%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型概述
模型特點
模型能力
使用案例
🚀 Distil-Whisper: distil-large-v2
Distil-Whisper是一個經過知識蒸餾的語音識別模型,它在速度和模型大小上對Whisper模型進行了優化,在保持相近識別準確率的同時,實現了更快的推理速度和更小的模型體積。
🚀 快速開始
Distil-Whisper從Hugging Face 🤗 Transformers的4.35版本開始得到支持。要運行該模型,首先需要安裝最新版本的Transformers庫。在本示例中,我們還將安裝 🤗 Datasets 以從Hugging Face Hub加載玩具音頻數據集:
pip install --upgrade pip
pip install --upgrade transformers accelerate datasets[audio]
✨ 主要特性
- 速度提升:相比原始的Whisper模型,Distil-Whisper速度提升了6倍。
- 模型體積減小:模型大小比Whisper小49%。
- 準確率相近:在分佈外評估集上,字錯誤率(WER)與Whisper相差在1%以內。
- 多場景支持:支持短音頻轉錄、長音頻轉錄、推測解碼等多種場景。
📦 安裝指南
要使用Distil-Whisper,需要安裝相關依賴庫。以下是安裝命令:
pip install --upgrade pip
pip install --upgrade transformers accelerate datasets[audio]
💻 使用示例
基礎用法
短音頻轉錄
模型可以使用 pipeline 類對短音頻文件(< 30秒)進行轉錄,示例代碼如下:
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-large-v2"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
要轉錄本地音頻文件,只需在調用pipeline時傳入音頻文件的路徑:
- result = pipe(sample)
+ result = pipe("audio.mp3")
長音頻轉錄
Distil-Whisper使用分塊算法對長音頻文件(> 30秒)進行轉錄。在實踐中,這種分塊長音頻算法比OpenAI在Whisper論文中提出的順序算法快9倍。
要啟用分塊,需要在 pipeline 中傳入 chunk_length_s 參數。對於Distil-Whisper,15秒的分塊長度是最優的。要啟用批處理,需要傳入 batch_size 參數:
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-large-v2"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
chunk_length_s=15,
batch_size=16,
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("distil-whisper/librispeech_long", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
高級用法
推測解碼
Distil-Whisper可以作為Whisper的輔助模型用於推測解碼。推測解碼在數學上保證了與Whisper相同的輸出,同時速度提高了2倍。這使得它成為現有Whisper管道的完美替代品,因為保證了相同的輸出。 在以下代碼片段中,我們將輔助Distil-Whisper模型獨立加載到主Whisper管道中,然後將其指定為生成的“輔助模型”:
from transformers import pipeline, AutoModelForCausalLM, AutoModelForSpeechSeq2Seq, AutoProcessor
import torch
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
assistant_model_id = "distil-whisper/distil-large-v2"
assistant_model = AutoModelForCausalLM.from_pretrained(
assistant_model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
assistant_model.to(device)
model_id = "openai/whisper-large-v2"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
generate_kwargs={"assistant_model": assistant_model},
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
📚 詳細文檔
額外的速度和內存優化
Flash Attention
如果你的GPU支持,我們建議使用 Flash-Attention 2。要使用它,首先需要安裝 Flash Attention:
pip install flash-attn --no-build-isolation
然後,只需在 from_pretrained 中傳入 use_flash_attention_2=True:
- model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True)
+ model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True, use_flash_attention_2=True)
Torch Scale-Product-Attention (SDPA)
如果你的GPU不支持Flash Attention,我們建議使用 BetterTransformers。要使用它,首先需要安裝optimum:
pip install --upgrade optimum
然後,在使用模型之前將其轉換為“BetterTransformer”模型:
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True)
+ model = model.to_bettertransformer()
在 openai-whisper 中運行Distil-Whisper
要以原始Whisper格式使用該模型,首先需要確保安裝了 openai-whisper 包:
pip install --upgrade openai-whisper
以下代碼片段展示瞭如何轉錄使用 🤗 Datasets 加載的LibriSpeech數據集中的樣本文件:
import torch
from datasets import load_dataset
from huggingface_hub import hf_hub_download
from whisper import load_model, transcribe
distil_large_v2 = hf_hub_download(repo_id="distil-whisper/distil-large-v2", filename="original-model.bin")
model = load_model(distil_large_v2)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]["array"]
sample = torch.from_numpy(sample).float()
pred_out = transcribe(model, audio=sample)
print(pred_out["text"])
要轉錄本地音頻文件,只需將音頻文件的路徑作為 audio 參數傳遞給 transcribe:
pred_out = transcribe(model, audio="audio.mp3")
Whisper.cpp
Distil-Whisper可以使用 Whisper.cpp 倉庫中的原始順序長音頻轉錄算法運行。在Mac M1上的 臨時基準測試 中,distil-large-v2 比 large-v2 快2倍,同時在長音頻上的WER相差在0.1%以內。
開始使用的步驟如下:
- 克隆Whisper.cpp倉庫:
git clone https://github.com/ggerganov/whisper.cpp.git
cd whisper.cpp
- 從Hugging Face Hub下載
distil-medium.en的ggml權重:
python -c "from huggingface_hub import hf_hub_download; hf_hub_download(repo_id='distil-whisper/distil-large-v2', filename='ggml-large-32-2.en.bin', local_dir='./models')"
如果你沒有安裝 huggingface_hub 包,也可以使用 wget 下載權重:
wget https://huggingface.co/distil-whisper/distil-large-v2/resolve/main/ggml-large-32-2.en.bin -P ./models
- 使用提供的示例音頻運行推理:
make -j && ./main -m models/ggml-large-32-2.en.bin -f samples/jfk.wav
Transformers.js
import { pipeline } from '@huggingface/transformers';
const transcriber = await pipeline('automatic-speech-recognition', 'distil-whisper/distil-large-v2');
const url = 'https://huggingface.co/datasets/Xenova/transformers.js-docs/resolve/main/jfk.wav';
const output = await transcriber(url);
// { text: " And so, my fellow Americans, ask not what your country can do for you. Ask what you can do for your country." }
更多信息請參閱 文檔。 注意:由於模型較大,我們建議在服務器端使用 Node.js 運行該模型(而不是在瀏覽器中)。
Candle
通過與Hugging Face Candle 🕯️ 的集成,Distil-Whisper現在可以在Rust庫 🦀 中使用。 其優勢包括:
- 優化的CPU後端,x86可選MKL支持,Mac可選Accelerate支持。
- CUDA後端,可在GPU上高效運行,通過NCCL實現多GPU分發。
- WASM支持:可在瀏覽器中運行Distil-Whisper。 開始使用的步驟如下:
- 按照 此處 的說明安裝
candle-core。 - 本地克隆
candle倉庫:
git clone https://github.com/huggingface/candle.git
- 進入 Whisper 的示例目錄:
cd candle/candle-examples/examples/whisper
- 運行示例:
cargo run --example whisper --release -- --model distil-large-v2
- 要指定自己的音頻文件,添加
--input標誌:
cargo run --example whisper --release -- --model distil-large-v2 --input audio.wav
模型評估
以下代碼片段展示瞭如何使用 流式模式 在LibriSpeech驗證集上評估Distil-Whisper模型,這意味著無需將音頻數據下載到本地設備。 首先,我們需要安裝所需的包,包括 🤗 Datasets 以流式加載音頻數據,以及 🤗 Evaluate 以進行WER計算:
pip install --upgrade pip
pip install --upgrade transformers datasets[audio] evaluate jiwer
然後可以使用以下示例端到端地運行評估:
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
from transformers.models.whisper.english_normalizer import EnglishTextNormalizer
from datasets import load_dataset
from evaluate import load
import torch
from tqdm import tqdm
# define our torch configuration
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-large-v2"
# load the model + processor
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, use_safetensors=True, low_cpu_mem_usage=True)
model = model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
# load the dataset with streaming mode
dataset = load_dataset("librispeech_asr", "clean", split="validation", streaming=True)
# define the evaluation metric
wer_metric = load("wer")
normalizer = EnglishTextNormalizer(processor.tokenizer.english_spelling_normalizer)
def inference(batch):
# 1. Pre-process the audio data to log-mel spectrogram inputs
audio = [sample["array"] for sample in batch["audio"]]
input_features = processor(audio, sampling_rate=batch["audio"][0]["sampling_rate"], return_tensors="pt").input_features
input_features = input_features.to(device, dtype=torch_dtype)
# 2. Auto-regressively generate the predicted token ids
pred_ids = model.generate(input_features, max_new_tokens=128, language="en", task="transcribe")
# 3. Decode the token ids to the final transcription
batch["transcription"] = processor.batch_decode(pred_ids, skip_special_tokens=True)
batch["reference"] = batch["text"]
return batch
dataset = dataset.map(function=inference, batched=True, batch_size=16)
all_transcriptions = []
all_references = []
# iterate over the dataset and run inference
for i, result in tqdm(enumerate(dataset), desc="Evaluating..."):
all_transcriptions.append(result["transcription"])
all_references.append(result["reference"])
# normalize predictions and references
all_transcriptions = [normalizer(transcription) for transcription in all_transcriptions]
all_references = [normalizer(reference) for reference in all_references]
# compute the WER metric
wer = 100 * wer_metric.compute(predictions=all_transcriptions, references=all_references)
print(wer)
打印輸出:
2.983685535968466
🔧 技術細節
模型架構
Distil-Whisper繼承了Whisper的編碼器 - 解碼器架構。編碼器將語音向量輸入序列映射到隱藏狀態向量序列,解碼器根據所有先前的標記和編碼器的隱藏狀態自迴歸地預測文本標記。因此,編碼器只向前運行一次,而解碼器運行的次數與生成的標記數量相同。在實踐中,這意味著解碼器佔總推理時間的90%以上。因此,為了優化延遲,應重點關注最小化解碼器的推理時間。
為了對Whisper模型進行知識蒸餾,我們在保持編碼器固定的同時減少了解碼器層的數量。編碼器(綠色部分)完全從教師模型複製到學生模型,並在訓練期間凍結。學生模型的解碼器僅由兩個解碼器層組成,它們從教師模型的第一個和最後一個解碼器層初始化(紅色部分)。教師模型的所有其他解碼器層都被丟棄。然後,模型在KL散度和偽標籤損失項的加權和上進行訓練。
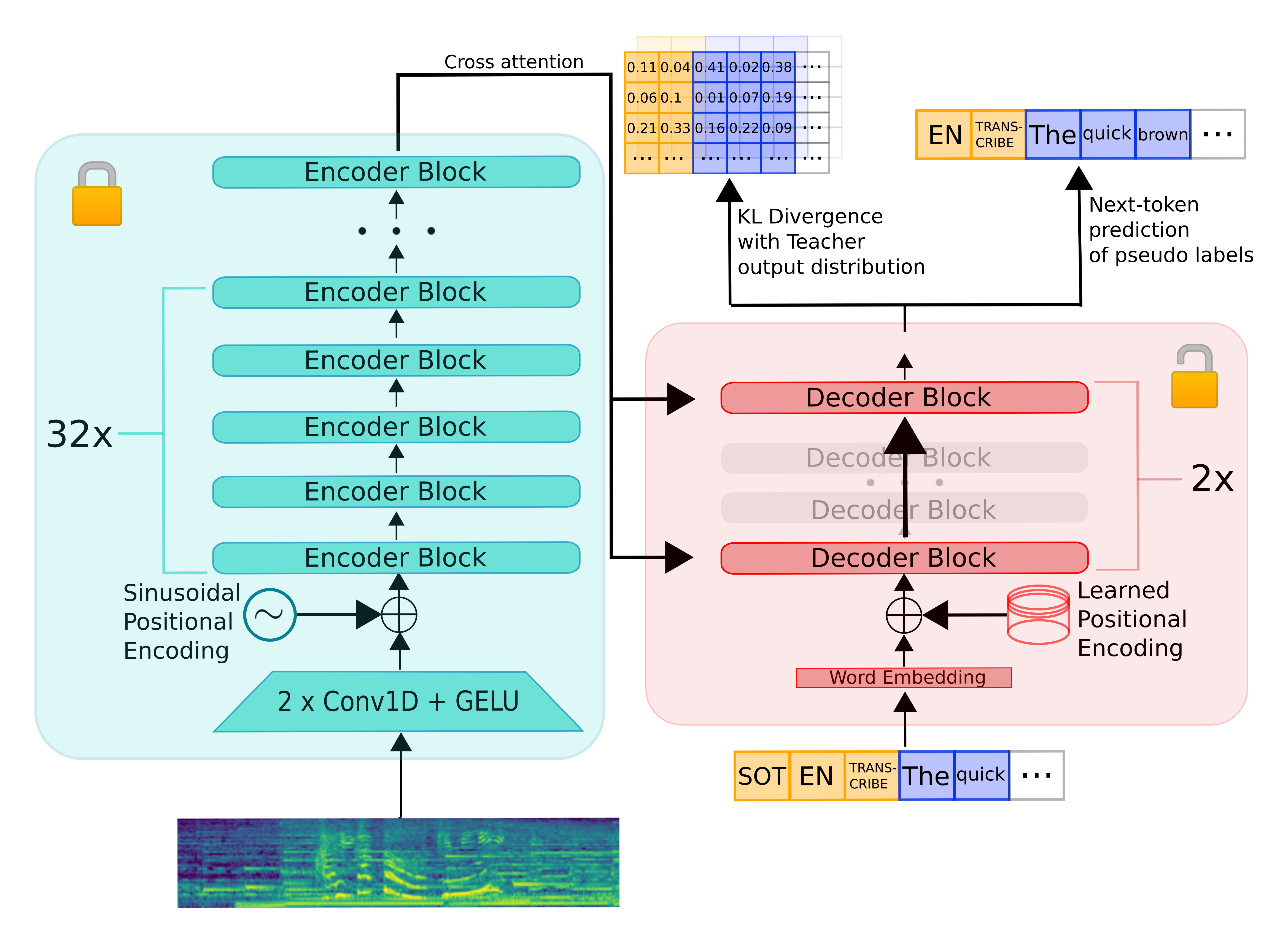
訓練數據
Distil-Whisper在來自Hugging Face Hub上9個開源、許可寬鬆的語音數據集的22,000小時音頻數據上進行訓練:
| 數據集 | 時長 / 小時 | 說話者數量 | 領域 | 許可證 |
|---|---|---|---|---|
| People's Speech | 12,000 | 未知 | Internet Archive | CC-BY-SA-4.0 |
| Common Voice 13 | 3,000 | 未知 | Narrated Wikipedia | CC0-1.0 |
| GigaSpeech | 2,500 | 未知 | Audiobook, podcast, YouTube | apache-2.0 |
| Fisher | 1,960 | 11,900 | 電話對話 | LDC |
| LibriSpeech | 960 | 2,480 | 有聲讀物 | CC-BY-4.0 |
| VoxPopuli | 540 | 1,310 | 歐洲議會 | CC0 |
| TED-LIUM | 450 | 2,030 | TED演講 | CC-BY-NC-ND 3.0 |
| SwitchBoard | 260 | 540 | 電話對話 | LDC |
| AMI | 100 | 未知 | 會議 | CC-BY-4.0 |
| 總計 | 21,770 | 18,260+ |
組合數據集涵蓋10個不同領域和超過50,000名說話者。這種數據集的多樣性對於確保蒸餾模型對音頻分佈和噪聲具有魯棒性至關重要。
音頻數據然後使用Whisper large-v2模型進行偽標籤標註:我們使用Whisper為訓練集中的所有音頻生成預測,並在訓練期間將這些預測用作目標標籤。使用偽標籤確保了轉錄在數據集之間的格式一致,並在訓練期間提供了序列級的蒸餾信號。
WER過濾
Whisper的偽標籤預測可能會出現錯誤轉錄和幻覺。為了確保我們只在準確的偽標籤上進行訓練,我們在訓練期間採用了一種簡單的WER啟發式方法。首先,我們對Whisper的偽標籤和每個數據集提供的真實標籤進行歸一化。然後,我們計算這些標籤之間的WER。如果WER超過指定的閾值,我們將丟棄該訓練示例;否則,我們將其保留用於訓練。
Distil-Whisper論文 的第9.2節展示了這種過濾方法對於提高蒸餾模型下游性能的有效性。我們還將Distil-Whisper對幻覺的魯棒性部分歸因於這種過濾方法。
訓練過程
模型經過80,000次優化步驟(即8個epoch)的訓練。Tensorboard訓練日誌可在以下鏈接找到:https://huggingface.co/distil-whisper/distil-large-v2/tensorboard?params=scalars#frame
評估結果
蒸餾後的模型在分佈外(OOD)短音頻上的WER與Whisper相差在1%以內,在OOD長音頻上的表現比Whisper好0.1%。這種性能提升歸因於更低的幻覺率。
有關每個數據集評估結果的詳細細分,請參考 Distil-Whisper論文 的表16和表17。
Distil-Whisper還在 ESB基準測試 數據集上進行了評估,作為 OpenASR排行榜 的一部分,其WER與Whisper相差在0.2%以內。
📄 許可證
Distil-Whisper繼承了OpenAI的Whisper模型的 MIT許可證。
引用
如果你使用了該模型,請考慮引用 Distil-Whisper論文:
@misc{gandhi2023distilwhisper,
title={Distil-Whisper: Robust Knowledge Distillation via Large-Scale Pseudo Labelling},
author={Sanchit Gandhi and Patrick von Platen and Alexander M. Rush},
year={2023},
eprint={2311.00430},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
致謝
- OpenAI提供了Whisper 模型 和 原始代碼庫。
- Hugging Face 🤗 Transformers 實現了模型集成。
- Google的 TPU研究雲(TRC) 計劃提供了Cloud TPU v4。
@rsonavane在LibriSpeech數據集上發佈了Distil-Whisper的早期版本。
⚠️ 重要提示
Distil-Whisper目前僅支持英語語音識別。我們正在與社區合作,對其他語言的Whisper進行知識蒸餾。如果你有興趣對自己語言的Whisper進行蒸餾,請查看提供的 訓練代碼。當準備好時,我們將使用多語言檢查點更新 Distil-Whisper倉庫!
💡 使用建議
由於OpenAI發佈了Whisper large-v3,一個更新的 distil-large-v3 模型已經發布。這個 distil-large-v3 模型在不改變架構的情況下超越了distil-large-v2模型的性能,並且對順序長格式生成有更好的支持。因此,建議使用 distil-large-v3 模型代替large-v2模型。