%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型概述
模型特點
模型能力
使用案例
🚀 Bielik-7B-Instruct-v0.1
Bielik-7B-Instruct-v0.1 是 Bielik-7B-v0.1 的指令微調版本。該模型是開源科學項目 SpeakLeash 與高性能計算中心 ACK Cyfronet AGH 獨特合作的成果。它基於 SpeakLeash 團隊精心挑選和處理的波蘭語文本語料庫進行開發和訓練,藉助了波蘭的大規模計算基礎設施,特別是 PLGrid 環境中的 ACK Cyfronet AGH 高性能計算中心。Bielik-7B-Instruct-v0.1 的創建和訓練得到了計算資助(編號 PLG/2024/016951),在 Athena 和 Helios 超級計算機上進行,得以利用大規模機器學習過程所需的前沿技術和計算資源。因此,該模型在理解和處理波蘭語方面表現出色,能夠提供準確的響應,並高精度地執行各種語言任務。
🎥 演示:https://huggingface.co/spaces/speakleash/Bielik-7B-Instruct-v0.1
🗣️ 聊天競技場*:https://arena.speakleash.org.pl/
* 聊天競技場是一個用於測試和比較不同人工智能語言模型的平臺,用戶可以評估它們的性能和質量。

✨ 主要特性
- 波蘭語處理能力強:基於波蘭語文本語料庫訓練,能精準理解和處理波蘭語。
- 多數據集訓練:使用了波蘭語和英語的指令數據集進行訓練。
- 採用改進策略:運用加權標記級別損失、自適應學習率和掩碼用戶指令等策略提升性能。
- 多種版本支持:提供量化版本和適用於 Apple Silicon 的 MLX 版本。
📚 詳細文檔
模型
SpeakLeash 團隊正在開發自己的波蘭語指令集,並由註釋人員不斷擴展和完善。其中一部分經過人工驗證和修正的指令已用於訓練。此外,由於高質量的波蘭語指令有限,還使用了公開可用的英語指令集 - OpenHermes-2.5 和 orca-math-word-problems-200k,這些指令佔訓練所用指令的一半。由於指令質量參差不齊,導致模型性能有所下降。為了在利用這些數據集的同時解決這個問題,引入了以下改進措施:
- 加權標記級別損失:受 離線強化學習 和 C-RLFT 啟發的策略。
- 自適應學習率:受 學習率與批量大小關係研究 啟發。
- 掩碼用戶指令
Bielik-7B-Instruct-v0.1 使用了由 Krzysztof Ociepa 實現的原創開源框架 ALLaMo 進行訓練。該框架允許用戶以快速高效的方式訓練與 LLaMA 和 Mistral 架構相似的語言模型。
模型描述:
| 屬性 | 詳情 |
|---|---|
| 開發者 | SpeakLeash |
| 語言 | 波蘭語 |
| 模型類型 | 因果解碼器 |
| 微調基礎模型 | Bielik-7B-v0.1 |
| 許可證 | CC BY NC 4.0(非商業用途) |
| 模型引用 | speakleash:e38140bea0d48f1218540800bbc67e89 |
訓練
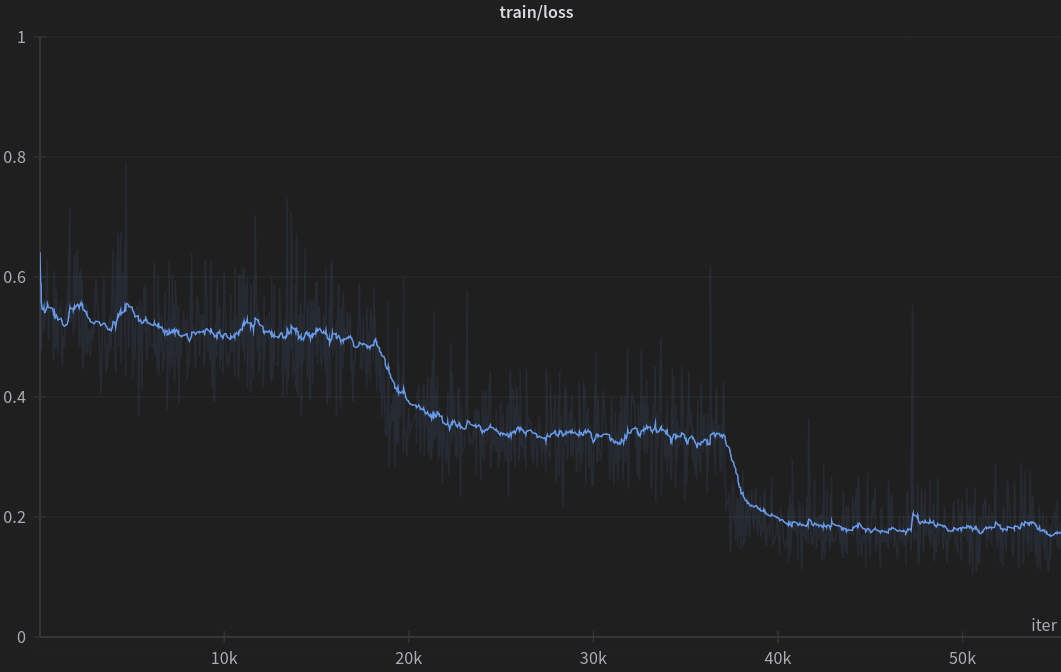


訓練超參數:
| 超參數 | 值 |
|---|---|
| 上下文長度 | 4096 |
| 微批量大小 | 1 |
| 批量大小 | 最大 4194304 |
| 學習率(餘弦,自適應) | 7e-6 -> 6e-7 |
| 預熱迭代次數 | 50 |
| 總迭代次數 | 55440 |
| 優化器 | AdamW |
| β1, β2 | 0.9, 0.95 |
| Adam_eps | 1e−8 |
| 權重衰減 | 0.05 |
| 梯度裁剪 | 1.0 |
| 精度 | bfloat16(混合) |
量化和 MLX 版本:
我們瞭解到有些人希望探索更小的模型,或者沒有資源運行完整模型。因此,我們準備了 Bielik-7B-Instruct-v0.1 模型的量化版本。同時,我們也考慮到了 Apple Silicon 用戶。
量化版本(適用於非 GPU 或較弱 GPU):
- https://huggingface.co/speakleash/Bielik-7B-Instruct-v0.1-GGUF
- https://huggingface.co/speakleash/Bielik-7B-Instruct-v0.1-GPTQ
- https://huggingface.co/speakleash/Bielik-7B-Instruct-v0.1-AWQ
- https://huggingface.co/speakleash/Bielik-7B-Instruct-v0.1-EXL2
- https://huggingface.co/speakleash/Bielik-7B-Instruct-v0.1-3bit-HQQ
適用於 Apple Silicon 的版本:
- https://huggingface.co/speakleash/Bielik-7B-Instruct-v0.1-MLX
指令格式
為了利用指令微調,你的提示應使用 [INST] 和 [/INST] 標記包圍。第一條指令應從句子起始標記開始。生成的完成內容將以句子結束標記結束。
例如:
prompt = "<s>[INST] Jakie mamy pory roku? [/INST]"
completion = "W Polsce mamy 4 pory roku: wiosna, lato, jesień i zima.</s>"
這種格式可以通過 apply_chat_template() 方法作為 聊天模板 使用:
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # 加載模型的設備
model_name = "speakleash/Bielik-7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16)
messages = [
{"role": "system", "content": "Odpowiadaj krótko, precyzyjnie i wyłącznie w języku polskim."},
{"role": "user", "content": "Jakie mamy pory roku w Polsce?"},
{"role": "assistant", "content": "W Polsce mamy 4 pory roku: wiosna, lato, jesień i zima."},
{"role": "user", "content": "Która jest najcieplejsza?"}
]
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = input_ids.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
如果由於某種原因無法使用 tokenizer.apply_chat_template,可以使用以下代碼生成正確的提示:
def chat_template(message, history, system_prompt):
prompt_builder = ["<s>[INST] "]
if system_prompt:
prompt_builder.append(f"<<SYS>>\n{system_prompt}\n<</SYS>>\n\n")
for human, assistant in history:
prompt_builder.append(f"{human} [/INST] {assistant}</s>[INST] ")
prompt_builder.append(f"{message} [/INST]")
return ''.join(prompt_builder)
system_prompt = "Odpowiadaj krótko, precyzyjnie i wyłącznie w języku polskim."
history = [
("Jakie mamy pory roku w Polsce?", "W Polsce mamy 4 pory roku: wiosna, lato, jesień i zima.")
]
message = "Która jest najcieplejsza?"
prompt = chat_template(message, history, system_prompt)
評估
模型在 Open PL LLM 排行榜 上進行了 5-shot 評估。該基準測試評估了模型在自然語言處理任務(如情感分析、分類、文本分類)中的表現,但未測試聊天技能。以下是評估指標:
- 平均得分:所有任務的平均得分,以基線得分進行歸一化。
- RAG 重排序:RAG 中常用的重排序任務。
- RAG 閱讀器(生成器):RAG 中常用的開放書籍問答任務。
- 困惑度(越低越好):作為額外指標,與其他得分無關,不應用於模型比較。
截至 2024 年 4 月 3 日,以下表格展示了根據 Open PL LLM 排行榜在 5-shot 設置下評估的預訓練和持續預訓練模型的當前得分:
| 平均得分 | RAG 重排序 | RAG 閱讀器 | 困惑度 | |
|---|---|---|---|---|
| 7B 參數模型: | ||||
| 基線(多數類) | 0.00 | 53.36 | - | - |
| Voicelab/trurl-2-7b | 18.85 | 60.67 | 77.19 | 1098.88 |
| meta-llama/Llama-2-7b-chat-hf | 21.04 | 54.65 | 72.93 | 4018.74 |
| mistralai/Mistral-7B-Instruct-v0.1 | 26.42 | 56.35 | 73.68 | 6909.94 |
| szymonrucinski/Curie-7B-v1 | 26.72 | 55.58 | 85.19 | 389.17 |
| HuggingFaceH4/zephyr-7b-beta | 33.15 | 71.65 | 71.27 | 3613.14 |
| HuggingFaceH4/zephyr-7b-alpha | 33.97 | 71.47 | 73.35 | 4464.45 |
| internlm/internlm2-chat-7b-sft | 36.97 | 73.22 | 69.96 | 4269.63 |
| internlm/internlm2-chat-7b | 37.64 | 72.29 | 71.17 | 3892.50 |
| Bielik-7B-Instruct-v0.1 | 39.28 | 61.89 | 86.00 | 277.92 |
| mistralai/Mistral-7B-Instruct-v0.2 | 40.29 | 72.58 | 79.39 | 2088.08 |
| teknium/OpenHermes-2.5-Mistral-7B | 42.64 | 70.63 | 80.25 | 1463.00 |
| openchat/openchat-3.5-1210 | 44.17 | 71.76 | 82.15 | 1923.83 |
| speakleash/mistral_7B-v2/spkl-all_sft_v2/e1_base/spkl-all_2e6-e1_70c70cc6(實驗性) | 45.44 | 71.27 | 91.50 | 279.24 |
| Nexusflow/Starling-LM-7B-beta | 45.69 | 74.58 | 81.22 | 1161.54 |
| openchat/openchat-3.5-0106 | 47.32 | 74.71 | 83.60 | 1106.56 |
| berkeley-nest/Starling-LM-7B-alpha | 47.46 | 75.73 | 82.86 | 1438.04 |
| 不同大小的模型: | ||||
| Azurro/APT3-1B-Instruct-v1(1B) | -13.80 | 52.11 | 12.23 | 739.09 |
| Voicelab/trurl-2-13b-academic(13B) | 29.45 | 68.19 | 79.88 | 733.91 |
| upstage/SOLAR-10.7B-Instruct-v1.0(10.7B) | 46.07 | 76.93 | 82.86 | 789.58 |
| 7B 參數預訓練和持續預訓練模型: | ||||
| OPI-PG/Qra-7b | 11.13 | 54.40 | 75.25 | 203.36 |
| meta-llama/Llama-2-7b-hf | 12.73 | 54.02 | 77.92 | 850.45 |
| internlm/internlm2-base-7b | 20.68 | 52.39 | 69.85 | 3110.92 |
| Bielik-7B-v0.1 | 29.38 | 62.13 | 88.39 | 123.31 |
| mistralai/Mistral-7B-v0.1 | 30.67 | 60.35 | 85.39 | 857.32 |
| internlm/internlm2-7b | 33.03 | 69.39 | 73.63 | 5498.23 |
| alpindale/Mistral-7B-v0.2-hf | 33.05 | 60.23 | 85.21 | 932.60 |
| speakleash/mistral-apt3-7B/spi-e0_hf(實驗性) | 35.50 | 62.14 | 87.48 | 132.78 |
SpeakLeash 模型在 RAG 閱讀器任務中取得了優異的成績。與 Mistral-7B-v0.1 相比,我們成功將平均得分提高了近 9 個百分點。在我們對聊天技能的主觀評估中,SpeakLeash 模型的表現優於其他平均得分較高的模型。
上述表格中的結果是在未使用指令模型的指令模板的情況下獲得的,而是將它們視為基礎模型。這種方法可能會影響結果,因為指令模型是針對特定指令進行優化的。
侷限性和偏差
Bielik-7B-Instruct-v0.1 是一個快速演示,表明基礎模型可以輕鬆進行微調以實現令人信服和有前景的性能。它沒有任何審核機制。我們期待與社區合作,使模型遵守規則,以便在需要審核輸出的環境中部署。
Bielik-7B-Instruct-v0.1 可能會產生事實錯誤的輸出,不應依賴它來生成事實準確的數據。Bielik-7B-Instruct-v0.1 在各種公共數據集上進行了訓練。儘管在清理訓練數據方面付出了巨大努力,但該模型仍有可能生成淫穢、虛假、有偏見或其他冒犯性的輸出。
許可證
由於法律情況不明確,我們決定以 CC BY NC 4.0 許可證發佈該模型 - 允許非商業使用。只要符合許可證條件,該模型可用於科學研究和個人使用。
引用
請使用以下格式引用此模型:
@misc{Bielik7Bv01,
title = {Introducing Bielik-7B-Instruct-v0.1: Instruct Polish Language Model},
author = {Ociepa, Krzysztof and Flis, Łukasz and Wróbel, Krzysztof and Kondracki, Sebastian and {SpeakLeash Team} and {Cyfronet Team}},
year = {2024},
url = {https://huggingface.co/speakleash/Bielik-7B-Instruct-v0.1},
note = {Accessed: 2024-04-01}, % 更改此日期
urldate = {2024-04-01} % 更改此日期
}
@misc{ociepa2024bielik7bv01polish,
title={Bielik 7B v0.1: A Polish Language Model -- Development, Insights, and Evaluation},
author={Krzysztof Ociepa and Łukasz Flis and Krzysztof Wróbel and Adrian Gwoździej and Remigiusz Kinas},
year={2024},
eprint={2410.18565},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2410.18565},
}
模型訓練負責人
- Krzysztof OciepaSpeakLeash - 團隊領導、概念設計、數據準備、流程優化和訓練監督。
- Łukasz FlisCyfronet AGH - 協調和監督訓練。
- Krzysztof WróbelSpeakLeash - 基準測試。
- Sebastian KondrackiSpeakLeash - 指令協調和準備。
- Maria FilipkowskaSpeakLeash - 指令準備。
- Paweł KiszczakSpeakLeash - 指令準備。
- Adrian GwoździejSpeakLeash - 數據質量和指令清理。
- Igor CiuciuraSpeakLeash - 指令清理。
- Jacek ChwiłaSpeakLeash - 指令清理。
- Remigiusz KinasSpeakLeash - 提供量化模型。
- Szymon BaczyńskiSpeakLeash - 提供量化模型。
如果沒有整個 SpeakLeash 團隊的奉獻和努力,這個模型就無法創建,他們的貢獻是不可估量的。由於許多人的辛勤工作,才有可能收集大量的波蘭語內容,並建立了開源科學項目 SpeakLeash 與高性能計算中心 ACK Cyfronet AGH 之間的合作。為開源科學 SpeakLeash 項目做出貢獻的個人包括: Grzegorz Urbanowicz、 Paweł Cyrta、 Jan Maria Kowalski、 Karol Jezierski、 Kamil Nonckiewicz、 Izabela Babis、 Nina Babis、 Waldemar Boszko 以及許多其他優秀的人工智能研究人員和愛好者。
ACK Cyfronet AGH 團隊的成員提供了寶貴的支持和專業知識: Szymon Mazurek。
聯繫我們
如果您有任何問題或建議,請使用討論標籤。如果您想直接聯繫我們,請加入我們的 Discord SpeakLeash。