%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
モデル概要
モデル特徴
モデル能力
使用事例
🚀 T5ベースをSQUaD v1.1ポルトガル語版で質問応答(QA)にファインチューニング
このモデルは、ポルトガル語の質問応答(QA)タスクに特化しており、SQUaD v1.1ポルトガル語版データセットを使ってT5ベースモデルをファインチューニングしたものです。
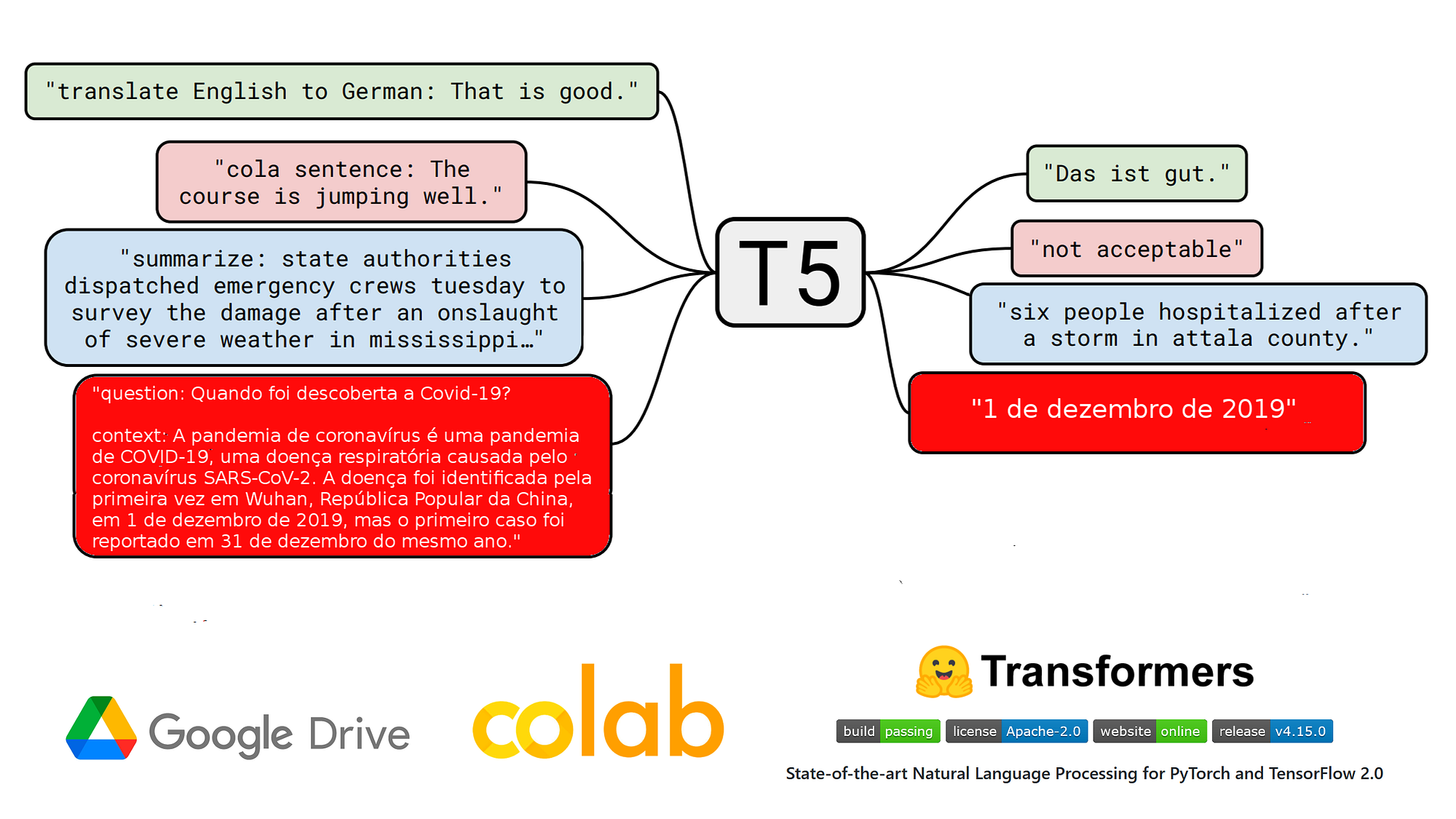
🚀 クイックスタート
このモデルを使って推論を行うには、以下のコード例を参考にしてください。
推論コード例
# install pytorch: check https://pytorch.org/
# !pip install transformers
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
# model & tokenizer
model_name = "pierreguillou/t5-base-qa-squad-v1.1-portuguese"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
# parameters
max_target_length=32
num_beams=1
early_stopping=True
input_text = 'question: Quando foi descoberta a Covid-19? context: A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China, em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano.'
label = '1 de dezembro de 2019'
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(inputs["input_ids"],
max_length=max_target_length,
num_beams=num_beams,
early_stopping=early_stopping
)
pred = tokenizer.decode(outputs[0], skip_special_tokens=True, clean_up_tokenization_spaces=True)
print('true answer |', label)
print('pred |', pred)
また、pipelineを使うこともできますが、入力シーケンスのmax_lengthに関する問題があるようです。
!pip install transformers
import transformers
from transformers import pipeline
# model
model_name = "pierreguillou/t5-base-qa-squad-v1.1-portuguese"
# parameters
max_target_length=32
num_beams=1
early_stopping=True
clean_up_tokenization_spaces=True
input_text = 'question: Quando foi descoberta a Covid-19? context: A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China, em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano.'
label = '1 de dezembro de 2019'
text2text = pipeline(
"text2text-generation",
model=model_name,
max_length=max_target_length,
num_beams=num_beams,
early_stopping=early_stopping,
clean_up_tokenization_spaces=clean_up_tokenization_spaces
)
pred = text2text(input_text)
print('true answer |', label)
print('pred |', pred)
✨ 主な機能
- ポルトガル語の質問応答:ポルトガル語での質問に対して適切な回答を生成します。
- Test2Text-Generation:Test2Text-Generationの目的を使って訓練されています。
📦 インストール
このモデルを使うには、transformersライブラリをインストールする必要があります。
!pip install transformers
📚 ドキュメント
概要
t5-base-qa-squad-v1.1-portuguese は、ポルトガル語の質問応答(QA)モデルです。2022年1月27日にGoogle Colabで、Neuralmindの unicamp-dl/ptt5-base-portuguese-vocab モデルを、Deep Learning Brasilグループ のSQUAD v1.1ポルトガル語版データセットを使ってファインチューニングしました。
T5ベースモデルとファインチューニングデータセットのサイズが小さいため、訓練が終了する前に過学習してしまいました。検証データセットでの最終的なメトリクスは以下の通りです。
- f1:79.3
- exact_match:67.3983
他のポルトガル語QAモデル
SQUAD v1.1でファインチューニングされた他のポルトガル語QAモデルもチェックしてみてください。
ブログ記事
NLP nas empresas | Como eu treinei um modelo T5 em português na tarefa QA no Google Colab (2022年1月27日)
ウィジェットとアプリ
このページのウィジェットでこのモデルをテストすることができます。また、QA App | T5 base pt を使って、SQuAD v1.1 ptデータセットでファインチューニングされたT5ベースモデルを質問応答タスクで使用することもできます。
🔧 技術詳細
ノートブック
ファインチューニングのノートブック (HuggingFace_Notebook_t5-base-portuguese-vocab_question_answering_QA_squad_v11_pt.ipynb) はGitHubにあります。
ハイパーパラメータ
# do training and evaluation
do_train = True
do_eval= True
# batch
batch_size = 4
gradient_accumulation_steps = 3
per_device_train_batch_size = batch_size
per_device_eval_batch_size = per_device_train_batch_size*16
# LR, wd, epochs
learning_rate = 1e-4
weight_decay = 0.01
num_train_epochs = 10
fp16 = True
# logs
logging_strategy = "steps"
logging_first_step = True
logging_steps = 3000 # if logging_strategy = "steps"
eval_steps = logging_steps
# checkpoints
evaluation_strategy = logging_strategy
save_strategy = logging_strategy
save_steps = logging_steps
save_total_limit = 3
# best model
load_best_model_at_end = True
metric_for_best_model = "f1" #"loss"
if metric_for_best_model == "loss":
greater_is_better = False
else:
greater_is_better = True
# evaluation
num_beams = 1
訓練結果
Num examples = 87510
Num Epochs = 10
Instantaneous batch size per device = 4
Total train batch size (w. parallel, distributed & accumulation) = 12
Gradient Accumulation steps = 3
Total optimization steps = 72920
Step Training Loss Exact Match F1
3000 0.776100 61.807001 75.114517
6000 0.545900 65.260170 77.468930
9000 0.460500 66.556291 78.491938
12000 0.393400 66.821192 78.745397
15000 0.379800 66.603595 78.815515
18000 0.298100 67.578051 79.287899
21000 0.303100 66.991485 78.979669
24000 0.251600 67.275307 78.929923
27000 0.237500 66.972564 79.333612
30000 0.220500 66.915799 79.236574
33000 0.182600 67.029328 78.964212
36000 0.190600 66.982025 79.086125