%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型概述
模型特點
模型能力
使用案例
🚀 Whisper-Large-V3-French
Whisper-Large-V3-French在openai/whisper-large-v3的基礎上進行了微調,進一步提升了其在法語上的性能。該模型經過訓練,可以預測大小寫、標點符號和數字。雖然這可能會在一定程度上犧牲性能,但我們認為這能使其擁有更廣泛的用途。
🚀 快速開始
Whisper-Large-V3-French可以用於法語語音識別任務。它已經被轉換為多種格式,方便在不同的庫中使用,包括transformers、openai-whisper、fasterwhisper、whisper.cpp、candle、mlx等。
✨ 主要特性
- 基於
openai/whisper-large-v3微調,在法語上有更好的表現。 - 能夠預測大小寫、標點符號和數字。
- 支持多種格式,可在不同庫中使用。
📦 安裝指南
根據不同的使用場景,你可以選擇不同的庫進行安裝:
OpenAI Whisper
pip install -U openai-whisper
Faster Whisper
pip install faster-whisper
Whisper.cpp
git clone https://github.com/ggerganov/whisper.cpp.git
cd whisper.cpp
make
Candle
git clone https://github.com/huggingface/candle.git
cd candle/candle-examples/examples/whisper
MLX
git clone https://github.com/ml-explore/mlx-examples.git
cd mlx-examples/whisper
pip install -r requirements.txt
💻 使用示例
基礎用法
Hugging Face Pipeline
import torch
from datasets import load_dataset
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
# Load model
model_name_or_path = "bofenghuang/whisper-large-v3-french"
processor = AutoProcessor.from_pretrained(model_name_or_path)
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_name_or_path,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
)
model.to(device)
# Init pipeline
pipe = pipeline(
"automatic-speech-recognition",
model=model,
feature_extractor=processor.feature_extractor,
tokenizer=processor.tokenizer,
torch_dtype=torch_dtype,
device=device,
# chunk_length_s=30, # for long-form transcription
max_new_tokens=128,
)
# Example audio
dataset = load_dataset("bofenghuang/asr-dummy", "fr", split="test")
sample = dataset[0]["audio"]
# Run pipeline
result = pipe(sample)
print(result["text"])
Hugging Face Low-level APIs
import torch
from datasets import load_dataset
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
# Load model
model_name_or_path = "bofenghuang/whisper-large-v3-french"
processor = AutoProcessor.from_pretrained(model_name_or_path)
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_name_or_path,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
)
model.to(device)
# Example audio
dataset = load_dataset("bofenghuang/asr-dummy", "fr", split="test")
sample = dataset[0]["audio"]
# Extract feautres
input_features = processor(
sample["array"], sampling_rate=sample["sampling_rate"], return_tensors="pt"
).input_features
# Generate tokens
predicted_ids = model.generate(
input_features.to(dtype=torch_dtype).to(device), max_new_tokens=128
)
# Detokenize to text
transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)[0]
print(transcription)
高級用法
Speculative Decoding
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoModelForSpeechSeq2Seq,
AutoProcessor,
pipeline,
)
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
# Load model
model_name_or_path = "bofenghuang/whisper-large-v3-french"
processor = AutoProcessor.from_pretrained(model_name_or_path)
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_name_or_path,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
)
model.to(device)
# Load draft model
assistant_model_name_or_path = "bofenghuang/whisper-large-v3-french-distil-dec2"
assistant_model = AutoModelForCausalLM.from_pretrained(
assistant_model_name_or_path,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
)
assistant_model.to(device)
# Init pipeline
pipe = pipeline(
"automatic-speech-recognition",
model=model,
feature_extractor=processor.feature_extractor,
tokenizer=processor.tokenizer,
torch_dtype=torch_dtype,
device=device,
generate_kwargs={"assistant_model": assistant_model},
max_new_tokens=128,
)
# Example audio
dataset = load_dataset("bofenghuang/asr-dummy", "fr", split="test")
sample = dataset[0]["audio"]
# Run pipeline
result = pipe(sample)
print(result["text"])
OpenAI Whisper
import whisper
from datasets import load_dataset
# Load model
model = whisper.load_model("./models/whisper-large-v3-french/original_model.pt")
# Example audio
dataset = load_dataset("bofenghuang/asr-dummy", "fr", split="test")
sample = dataset[0]["audio"]["array"].astype("float32")
# Transcribe
result = model.transcribe(sample, language="fr")
print(result["text"])
Faster Whisper
from datasets import load_dataset
from faster_whisper import WhisperModel
# Load model
model = WhisperModel("./models/whisper-large-v3-french/ctranslate2", device="cuda", compute_type="float16") # Run on GPU with FP16
# Example audio
dataset = load_dataset("bofenghuang/asr-dummy", "fr", split="test")
sample = dataset[0]["audio"]["array"].astype("float32")
segments, info = model.transcribe(sample, beam_size=5, language="fr")
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
Whisper.cpp
./main -m ./models/whisper-large-v3-french/ggml-model-q5_0.bin -l fr -f /path/to/audio/file --print-colors
Candle
cargo run --example whisper --release -- --model large-v3 --model-id bofenghuang/whisper-large-v3-french --language fr --input /path/to/audio/file
若要使用CUDA,可在命令行中添加--features cuda:
cargo run --example whisper --release --features cuda -- --model large-v3 --model-id bofenghuang/whisper-large-v3-french --language fr --input /path/to/audio/file
MLX
import whisper
result = whisper.transcribe("/path/to/audio/file", path_or_hf_repo="mlx_models/whisper-large-v3-french", language="fr")
print(result["text"])
📚 詳細文檔
性能評估
我們在短文本和長文本轉錄任務上對模型進行了評估,並在分佈內和分佈外數據集上進行了測試,以全面分析其準確性、泛化能力和魯棒性。
需要注意的是,報告中的WER(詞錯誤率)是在將數字轉換為文本、去除標點符號(除了撇號和連字符)並將所有字符轉換為小寫之後的結果。
所有公開數據集的評估結果可在此處找到。
短文本轉錄
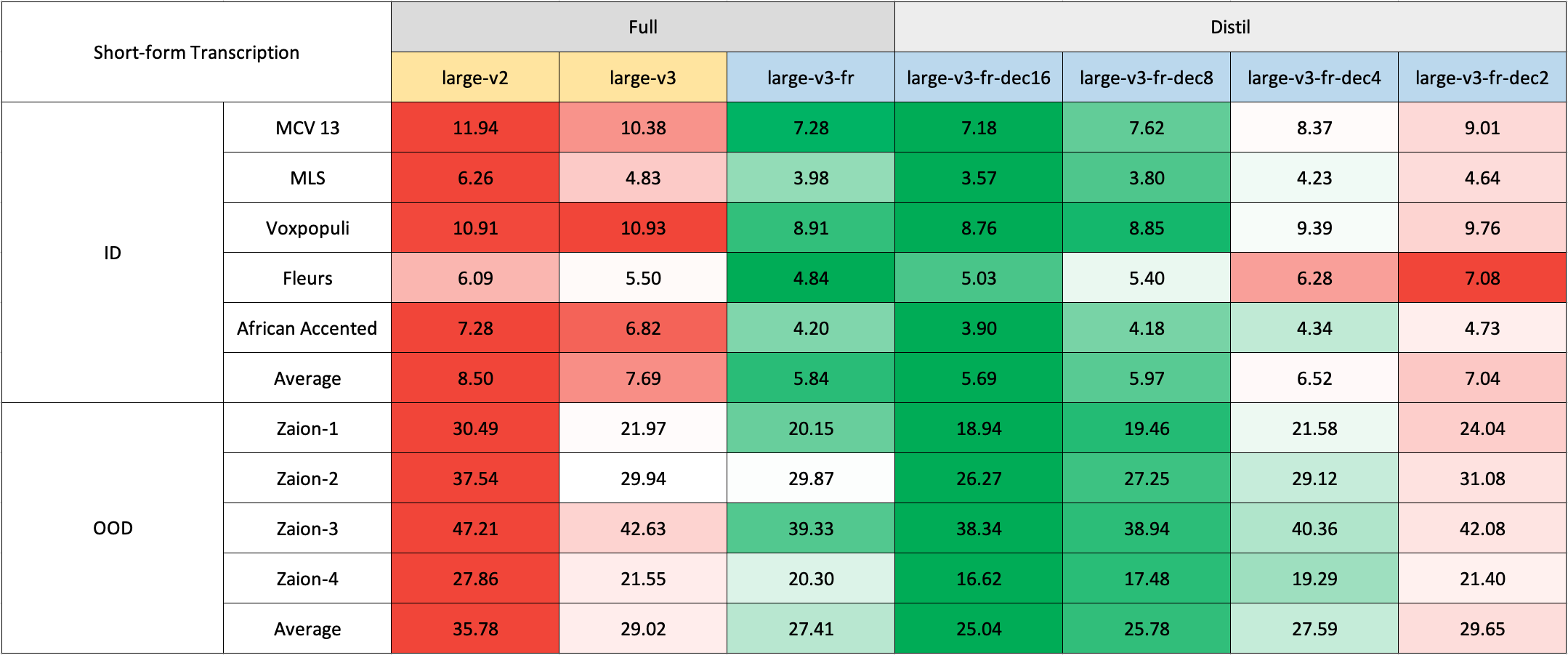
由於缺乏現成的法語領域外(OOD)和長文本測試集,我們使用了Zaion Lab的內部測試集進行評估。這些測試集包含了來自呼叫中心對話的人工標註的音頻-轉錄對,其顯著特點是存在大量背景噪音和特定領域的術語。
長文本轉錄
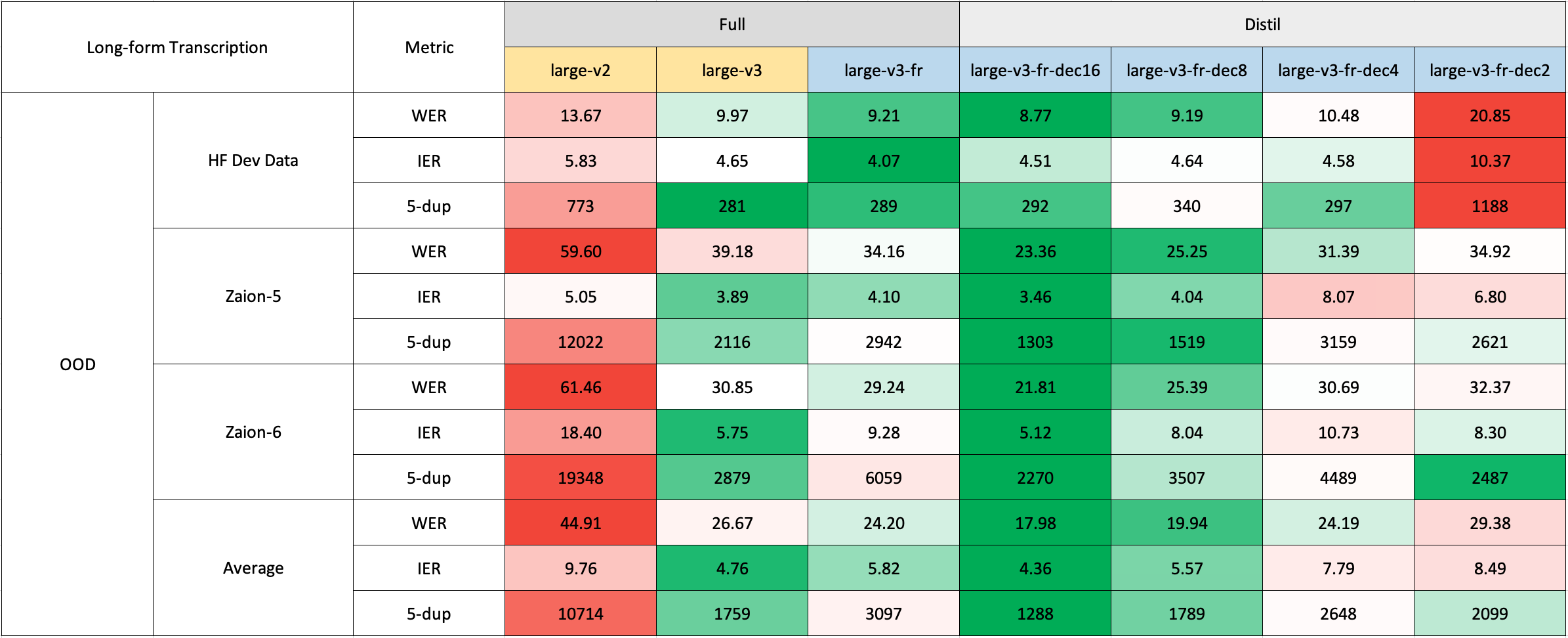
長文本轉錄使用了🤗 Hugging Face的管道進行快速評估。音頻文件被分割成30秒的片段,並進行並行處理。
訓練細節
我們收集了一個包含超過2500小時法語語音識別數據的複合數據集,其中包括Common Voice 13.0、Multilingual LibriSpeech、Voxpopuli、Fleurs、Multilingual TEDx、MediaSpeech、African Accented French等數據集。
由於一些數據集(如MLS)只提供沒有大小寫或標點符號的文本,我們使用了🤗 Speechbox的定製版本,藉助bofenghuang/whisper-large-v2-cv11-french模型從有限的符號集中恢復大小寫和標點符號。
然而,即使在這些數據集中,我們也發現了一些質量問題。這些問題包括音頻和轉錄在語言或內容上不匹配、話語分割不當以及腳本化語音中缺少單詞等。我們構建了一個管道來過濾掉許多這些有問題的話語,旨在提高數據集的質量。因此,我們排除了超過10%的數據,並且在重新訓練模型時,我們發現幻覺現象顯著減少。
在訓練過程中,我們使用了🤗 Transformers倉庫中提供的腳本。模型訓練在GENCI的Jean-Zay超級計算機上進行,我們感謝IDRIS團隊在整個項目過程中提供的及時支持。
致謝
- 感謝OpenAI創建並開源了Whisper模型。
- 感謝🤗 Hugging Face將Whisper模型集成到Transformers倉庫中,並提供了訓練代碼庫。
- 感謝Genci為該項目慷慨提供GPU計算時間。
🔧 技術細節
評估指標
使用WER(詞錯誤率)作為評估指標,以衡量模型在語音轉錄任務中的準確性。
訓練腳本
使用🤗 Transformers倉庫中的run_speech_recognition_seq2seq.py腳本進行訓練。
訓練環境
在Jean-Zay超級計算機上進行訓練。
📄 許可證
本項目採用MIT許可證。
信息表格
| 屬性 | 詳情 |
|---|---|
| 模型類型 | 基於openai/whisper-large-v3微調的語音識別模型 |
| 訓練數據 | 包含超過2500小時法語語音識別數據的複合數據集,包括Common Voice 13.0、Multilingual LibriSpeech、Voxpopuli、Fleurs、Multilingual TEDx、MediaSpeech、African Accented French等 |