%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型概述
模型特點
模型能力
使用案例
FLAN-T5基礎版模型卡
目錄
摘要
若您已瞭解T5模型,FLAN-T5在各方面表現更優。在參數量相同的情況下,這些模型額外微調了覆蓋更多語言的1000多項任務。如摘要首行所述:
Flan-PaLM 540B在多項基準測試中達到最先進水平,如在MMLU五樣本測試中獲得75.2%準確率。我們同時開源了Flan-T5檢查點,即使與PaLM 62B等更大模型相比也展現出強勁的小樣本性能。總體而言,指令微調是提升預訓練語言模型性能和可用性的通用方法。
免責聲明:本模型卡內容由Hugging Face團隊編寫,部分內容複製自T5模型卡。
模型詳情
模型描述
- 模型類型:語言模型
- 支持語言:英語、西班牙語、日語、波斯語、印地語、法語、中文、孟加拉語、古吉拉特語、德語、泰盧固語、意大利語、阿拉伯語、波蘭語、泰米爾語、馬拉地語、馬拉雅拉姆語、奧里亞語、旁遮普語、葡萄牙語、烏爾都語、加利西亞語、希伯來語、韓語、加泰羅尼亞語、泰語、荷蘭語、印尼語、越南語、保加利亞語、菲律賓語、高棉語、老撾語、土耳其語、俄語、克羅地亞語、瑞典語、約魯巴語、庫爾德語、緬甸語、馬來語、捷克語、芬蘭語、索馬里語、他加祿語、斯瓦希里語、僧伽羅語、卡納達語、壯語、伊博語、科薩語、羅馬尼亞語、海地語、愛沙尼亞語、斯洛伐克語、立陶宛語、希臘語、尼泊爾語、阿薩姆語、挪威語等
- 許可證:Apache 2.0
- 關聯模型:所有FLAN-T5檢查點
- 原始檢查點:原始FLAN-T5檢查點
- 更多資源:
使用方式
PyTorch模型使用示例
CPU運行
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-base")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-base")
input_text = "將英語翻譯成德語:你多大了?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
GPU運行
# 需安裝accelerate
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-base")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-base", device_map="auto")
input_text = "將英語翻譯成德語:你多大了?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
不同精度運行
FP16精度
import torch
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-base")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-base",
device_map="auto", torch_dtype=torch.float16)
input_text = "將英語翻譯成德語:你多大了?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
INT8量化
# 需安裝bitsandbytes和accelerate
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-base")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-base",
device_map="auto", load_in_8bit=True)
input_text = "將英語翻譯成德語:你多大了?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
應用場景
直接使用與下游任務
原論文作者指出:
主要應用於語言模型研究,包括:零樣本NLP任務和上下文少樣本學習NLP任務研究(如推理和問答);推進公平性與安全性研究;理解當前大語言模型的侷限性
非適用場景
需更多信息補充
偏見、風險與限制
來自官方模型卡的信息:
包括FLAN-T5在內的語言模型可能被惡意用於文本生成(Rae等,2021)。未經事先評估應用場景的安全性與公平性,不應直接使用FLAN-T5。
倫理考量與風險
FLAN-T5在未經過濾顯式內容或評估固有偏見的大規模文本數據上微調,因此可能生成不當內容或反映底層數據偏見。
已知限制
FLAN-T5尚未在真實世界應用中測試
敏感用途
不可用於任何不可接受的場景,如生成侮辱性言論
訓練詳情
訓練數據
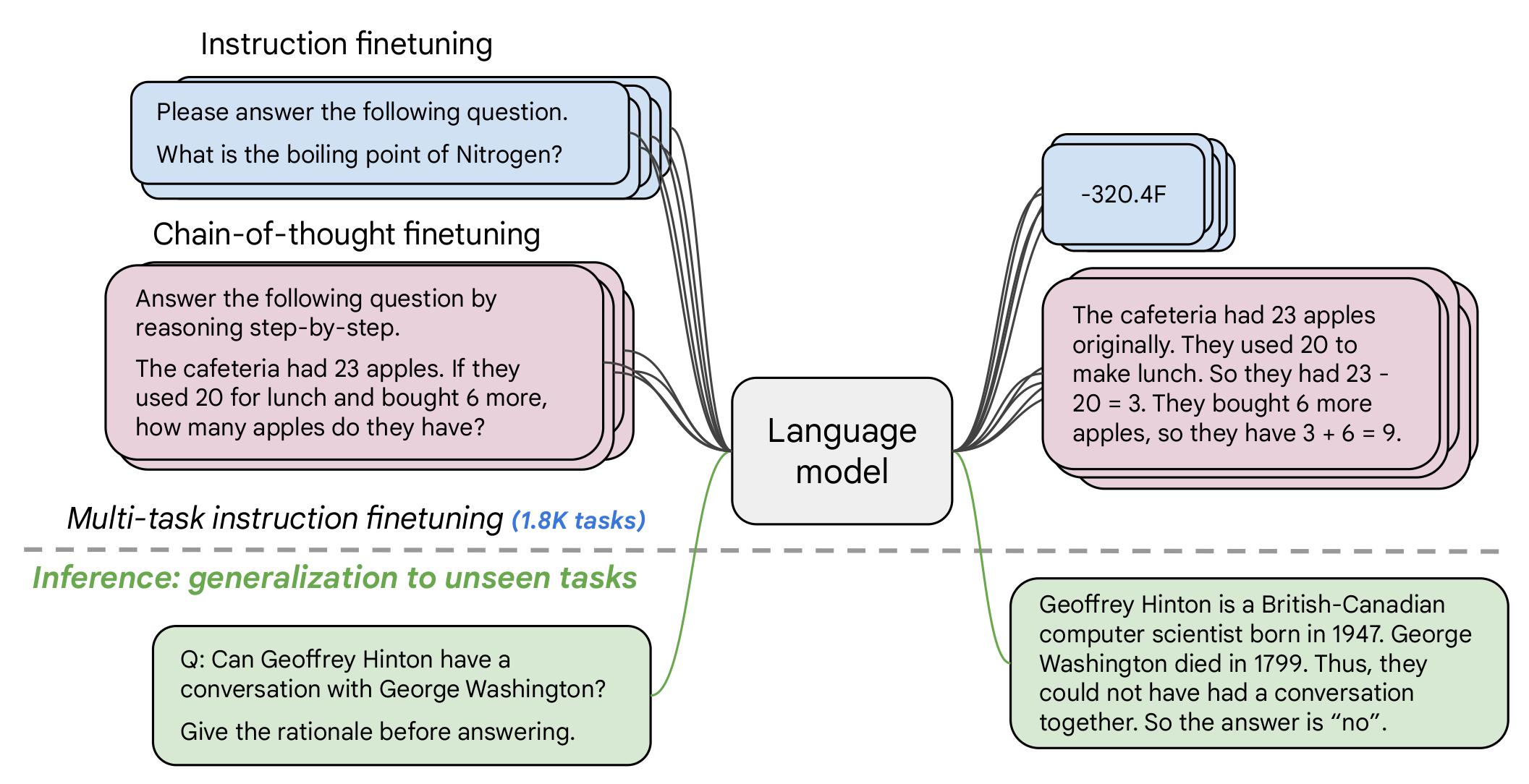
模型在混合任務上訓練,包括下圖所示任務(源自原論文圖2):

訓練過程
根據原論文:
這些模型基於預訓練T5(Raffel等,2020),通過指令微調提升零樣本和小樣本性能。每個T5模型尺寸都有對應的FLAN微調版本。
模型使用t5x代碼庫配合jax在TPU v3/v4 pod上訓練。
評估結果
測試數據與指標
作者在1836項跨語言任務上評估模型。部分量化評估如下:

結果
完整結果見原論文表3。
環境影響
碳排放量可使用機器學習影響計算器估算(Lacoste等,2019):
- 硬件類型:Google Cloud TPU Pods (v3/v4,芯片數≥4)
- 使用時長:需補充
- 雲服務商:GCP
- 計算區域:需補充
- 碳排放量:需補充
引用
@misc{https://doi.org/10.48550/arxiv.2210.11416,
doi = {10.48550/ARXIV.2210.11416},
url = {https://arxiv.org/abs/2210.11416},
author = {Chung, Hyung Won and Hou, Le and Longpre, Shayne and Zoph, Barret and Tay, Yi and Fedus, William and Li, Eric and Wang, Xuezhi and Dehghani, Mostafa and Brahma, Siddhartha and Webson, Albert and Gu, Shixiang Shane and Dai, Zhuyun and Suzgun, Mirac and Chen, Xinyun and Chowdhery, Aakanksha and Narang, Sharan and Mishra, Gaurav and Yu, Adams and Zhao, Vincent and Huang, Yanping and Dai, Andrew and Yu, Hongkun and Petrov, Slav and Chi, Ed H. and Dean, Jeff and Devlin, Jacob and Roberts, Adam and Zhou, Denny and Le, Quoc V. and Wei, Jason},
title = {指令微調語言模型的規模化研究},
publisher = {arXiv},
year = {2022}
}
模型回收測試
在36個數據集上評估顯示,使用google/flan-t5-base作為基礎模型平均得分為77.98,相比google/t5-v1_1-base的68.82有顯著提升。截至2023年6月2日,該模型在google/t5-v1_1-base架構中排名第一。完整結果參見模型回收項目。