%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
モデル概要
モデル特徴
モデル能力
使用事例
🚀 VisualPRM-8B-v1.1
これはVisualPRM-8Bの新しいバージョンで、VisualPRM-8Bよりも優れた性能を発揮します。VisualPRM-8B-v1.1を評価モデルとして使用することで、InternVL3の推論能力がさらに向上します。
[📂 GitHub] [📄 Paper] [📋 Blog] [🤖 model] [📊 dataset] [📈 benchmark]

🚀 クイックスタート
このセクションでは、VisualPRM-8B-v1.1の概要と推論方法について説明します。
✨ 主な機能
- 80億パラメータを持つ高度なマルチモーダルプロセス報酬モデル(PRM)で、Best-of-N(BoN)評価戦略を用いて、異なるモデル規模とファミリの既存のマルチモーダル大規模言語モデル(MLLM)の推論能力を向上させます。
- 3種類のMLLMと4つの異なるモデル規模の推論性能を向上させます。高能力なInternVL2.5-78Bに適用した場合でも、7つのマルチモーダル推論ベンチマーク全体で5.9ポイントの向上を達成します。
- 実験結果によると、BoN評価時にアウトカム報酬モデルや自己一貫性よりも優れた性能を発揮します。
📚 ドキュメント
紹介
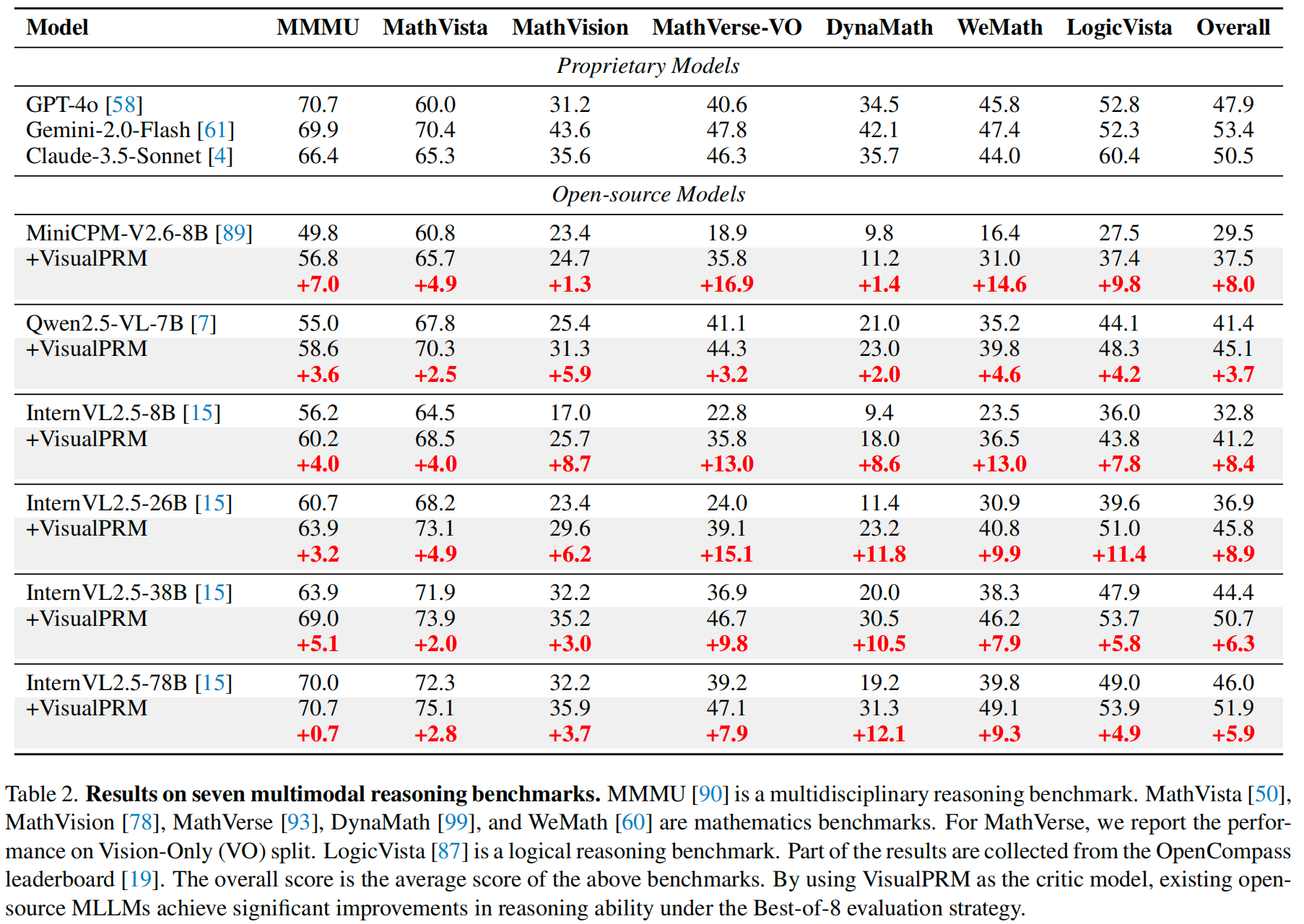
私たちは、80億パラメータを持つ高度なマルチモーダルプロセス報酬モデル(PRM)であるVisualPRMを紹介します。このモデルは、Best-of-N(BoN)評価戦略を用いて、異なるモデル規模とファミリの既存のマルチモーダル大規模言語モデル(MLLM)の推論能力を向上させます。具体的には、私たちのモデルは3種類のMLLMと4つの異なるモデル規模の推論性能を向上させます。高能力なInternVL2.5-78Bに適用した場合でも、7つのマルチモーダル推論ベンチマーク全体で5.9ポイントの向上を達成します。 実験結果によると、BoN評価時にアウトカム報酬モデルや自己一貫性よりも優れた性能を発揮します。マルチモーダルPRMのトレーニングを容易にするために、自動化されたデータパイプラインを使用してマルチモーダルプロセス監督データセットVisualPRM400Kを構築しました。マルチモーダルPRMの評価には、人間によるステップごとの正解ラベル付けが行われたベンチマークであるVisualProcessBenchを提案し、マルチモーダル推論タスクにおけるPRMの誤ったステップを検出する能力を測定します。私たちの研究が、将来のさらなる研究にインスピレーションを与え、MLLMの開発に貢献できることを期待しています。

性能

Transformersを使用した推論
import torch
import torchvision.transforms as T
from PIL import Image
from transformers import AutoModel, AutoTokenizer
from torchvision.transforms.functional import InterpolationMode
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image, input_size=448, max_num=12):
image = Image.open(image).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
def main():
path = 'OpenGVLab/VisualPRM-8B-v1.1'
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
model = AutoModel.from_pretrained(
path,
trust_remote_code=True,
low_cpu_mem_usage=True,
torch_dtype=torch.bfloat16,
).eval().cuda()
question = 'Find m \\angle 3.'
response_a = """
To find the measure of \\angle 3, we need to use the properties of the angles in the given geometric figure.
1. \\angle EDC is a right angle, and it is split into \\angle EDF and \\angle 3.
2. We know that \\angle EDF = 39^\\circ because it is labeled in the diagram.
3. Since \\angle EDC is 90^\\circ, we can set up the equation for \\angle 3: \\angle EDC = \\angle EDF + \\angle 3
4. Substituting the known values, we get: 90^\\circ = 39^\\circ + \\angle 3
5. Solving for \\angle 3: \\angle 3 = 90^\\circ - 39^\\circ
6. Simplifying the equation: \\angle 3 = 51^\\circ
Final answer: 51^\\circ
""".strip()
response_b = """
To find \\( m \\angle 3 \\), we need to analyze the given geometric figure carefully.
1. Recognize that \\( \\angle 3 \\) is part of triangle \\( BCE \\). Since \\( \\angle 1 \\) is given as 48° and \\( \\angle 2 \\) is a right angle (90°), we can use the properties of a right triangle to find \\( \\angle 3 \\).
2. The sum of the angles in any triangle is 180°. Therefore, in triangle \\( BCE \\): \[ \\angle 1 + \\angle 2 + \\angle 3 = 180° \]
3. Substitute the known values: \[ 48° + 90° + \\angle 3 = 180° \]
4. Solve for \\( \\angle 3 \\): \[ \\angle 3 = 180° - 48° - 90° = 42° \]
Thus, the measure of \\( \\angle 3 \\) is 42°.
Final answer: 42
""".strip()
response_list = [
response_a,
response_b,
]
image = 'examples/image.png'
pixel_values = load_image(image).to(torch.bfloat16).cuda()
sorted_response_list = model.select_best_response(
tokenizer=tokenizer,
question=question,
response_list=response_list,
pixel_values=pixel_values,
return_scores=True,
)
print('Best response:', sorted_response_list[0][0])
print('Highest score:', sorted_response_list[0][1])
if __name__ == '__main__':
main()
ライセンス
このプロジェクトはMITライセンスの下で公開されています。このプロジェクトは、Apache License 2.0でライセンスされている事前学習済みのinternlm2_5-7b-chatをコンポーネントとして使用しています。
引用
もしこのプロジェクトがあなたの研究に役立った場合、以下の文献を引用してください。
@article{wang2025visualprm,
title={VisualPRM: An Effective Process Reward Model for Multimodal Reasoning},
author={Wang, Weiyun and Gao, Zhangwei and Chen, Lianjie and Chen, Zhe and Zhu, Jinguo and Zhao, Xiangyu and Liu, Yangzhou and Cao, Yue and Ye, Shenglong and Zhu, Xizhou and others},
journal={arXiv preprint arXiv:2503.10291},
year={2025}
}
情報テーブル
| 属性 | 詳情 |
|---|---|
| パイプラインタグ | 画像-テキストからテキスト |
| ライブラリ名 | Transformers |
| ベースモデル | OpenGVLab/InternVL2_5-8B、OpenGVLab/InternVL2_5-8B-MPO |
| ベースモデルの関係 | ファインチューニング |
| データセット | OpenGVLab/MMPR-v1.2、OpenGVLab/VisualPRM400K-v1.1 |
| 言語 | 多言語 |
| タグ | internvl、custom_code |
 Safetensors 英語
Safetensors 英語