🚀 WizardCoderとWizardLMシリーズモデルプロジェクト
このプロジェクトは、WizardCoder、WizardMath、WizardLMなどの一連のモデルを中心に展開されています。これらのモデルは、コード生成、数学的推論、一般的な質問応答などの複数の分野で卓越した性能を発揮し、自然言語処理と人工知能研究に強力なツールと参考資料を提供しています。
プロジェクトの説明
これは公式リポジトリのコピーであり、結果を再現するための研究目的のみで使用されます。著作権の問題がある場合は、ご連絡ください。
プロジェクトのリンク
🤗 HFリポジトリ •🐱 Githubリポジトリ • 🐦 Twitter • 📃 [WizardLM] • 📃 [WizardCoder] • 📃 [WizardMath]
👋 Discordに参加しましょう
✨ 主な機能
モデル情報
| 属性 |
詳細 |
| ライセンス |
llama2 |
| 評価指標 |
code_eval |
| ライブラリ名 |
transformers |
| タグ |
code |
モデルインデックス
- 名称:WizardCoder-Python-34B-V1.0
- 結果:
- タスクタイプ:テキスト生成
- データセット:openai_humaneval(HumanEval)
- 指標:
- 名称:pass@1
- タイプ:pass@1
- 値:0.555
- 検証状態:未検証
📚 ドキュメント
最新情報
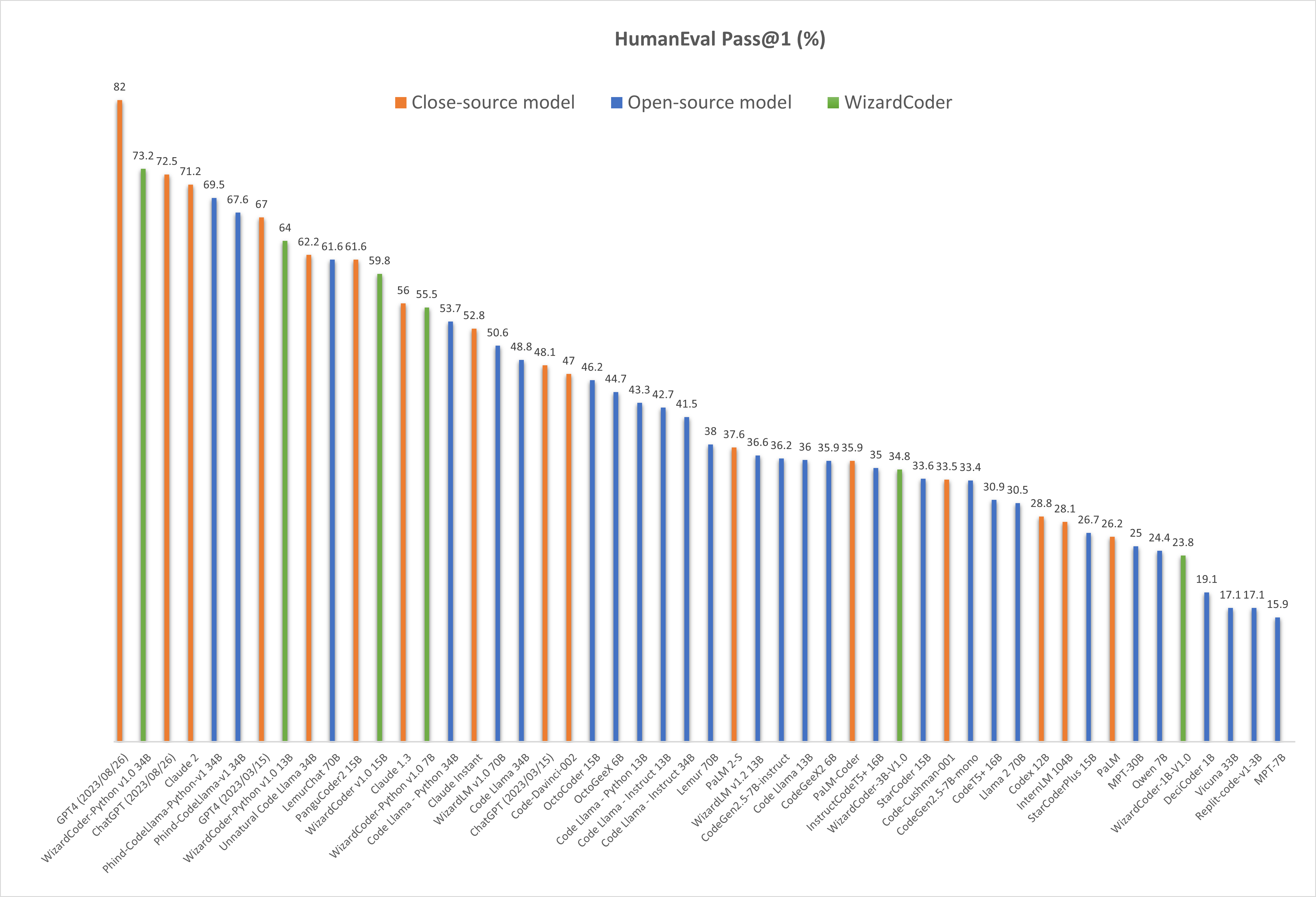
- 🔥🔥🔥[2023/08/26] WizardCoder-Python-34B-V1.0 をリリースしました。HumanEvalベンチマーク で 73.2 pass@1 を達成し、GPT4 (2023/03/15)、ChatGPT-3.5、Claude2 を上回りました。
- [2023/06/16] WizardCoder-15B-V1.0 をリリースしました。HumanEvalベンチマーク で 57.3 pass@1 を達成し、Claude-Plus (+6.8)、Bard (+15.3)、InstructCodeT5+ (+22.3) を上回りました。
❗注意:GPT4とChatGPT - 3.5には2つのHumanEval結果があります。67.0と48.1は OpenAI の公式GPT4レポート(2023/03/15)によるものです。82.0と72.5は最新のAPI(2023/08/26)を使用してテストした結果です。
WizardCoderシリーズモデルの性能
WizardMathシリーズモデルの性能
- 私たちの WizardMath-70B-V1.0 モデルは、GSM8Kベンチマークで、ChatGPT 3.5、Claude Instant 1、PaLM 2 540B を含むいくつかの閉ソース大規模言語モデルを僅かに上回っています。
- 私たちの WizardMath-70B-V1.0 モデルは、GSM8kベンチマーク で 81.6 pass@1 を達成し、現在の最良のオープンソース大規模言語モデルより 24.8 点高くなりました。また、MATHベンチマーク で 22.7 pass@1 を達成し、現在の最良のオープンソース大規模言語モデルより 9.2 点高くなりました。
WizardLMシリーズモデルの性能
- [08/09/2023] WizardLM-70B-V1.0 モデルをリリースしました。完全なモデル重み。
| モデル |
チェックポイント |
論文 |
MT - Bench |
AlpacaEval |
GSM8k |
HumanEval |
ライセンス |
| WizardLM-70B-V1.0 |
🤗 HFリンク |
📃近日公開予定 |
7.78 |
92.91% |
77.6% |
50.6 |
Llama 2ライセンス |
| WizardLM-13B-V1.2 |
🤗 HFリンク |
|
7.06 |
89.17% |
55.3% |
36.6 |
Llama 2ライセンス |
| WizardLM-13B-V1.1 |
🤗 HFリンク |
|
6.76 |
86.32% |
|
25.0 |
非商用目的 |
| WizardLM-30B-V1.0 |
🤗 HFリンク |
|
7.01 |
|
|
37.8 |
非商用目的 |
| WizardLM-13B-V1.0 |
🤗 HFリンク |
|
6.35 |
75.31% |
|
24.0 |
非商用目的 |
| WizardLM-7B-V1.0 |
🤗 HFリンク |
📃 [WizardLM] |
|
|
|
19.1 |
非商用目的 |
モデルの比較
🔥 下の図は、私たちの WizardCoder-Python-34B-V1.0がこのベンチマークで2位にランクインしている ことを示しています。GPT4 (2023/03/15, 73.2 vs. 67.0)、ChatGPT - 3.5 (73.2 vs. 72.5)、Claude2 (73.2 vs. 71.2) を上回っています。
プロンプト形式
"Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Response:"
推論デモスクリプト
私たちは ここ に推論デモコードを提供しています。
📄 ライセンス
このプロジェクトはllama2ライセンスを使用しています。
🔗 引用情報
このリポジトリ内のデータ、方法、またはコードを使用した場合は、以下の論文を引用してください。
@article{luo2023wizardcoder,
title={WizardCoder: Empowering Code Large Language Models with Evol-Instruct},
author={Luo, Ziyang and Xu, Can and Zhao, Pu and Sun, Qingfeng and Geng, Xiubo and Hu, Wenxiang and Tao, Chongyang and Ma, Jing and Lin, Qingwei and Jiang, Daxin},
journal={arXiv preprint arXiv:2306.08568},
year={2023}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応