%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Model Overview
Model Features
Model Capabilities
Use Cases
🚀 Hymba-1.5B-Base
Hymba-1.5B-Baseは、様々な自然言語生成タスクに適用可能なテキスト生成モデルです。ハイブリッドアーキテクチャを採用し、商業利用も可能です。
🚀 クイックスタート
Hymba-1.5B-Baseを使い始めるには、まず環境をセットアップし、その後モデルと会話することができます。
環境セットアップ
Hymba-1.5B-BaseはFlexAttentionを採用しており、Pytorch2.5とその他の関連依存関係に依存しています。以下の2つの方法で環境をセットアップできます。
- [ローカルインストール] 提供されている
setup.shを使用して関連パッケージをインストールします(CUDA 12.1/12.4をサポート)。
wget --header="Authorization: Bearer YOUR_HF_TOKEN" https://huggingface.co/nvidia/Hymba-1.5B-Base/resolve/main/setup.sh
bash setup.sh
- [Docker] Hymbaのすべての依存関係がインストールされたDockerイメージが提供されています。以下のコマンドを使用してDockerイメージをダウンロードし、コンテナを起動できます。
docker pull ghcr.io/tilmto/hymba:v1
docker run --gpus all -v /home/$USER:/home/$USER -it ghcr.io/tilmto/hymba:v1 bash
Hymba-1.5B-Baseと会話する
環境をセットアップした後、以下のスクリプトを使用してモデルと会話できます。
from transformers import LlamaTokenizer, AutoModelForCausalLM, AutoTokenizer, AutoModel
import torch
# トークナイザーとモデルをロード
repo_name = "nvidia/Hymba-1.5B-Base"
tokenizer = AutoTokenizer.from_pretrained(repo_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(repo_name, trust_remote_code=True)
model = model.cuda().to(torch.bfloat16)
# Hymbaと会話
prompt = input()
inputs = tokenizer(prompt, return_tensors="pt").to('cuda')
outputs = model.generate(**inputs, max_length=64, do_sample=False, temperature=0.7, use_cache=True)
response = tokenizer.decode(outputs[0][inputs['input_ids'].shape[1]:], skip_special_tokens=True)
print(f"モデルの応答: {response}")
✨ 主な機能
- 様々な自然言語生成タスクに適用可能なテキスト生成モデルです。
- ハイブリッドアーキテクチャを採用し、MambaとAttentionヘッドが並列で動作します。
- メタトークンを使用して、モデルの効果を向上させます。
- 2層間および単一層内のヘッド間でKVキャッシュを共有します。
- 90%のAttention層がスライディングウィンドウAttentionです。
- 商業利用可能です。
📦 インストール
環境セットアップの詳細は「クイックスタート」のセクションを参照してください。
💻 使用例
基本的な使用法
from transformers import LlamaTokenizer, AutoModelForCausalLM, AutoTokenizer, AutoModel
import torch
# トークナイザーとモデルをロード
repo_name = "nvidia/Hymba-1.5B-Base"
tokenizer = AutoTokenizer.from_pretrained(repo_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(repo_name, trust_remote_code=True)
model = model.cuda().to(torch.bfloat16)
# Hymbaと会話
prompt = input()
inputs = tokenizer(prompt, return_tensors="pt").to('cuda')
outputs = model.generate(**inputs, max_length=64, do_sample=False, temperature=0.7, use_cache=True)
response = tokenizer.decode(outputs[0][inputs['input_ids'].shape[1]:], skip_special_tokens=True)
print(f"モデルの応答: {response}")
📚 ドキュメント
モデルの概要
Hymba-1.5B-Baseは、様々な自然言語生成タスクに適用可能なベースのテキスト生成モデルです。
モデルは、MambaとAttentionヘッドが並列で動作するハイブリッドアーキテクチャを持っています。メタトークンは、すべてのプロンプトの前に付加される一連の学習可能なトークンで、モデルの効果を向上させるのに役立ちます。モデルは、2層間および単一層内のヘッド間でKVキャッシュを共有します。90%のAttention層はスライディングウィンドウAttentionです。
このモデルは商業利用可能です。
モデル開発者: NVIDIA
モデルの期間: Hymba-1.5B-Baseは、2024年9月1日から2024年11月10日まで学習されました。
ライセンス: このモデルは、NVIDIA Open Model License Agreementの下で公開されています。
モデルアーキテクチャ
私たちは、開発者がHymbaの設計原則を自分たちのモデルに理解して実装するのを支援するために、GitHubでHymbaの最小限の実装を公開しました。チェックしてみてください! barebones-hymba。
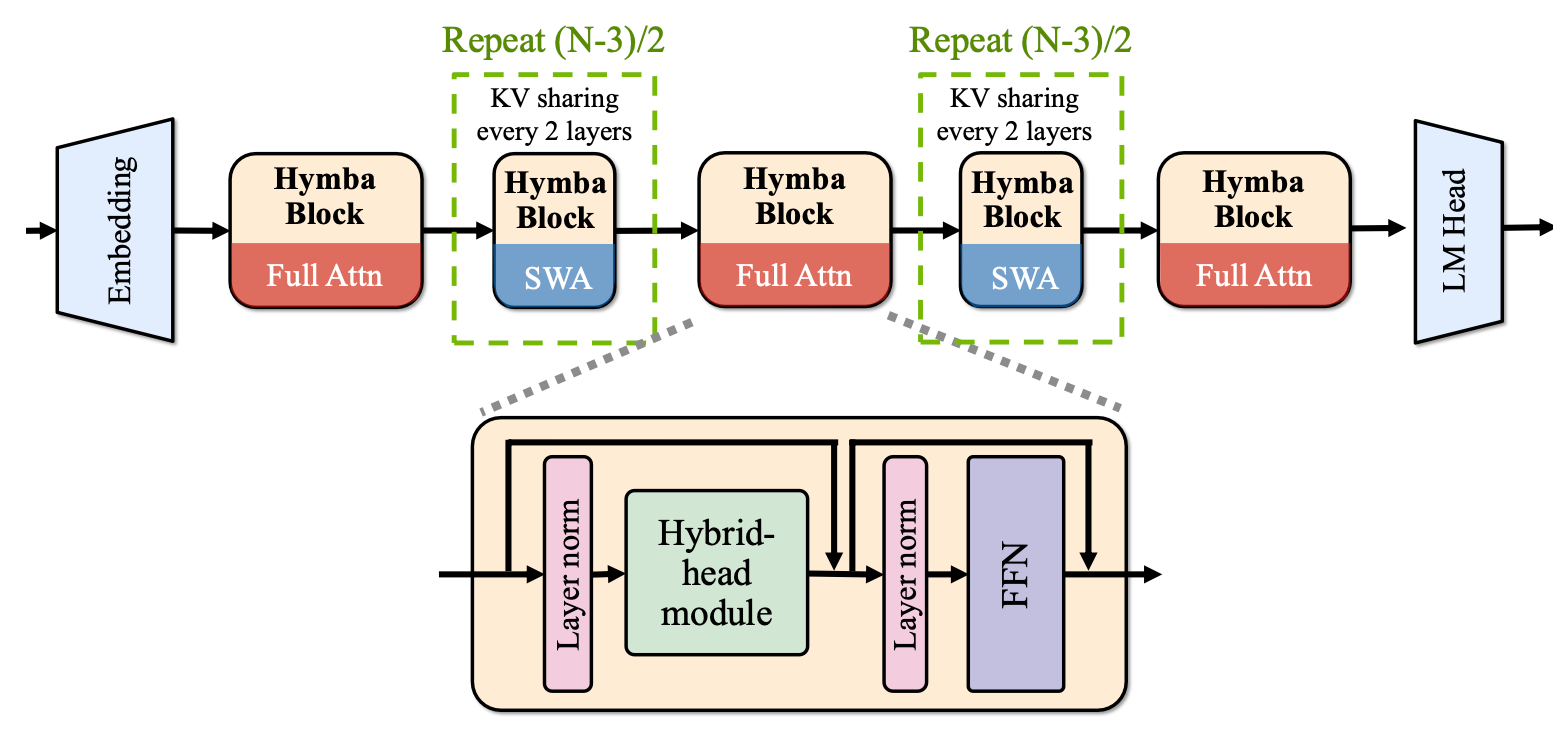
Hymba-1.5B-Baseのモデル埋め込みサイズは1600、Attentionヘッドは25個、MLPの中間次元は5504で、合計32層、16個のSSM状態、3つの完全Attention層、残りはスライディングウィンドウAttentionです。標準のTransformerとは異なり、Hymbaの各Attention層は、標準のAttentionヘッドとMambaヘッドが並列に組み合わされたハイブリッド構成になっています。 さらに、Grouped-Query Attention (GQA) とRotary Position Embeddings (RoPE) を使用しています。
このアーキテクチャの特徴:
- 同じ層内でAttentionヘッドとSSMヘッドを融合し、同じ入力を並列かつ相補的に処理します。
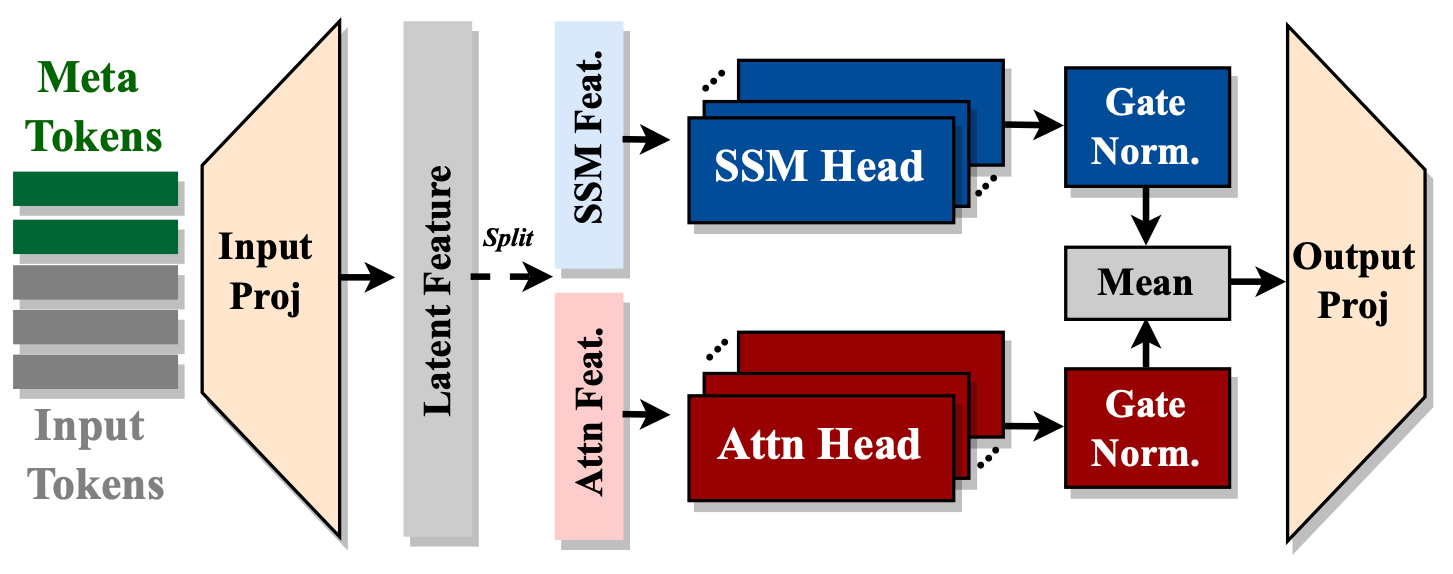
-
入力シーケンスの前に付加されるメタトークンを導入し、すべての後続のトークンと相互作用することで、重要な情報を保存し、Attentionにおける「強制的な注目」の負担を軽減します。
-
クロスレイヤーのKV共有とグローバルローカルAttentionを統合して、メモリと計算効率をさらに向上させます。
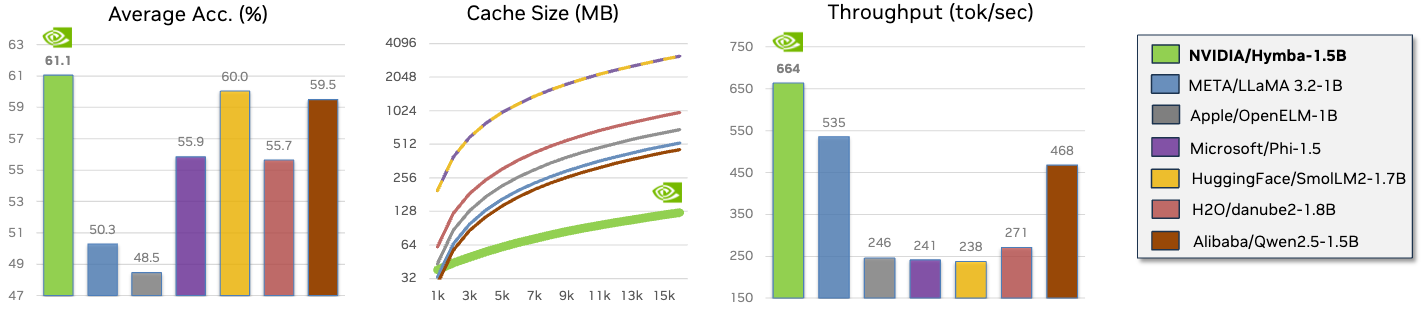
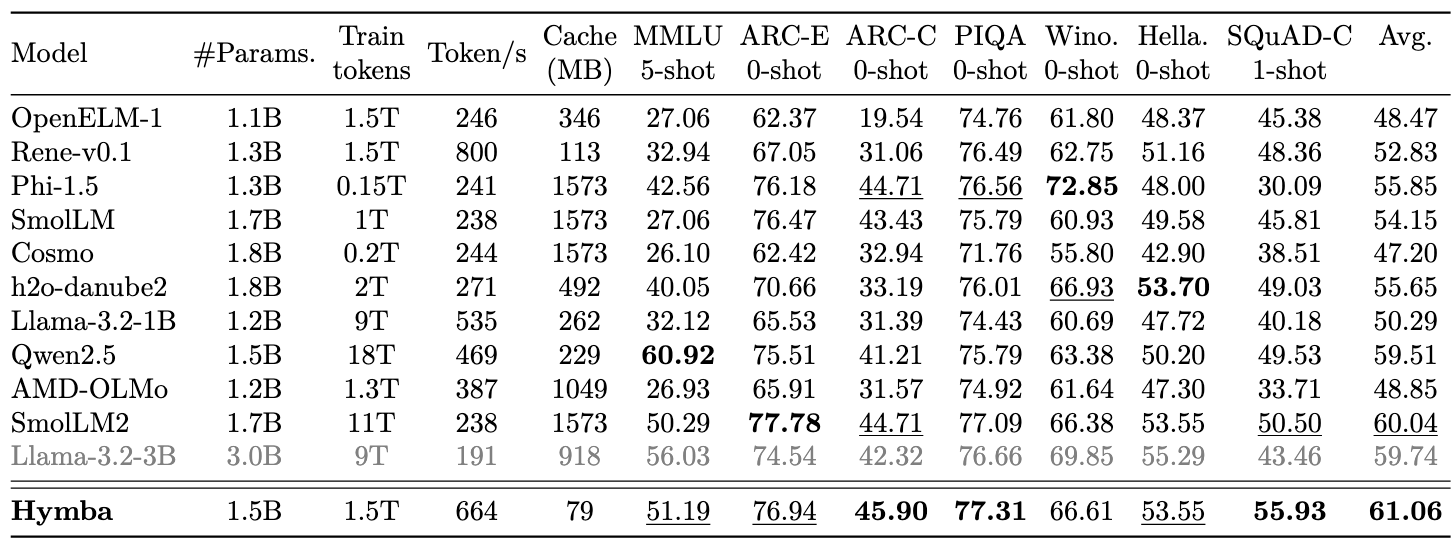
パフォーマンスのハイライト
- Hymba-1.5B-Baseは、すべての20億パラメータ未満の公開モデルを上回っています。
Hymbaの微調整
LMFlowは、大規模言語モデルを微調整するための完全なパイプラインです。
以下の手順は、LMFlowを使用してHymba-1.5B-Baseモデルを微調整する方法の例を示しています。
-
Dockerを使用する
docker pull ghcr.io/tilmto/hymba:v1 docker run --gpus all -v /home/$USER:/home/$USER -it ghcr.io/tilmto/hymba:v1 bash -
LMFlowをインストールする
git clone https://github.com/OptimalScale/LMFlow.git cd LMFlow conda create -n lmflow python=3.9 -y conda activate lmflow conda install mpi4py pip install -e . -
以下のコマンドを使用してモデルを微調整する。
cd LMFlow bash ./scripts/run_finetune_hymba.sh
LMFlowを使用すると、独自のデータセットでモデルを微調整することもできます。必要なことは、データセットをLMFlowデータ形式に変換することだけです。 完全な微調整に加えて、DoRA、LoRA、LISA、Flash Attentionなどの加速技術を使用して、Hymbaを効率的に微調整することもできます。 詳細については、LMFlow for Hymbaのドキュメントを参照してください。
評価
私たちは、LM Evaluation Harnessを使用してモデルを評価しています。評価コマンドは以下の通りです。
git clone --depth 1 https://github.com/EleutherAI/lm-evaluation-harness
git fetch --all --tags
git checkout tags/v0.4.4 # squad completion task is not compatible with the latest version
cd lm-evaluation-harness
pip install -e .
lm_eval --model hf --model_args pretrained=nvidia/Hymba-1.5B-Base,dtype=bfloat16,trust_remote_code=True \
--tasks mmlu \
--num_fewshot 5 \
--batch_size 1 \
--output_path ./hymba_HF_base_lm-results \
--log_samples
lm_eval --model hf --model_args pretrained=nvidia/Hymba-1.5B-Base,dtype=bfloat16,trust_remote_code=True \
--tasks arc_easy,arc_challenge,piqa,winogrande,hellaswag \
--num_fewshot 0 \
--batch_size 1 \
--output_path ./hymba_HF_base_lm-results \
--log_samples
lm_eval --model hf --model_args pretrained=nvidia/Hymba-1.5B-Base,dtype=bfloat16,trust_remote_code=True \
--tasks squad_completion \
--num_fewshot 1 \
--batch_size 1 \
--output_path ./hymba_HF_base_lm-results \
--log_samples
制限事項
このモデルは、元々インターネットから収集された有毒な言語、不安全なコンテンツ、社会的偏見を含むデータで学習されています。したがって、モデルはそれらの偏見を増幅し、特に有毒なプロンプトが与えられた場合に有毒な応答を返す可能性があります。モデルは、不正確な回答を生成したり、重要な情報を省略したり、関連性のないまたは冗長なテキストを含んだりして、社会的に受け入れられないまたは望ましくないテキストを生成する可能性があります。
テストによると、このモデルはジェイルブレイク攻撃に対して脆弱です。このモデルをRAGまたはエージェント環境で使用する場合、ユーザーが制御するモデルの出力によるセキュリティおよび安全上のリスクが意図されたユースケースと一致するように、強力な出力検証コントロールを推奨します。
倫理的な考慮事項
NVIDIAは、信頼できるAIは共同の責任であると考えており、幅広いAIアプリケーションの開発を可能にするためのポリシーと実践を確立しています。サービス利用規約に従ってダウンロードまたは使用する場合、開発者は自社のモデルチームと協力して、このモデルが関連する業界とユースケースの要件を満たし、予期しない製品の誤用に対処することを確認する必要があります。 セキュリティの脆弱性またはNVIDIA AIに関する懸念事項は、こちらから報告してください。
引用
@misc{dong2024hymbahybridheadarchitecturesmall,
title={Hymba: A Hybrid-head Architecture for Small Language Models},
author={Xin Dong and Yonggan Fu and Shizhe Diao and Wonmin Byeon and Zijia Chen and Ameya Sunil Mahabaleshwarkar and Shih-Yang Liu and Matthijs Van Keirsbilck and Min-Hung Chen and Yoshi Suhara and Yingyan Lin and Jan Kautz and Pavlo Molchanov},
year={2024},
eprint={2411.13676},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2411.13676},
}
🔧 技術詳細
- モデルの埋め込みサイズ: 1600
- Attentionヘッドの数: 25
- MLPの中間次元: 5504
- 総層数: 32
- SSM状態の数: 16
- 完全Attention層の数: 3
- 残りの層: スライディングウィンドウAttention
📄 ライセンス
このモデルは、NVIDIA Open Model License Agreementの下で公開されています。