看。
🚀 快速開始
預期用途
我們建議使用該模型來響應自然語言編寫的人類指令。由於這個僅解碼器模型是使用包裝文本進行微調的,我們建議使用相同的包裝文本以獲得最佳性能。請參考右側的示例或下面的代碼。
我們現在向你展示如何使用HuggingFace的 pipeline() 加載和使用我們的模型。
from transformers import pipeline
checkpoint = "{model_name}"
model = pipeline('text-generation', model = checkpoint)
instruction = 'Please let me know your thoughts on the given place and why you think it deserves to be visited: \n"Barcelona, Spain"'
input_prompt = f"Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Response:"
generated_text = model(input_prompt, max_length=512, do_sample=True)[0]['generated_text']
print("Response", generated_text)
📚 詳細文檔
訓練過程
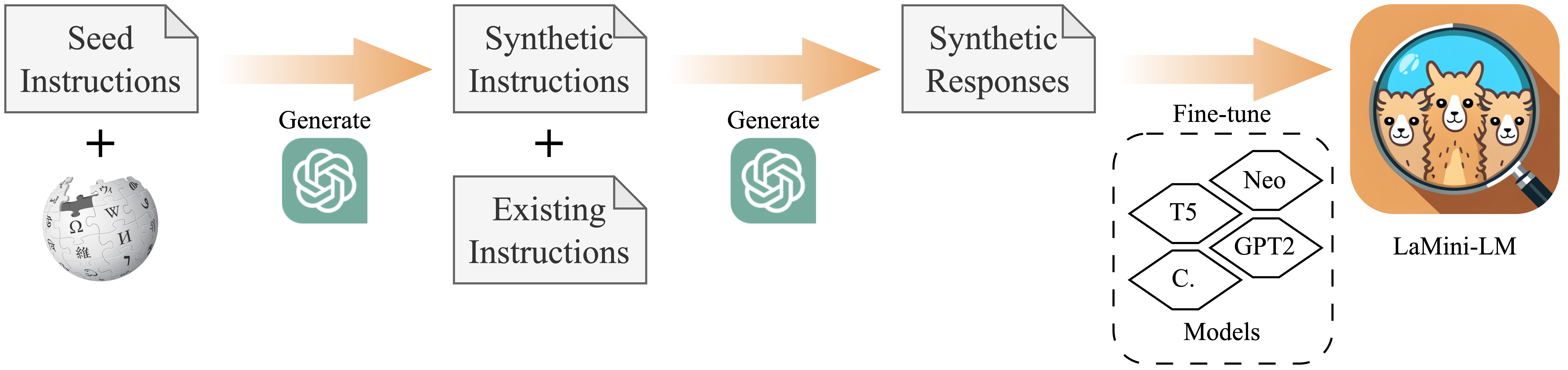
我們使用 gpt2-xl 進行初始化,並在我們的 LaMini-instruction 數據集 上對其進行微調。其總參數數量為15億。
訓練超參數
文檔暫未提供訓練超參數的具體內容。
評估
我們進行了兩組評估:對下游NLP任務的自動評估和對面向用戶指令的人工評估。更多詳細信息,請參考我們的 論文。
侷限性
需要更多信息。
📄 許可證
本模型採用CC By NC 4.0許可證。
📖 引用
@article{lamini-lm,
author = {Minghao Wu and
Abdul Waheed and
Chiyu Zhang and
Muhammad Abdul-Mageed and
Alham Fikri Aji
},
title = {LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions},
journal = {CoRR},
volume = {abs/2304.14402},
year = {2023},
url = {https://arxiv.org/abs/2304.14402},
eprinttype = {arXiv},
eprint = {2304.14402}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多種語言
Transformers 支持多種語言