%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
JA
Pathumma Llm Text 1.0.0
PathummaLLM-text-1.0.0-7Bは、タイ語、中国語、英語をサポートする70億パラメータの大規模言語モデルで、OpenThaiLLM-Prebuiltをベースに指令微調整を行い、RAG、制約生成、推論タスクを最適化しています。

ダウンロード数 2,362
リリース時間 : 10/22/2024
モデル概要
PathummaLLM-text-1.0.0-7Bは多言語大規模言語モデルで、タイ語、中国語、英語をサポートし、様々な言語シナリオに適しており、特に検索強化生成(RAG)、制約生成、推論タスクが最適化されています。
モデル特徴
多言語サポート
タイ語、中国語、英語をサポートし、様々な言語シナリオに適しています。
強力な性能
Openthaigpt1.5-7b-instructと比較して、競争力のある性能を示します。
アプリケーション最適化
検索強化生成(RAG)、制約生成、推論タスクに対して最適化されています。
モデル能力
多言語テキスト生成
検索強化生成(RAG)
制約生成
推論タスク
使用事例
ビジネス分析
損益分岐点計算
会社が損益分岐点に達するために販売する必要がある製品の数量を計算します。
モデルは損益分岐点を正確に計算し、説明することができます。
多言語アプリケーション
多言語質問応答
タイ語、中国語、英語をサポートする質問応答システムです。
モデルは3つの言語間をスムーズに切り替えて質問に答えることができます。
🚀 PathummaLLM-text-1.0.0-7B:タイ語、中国語、英語対応の大規模言語モデル
PathummaLLM-text-1.0.0-7Bは、70億のパラメータを持つ大規模言語モデルで、タイ語 🇹🇭、中国語 🇨🇳、英語 🇬🇧 をサポートしています。このモデルはOpenThaiLLM-Prebuiltをベースに、指令に基づく微調整が行われています。Openthaigpt1.5-7b-instructと比較して、競争力のある性能を発揮し、アプリケーションシナリオ、検索強化生成(RAG)、制約付き生成、推論タスクなどに最適化されています。

🚀 クイックスタート
このセクションでは、PathummaLLM-text-1.0.0-7Bモデルをどのようにすぐに使うかを説明します。
環境要件
Qwen2.5のコードは最新のHugging face transformers ライブラリに統合されています。最新バージョンの transformers を使用することをおすすめします。
transformers<4.37.0 を使用すると、以下のエラーが発生します。
KeyError: 'qwen2'
コード例
以下は、apply_chat_template を使用してトークナイザーとモデルをロードし、内容を生成するコードスニペットです。
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # モデルをロードするデバイス
model = AutoModelForCausalLM.from_pretrained(
"nectec/Pathumma-llm-text-1.0.0",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("nectec/Pathumma-llm-text-1.0.0")
prompt = "บริษัท A มีต้นทุนคงที่ 100,000 บาท และต้นทุนผันแปรต่อหน่วย 50 บาท ขายสินค้าได้ในราคา 150 บาทต่อหน่วย ต้องขายสินค้าอย่างน้อยกี่หน่วยเพื่อให้ถึงจุดคุ้มทุน?"
messages = [
{"role": "system", "content": "You are Pathumma LLM, created by NECTEC. Your are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=4096,
repetition_penalty=1.1,
temperature = 0.4
)
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
GGUF 実装例
%pip install --quiet https://github.com/abetlen/llama-cpp-python/releases/download/v0.2.90-cu124/llama_cpp_python-0.2.90-cp310-cp310-linux_x86_64.whl
import transformers
import torch
from llama_cpp import Llama
import os
import requests
local_dir = "your local dir"
directory_path = r'{local_dir}/Pathumma-llm-text-1.0.0'
if not os.path.exists(directory_path):
os.mkdir(directory_path)
if not os.path.exists(f'{local_dir}/Pathumma-llm-text-1.0.0/Pathumma-llm-it-7b-Q4_K_M.gguf'):
!wget -O f'{local_dir}/Pathumma-llm-text-1.0.0/Pathumma-llm-it-7b-Q4_K_M.gguf' "https://huggingface.co/nectec/Pathumma-llm-text-1.0.0/resolve/main/Pathumma-llm-it-7b-Q4_K_M.gguf?download=true"
# Llamaモデルを初期化
llm = Llama(model_path=f'{local_dir}/Pathumma-llm-text-1.0.0/Pathumma-llm-it-7b-Q4_K_M.gguf', n_gpu_layers=-1, n_ctx=8192,verbose=False)
tokenizer = transformers.AutoTokenizer.from_pretrained("nectec/Pathumma-llm-text-1.0.0")
memory = [{'content': 'You are Pathumma LLM, created by NECTEC (National Electronics and Computer Technology Center). Your are a helpful assistant.', 'role': 'system'},]
def generate(instuction,memory=memory):
memory.append({'content': instuction, 'role': 'user'})
p = tokenizer.apply_chat_template(
memory,
tokenize=False,
add_generation_prompt=True
)
response = llm(
p,
max_tokens=2048,
temperature=0.2,
top_p=0.95,
repeat_penalty=1.1,
top_k=40,
min_p=0.05,
stop=["<|im_end|>"]
)
output = response['choices'][0]['text']
memory.append({'content': output, 'role': 'assistant'})
return output
print(generate("คุณคือใคร"))
✨ 主な機能
- 多言語対応:タイ語、中国語、英語をサポートし、様々な言語シナリオに対応します。
- 高い性能:Openthaigpt1.5-7b-instructと比較して、競争力のある性能を発揮します。
- 最適化:検索強化生成(RAG)、制約付き生成、推論タスクに最適化されています。
📚 ドキュメント
モデル詳細
リリースノートについては、ブログ を参照してください。 テキスト大規模言語モデルの詳細情報については、このブログ を参照してください。
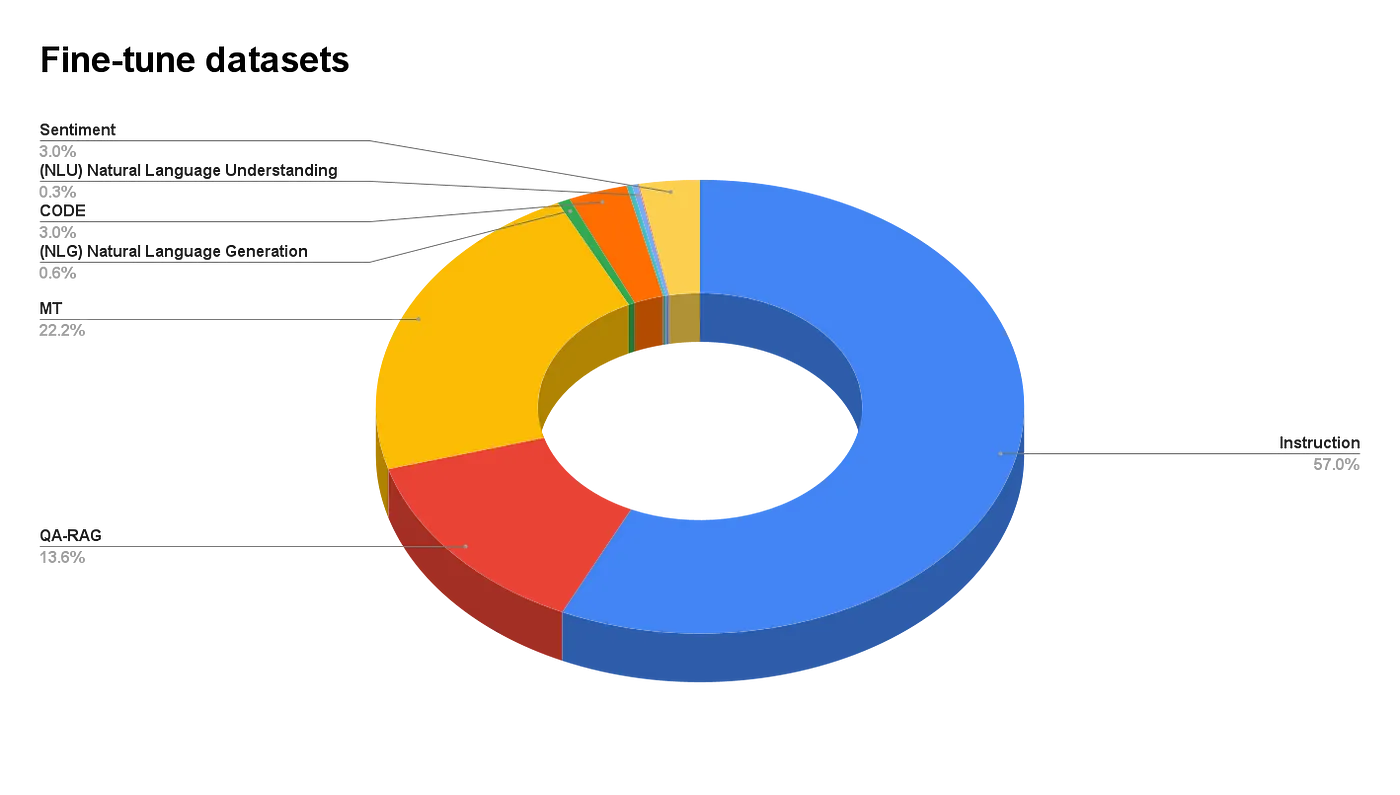
データセット比率
評価性能
| モデル | m3exam | thaiexam | xcopa | belebele | xnli | thaisentiment | XL sum | flores200 英語 > タイ語 | flores200 タイ語 > 英語 | iapp | AVG(NLU) | AVG(MC) | AVG(NLG) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pathumma-llm-text-1.0.0 | 55.02 | 51.32 | 83 | 77.77 | 40.11 | 41.29 | 16.9286253 | 26.54 | 51.88 | 41.28 | 60.54 | 53.17 | 34.16 |
| Openthaigpt1.5-7b-instruct | 54.01 | 52.04 | 85.4 | 79.44 | 39.7 | 50.24 | 18.11 | 29.09 | 29.58 | 32.49 | 63.70 | 53.03 | 27.32 |
| SeaLLMs-v3-7B-Chat | 51.43 | 51.33 | 83.4 | 78.22 | 34.05 | 39.57 | 20.27 | 32.91 | 28.8 | 48.12 | 58.81 | 51.38 | 32.53 |
| llama-3-typhoon-v1.5-8B | 43.82 | 41.95 | 81.6 | 71.89 | 33.35 | 38.45 | 16.66 | 31.94 | 28.86 | 54.78 | 56.32 | 42.89 | 33.06 |
| Meta-Llama-3.1-8B-Instruct | 45.11 | 43.89 | 73.4 | 74.89 | 33.49 | 45.45 | 21.61 | 30.45 | 32.28 | 68.57 | 56.81 | 44.50 | 38.23 |
🔧 技術詳細
ベースモデル
- ベースモデル:nectec/OpenThaiLLM-Prebuilt-7B
- ベースモデルの関係:微調整
指標
- 正解率
タスクタイプ
- テキスト生成
タグ
- 化学
- 生物学
- 金融
- 法律
- コード
- 医学
- テキスト生成推論
📄 ライセンス
このプロジェクトはApache-2.0ライセンスの下で提供されています。
👥 貢献者
LLMチーム
- Pakawat Phasook (pakawat.phas@kmutt.ac.th)
- Jessada Pranee (jessada.pran@kmutt.ac.th)
- Arnon Saeoung (anon.saeoueng@gmail.com)
- Kun Kerdthaisong (kun.ker@dome.tu.ac.th)
- Kittisak Sukhantharat (kittisak.suk@stu.nida.ac.th)
- Piyawat Chuangkrud (piyawat@it.kmitl.ac.th)
- Chaianun Damrongrat (chaianun.damrongrat@nectec.or.th)
- Sarawoot Kongyoung (sarawoot.kongyoung@nectec.or.th)
オーディオチーム
- Pattara Tipaksorn (pattara.tip@ncr.nstda.or.th)
- Wayupuk Sommuang (wayupuk.som@dome.tu.ac.th)
- Oatsada Chatthong (atsada.cha@dome.tu.ac.th)
- Kwanchiva Thangthai (kwanchiva.thangthai@nectec.or.th)
ビジョンチーム
- Thirawarit Pitiphiphat (60010474@kmitl.ac.th)
- Peerapas Ngokpon (jamesselmon78169@gmail.com)
- Theerasit Issaranon (theerasit.issaranon@nectec.or.th)
📖 引用
このプロジェクトが役立った場合は、以下を引用してください。
@misc{qwen2.5,
title = {Qwen2.5: A Party of Foundation Models},
url = {https://qwenlm.github.io/blog/qwen2.5/},
author = {Qwen Team},
month = {September},
year = {2024}
}
@article{qwen2,
title={Qwen2 Technical Report},
author={An Yang and Baosong Yang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Zhou and Chengpeng Li and Chengyuan Li and Dayiheng Liu and Fei Huang and Guanting Dong and Haoran Wei and Huan Lin and Jialong Tang and Jialin Wang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Ma and Jin Xu and Jingren Zhou and Jinze Bai and Jinzheng He and Junyang Lin and Kai Dang and Keming Lu and Keqin Chen and Kexin Yang and Mei Li and Mingfeng Xue and Na Ni and Pei Zhang and Peng Wang and Ru Peng and Rui Men and Ruize Gao and Runji Lin and Shijie Wang and Shuai Bai and Sinan Tan and Tianhang Zhu and Tianhao Li and Tianyu Liu and Wenbin Ge and Xiaodong Deng and Xiaohuan Zhou and Xingzhang Ren and Xinyu Zhang and Xipin Wei and Xuancheng Ren and Yang Fan and Yang Yao and Yichang Zhang and Yu Wan and Yunfei Chu and Yuqiong Liu and Zeyu Cui and Zhenru Zhang and Zhihao Fan},
journal={arXiv preprint arXiv:2407.10671},
year={2024}
}
💬 サポートコミュニティ
Discordコミュニティに参加して、交流することができます。
Phi 2 GGUF
その他
Phi-2はマイクロソフトが開発した小型ながら強力な言語モデルで、27億のパラメータを持ち、効率的な推論と高品質なテキスト生成に特化しています。
大規模言語モデル 複数言語対応
P
TheBloke
41.5M
205
Roberta Large
MIT
マスク言語モデリングの目標で事前学習された大型英語言語モデルで、改良されたBERTの学習方法を採用しています。
大規模言語モデル 英語
R
FacebookAI
19.4M
212
Distilbert Base Uncased
Apache-2.0
DistilBERTはBERT基礎モデルの蒸留バージョンで、同等の性能を維持しながら、より軽量で高効率です。シーケンス分類、タグ分類などの自然言語処理タスクに適しています。
大規模言語モデル 英語
D
distilbert
11.1M
669
Llama 3.1 8B Instruct GGUF
Meta Llama 3.1 8B Instructは多言語大規模言語モデルで、多言語対話ユースケースに最適化されており、一般的な業界ベンチマークで優れた性能を発揮します。
大規模言語モデル 英語
L
modularai
9.7M
4
Xlm Roberta Base
MIT
XLM - RoBERTaは、100言語の2.5TBのフィルタリングされたCommonCrawlデータを使って事前学習された多言語モデルで、マスク言語モデリングの目標で学習されています。
大規模言語モデル 複数言語対応
X
FacebookAI
9.6M
664
Roberta Base
MIT
Transformerアーキテクチャに基づく英語の事前学習モデルで、マスク言語モデリングの目標を通じて大量のテキストでトレーニングされ、テキスト特徴抽出と下流タスクの微調整をサポートします。
大規模言語モデル 英語
R
FacebookAI
9.3M
488
Opt 125m
その他
OPTはMeta AIが公開したオープンプリトレーニングトランスフォーマー言語モデルスイートで、パラメータ数は1.25億から1750億まであり、GPT-3シリーズの性能に対抗することを目指しつつ、大規模言語モデルのオープンな研究を促進するものです。
大規模言語モデル 英語
O
facebook
6.3M
198
1
transformersライブラリに基づく事前学習モデルで、様々なNLPタスクに適用可能
大規模言語モデル Transformers
Transformers
1
unslothai
6.2M
1
Llama 3.1 8B Instruct
Llama 3.1はMetaが発表した多言語大規模言語モデルシリーズで、8B、70B、405Bのパラメータ規模を持ち、8種類の言語とコード生成をサポートし、多言語対話シーンを最適化しています。
大規模言語モデル Transformers 複数言語対応
L
meta-llama
5.7M
3,898
T5 Base
Apache-2.0
T5ベーシック版はGoogleによって開発されたテキスト-to-テキスト変換Transformerモデルで、パラメータ規模は2.2億で、多言語NLPタスクをサポートしています。
大規模言語モデル 複数言語対応
T
google-t5
5.4M
702
おすすめAIモデル
Llama 3 Typhoon V1.5x 8b Instruct
タイ語専用に設計された80億パラメータの命令モデルで、GPT-3.5-turboに匹敵する性能を持ち、アプリケーションシナリオ、検索拡張生成、制限付き生成、推論タスクを最適化
大規模言語モデル Transformers 複数言語対応
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-TinyはSODAデータセットでトレーニングされた超小型対話モデルで、エッジデバイス推論向けに設計されており、体積はCosmo-3Bモデルの約2%です。
対話システム Transformers 英語
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
RoBERTaアーキテクチャに基づく中国語抽出型QAモデルで、与えられたテキストから回答を抽出するタスクに適しています。
質問応答システム 中国語
R
uer
2,694
98