🚀 🐋 Mistral-7B-OpenOrca 🐋
Mistral-7B-OpenOrca 是基於 Mistral 7B 模型,使用 OpenOrca 數據集進行微調得到的大語言模型。它在多個評測基準中表現出色,在小於 30B 的模型中排名第一,甚至能在性能上媲美 Llama2-70b-chat,且能在普通消費級 GPU 上全加速運行。


🚀 快速開始
如果你想立即體驗該模型,可訪問:https://huggingface.co/spaces/Open-Orca/Mistral-7B-OpenOrca ,這裡使用了快速 GPU 且模型未進行量化。
若想可視化完整(預過濾)數據集,可查看 Nomic Atlas Map。

✨ 主要特性
- 高性能:在發佈時,在小於 30B 的所有模型中,該模型在 HuggingFace 排行榜評估中排名第一,超越了所有其他 7B 和 13B 模型。
- 全開源:這是一個完全開源的模型,具有突破性的性能,甚至能在普通消費級 GPU 上全加速運行。
- 多基準領先:在 AGIEval、BigBench-Hard、GPT4ALL 排行榜、MT-Bench 等多個評測基準中均有出色表現。
📦 安裝指南
由於 Mistral 的支持尚未發佈到 PyPI,你需要安裝 Transformers 的開發快照:
pip install git+https://github.com/huggingface/transformers
💻 使用示例
基礎用法
chat = [
{"role": "system", "content": "You are MistralOrca, a large language model trained by Alignment Lab AI. Write out your reasoning step-by-step to be sure you get the right answers!"},
{"role": "user", "content": "How are you?"},
{"role": "assistant", "content": "I am doing well!"},
{"role": "user", "content": "Please tell me about how mistral winds have attracted super-orcas."},
]
tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
上述代碼將輸出:
<|im_start|>system
You are MistralOrca, a large language model trained by Alignment Lab AI. Write out your reasoning step-by-step to be sure you get the right answers!
<|im_end|>
<|im_start|>user
How are you?<|im_end|>
<|im_start|>assistant
I am doing well!<|im_end|>
<|im_start|>user
Please tell me about how mistral winds have attracted super-orcas.<|im_end|>
<|im_start|>assistant
如果你使用 tokenize=True 和 return_tensors="pt",則會得到一個經過分詞和格式化的對話,可直接傳遞給 model.generate()。
高級用法
推理詳情可查看 此筆記本。
📚 詳細文檔
量化模型
該模型的量化版本由 TheBloke 慷慨提供:
- AWQ: https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-AWQ
- GPTQ: https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GPTQ
- GGUF: https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GGUF
提示模板
模型使用 OpenAI 的聊天標記語言 (ChatML) 格式,並添加了 <|im_start|> 和 <|im_end|> 標記以支持該格式。
這意味著,例如在 oobabooga 中,“MPT-Chat” 指令模板應該可以使用,因為它也使用了 ChatML。
這種格式化也可以通過預定義的 Transformers 聊天模板 獲得,這意味著可以使用 apply_chat_template() 方法為你格式化消息列表。
評估
HuggingFace 排行榜性能
使用 HuggingFace 排行榜的方法和工具進行評估,發現該模型在基礎模型上有顯著改進。在 HuggingFace 排行榜評估中達到了基礎模型性能的 106%,平均分為 65.84。
發佈時,該模型擊敗了所有 7B 和 13B 模型,其性能也是 Llama2-70b-chat 的 98.6%。
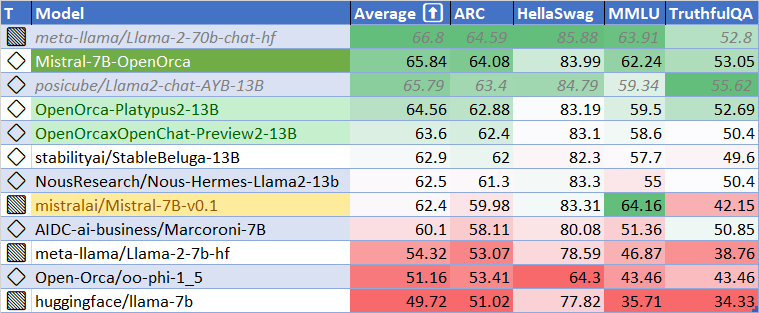
| 指標 |
值 |
| MMLU (5-shot) |
62.24 |
| ARC (25-shot) |
64.08 |
| HellaSwag (10-shot) |
83.99 |
| TruthfulQA (0-shot) |
53.05 |
| 平均分 |
65.84 |
使用 語言模型評估工具包 運行上述基準測試,使用的版本與 HuggingFace LLM 排行榜相同。
AGIEval 性能
與基礎 Mistral-7B 模型(使用 LM 評估工具包)相比,在 AGI 評估中達到了基礎模型性能的 129%,平均分為 0.397。同時,也顯著優於官方 mistralai/Mistral-7B-Instruct-v0.1 微調版本,達到了其性能的 119%。

BigBench-Hard 性能
在 BigBench-Hard 評估中達到了基礎模型性能的 119%,平均分為 0.416。

GPT4ALL 排行榜性能
與之前的版本相比略有優勢,再次位居排行榜榜首,平均分為 72.38。

MT-Bench 性能
MT-Bench 使用 GPT-4 作為模型響應質量的評判標準,涵蓋了廣泛的挑戰。該模型的性能與 Llama2-70b-chat 相當,平均分為 6.86。

數據集
使用了 OpenOrca 數據集中經過精心挑選和過濾的大部分 GPT-4 增強數據,該數據集旨在重現 Orca 研究論文數據集。
訓練
使用 8 個 A6000 GPU 進行了 62 小時的訓練,在一次訓練運行中對數據集完成了 4 個週期的全微調。成本約為 400 美元。
🔧 技術細節
- 模型類型:基於 Mistral 7B 微調的大語言模型
- 訓練數據:OpenOrca 數據集中經過篩選的 GPT-4 增強數據
- 訓練環境:8x A6000 GPUs,訓練時長 62 小時,完成 4 個週期的全微調
📄 許可證
本項目採用 apache-2.0 許可證。
📖 引用
@software{lian2023mistralorca1
title = {MistralOrca: Mistral-7B Model Instruct-tuned on Filtered OpenOrcaV1 GPT-4 Dataset},
author = {Wing Lian and Bleys Goodson and Guan Wang and Eugene Pentland and Austin Cook and Chanvichet Vong and "Teknium"},
year = {2023},
publisher = {HuggingFace},
journal = {HuggingFace repository},
howpublished = {\url{https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca},
}
@misc{mukherjee2023orca,
title={Orca: Progressive Learning from Complex Explanation Traces of GPT-4},
author={Subhabrata Mukherjee and Arindam Mitra and Ganesh Jawahar and Sahaj Agarwal and Hamid Palangi and Ahmed Awadallah},
year={2023},
eprint={2306.02707},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{longpre2023flan,
title={The Flan Collection: Designing Data and Methods for Effective Instruction Tuning},
author={Shayne Longpre and Le Hou and Tu Vu and Albert Webson and Hyung Won Chung and Yi Tay and Denny Zhou and Quoc V. Le and Barret Zoph and Jason Wei and Adam Roberts},
year={2023},
eprint={2301.13688},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多種語言
Transformers 支持多種語言