%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
モデル概要
モデル特徴
モデル能力
使用事例
🚀 DeepSeek-V2: 強力で経済的かつ効率的なエキスパート混合言語モデル
DeepSeek-V2は、経済的なトレーニングと効率的な推論を特徴とする強力なエキスパート混合(MoE)言語モデルです。このモデルは、Multi-head Latent Attention(MLA)やDeepSeekMoEなどの革新的なアーキテクチャを採用しています。MLAは、Key-Value(KV)キャッシュを潜在ベクトルに大幅に圧縮することで、効率的な推論を保証します。一方、DeepSeekMoEは、疎な計算を通じて、低コストで強力なモデルのトレーニングを可能にします。

モデルのダウンロード | 評価結果 | モデルアーキテクチャ | APIプラットフォーム | ライセンス | 引用
🚀 クイックスタート
先週、DeepSeek-V2のリリースとその話題性により、MLA(Multi-head Latent Attention)に対する幅広い関心が高まりました!多くのコミュニティメンバーから、詳細な研究のためにより小さなMoEモデルをオープンソース化することが提案されました。そして、今回DeepSeek-V2-Liteが登場します。
- 総パラメータ数は16B、アクティブなパラメータ数は2.4Bで、5.7Tトークンでゼロからトレーニングされています。
- 多くの英語と中国語のベンチマークで、7Bの密なモデルや16BのMoEモデルを上回っています。
- 単一の40G GPUでデプロイ可能で、8x80G GPUで微調整可能です。
✨ 主な機能
DeepSeek-V2は、革新的なアーキテクチャを採用することで、経済的なトレーニングと効率的な推論を保証します。
- アテンションについては、MLA(Multi-head Latent Attention)を設計しています。これは低ランクのキーバリュー結合圧縮を利用して、推論時のキーバリューキャッシュのボトルネックを解消し、効率的な推論をサポートします。
- フィードフォワードネットワーク(FFNs)については、DeepSeekMoEアーキテクチャを採用しています。これは高性能なMoEアーキテクチャで、低コストでより強力なモデルのトレーニングを可能にします。
📦 インストール
モデルのダウンロード
DeepSeek-V2では、2種類のサイズのベースモデルとチャットモデルをオープンソース化しています。
| モデル | 総パラメータ数 | アクティブなパラメータ数 | コンテキスト長 | ダウンロード |
|---|---|---|---|---|
| DeepSeek-V2-Lite | 16B | 2.4B | 32k | ü§ó HuggingFace |
| DeepSeek-V2-Lite-Chat (SFT) | 16B | 2.4B | 32k | ü§ó HuggingFace |
| DeepSeek-V2 | 236B | 21B | 128k | ü§ó HuggingFace |
| DeepSeek-V2-Chat (RL) | 236B | 21B | 128k | ü§ó HuggingFace |
HuggingFaceの制約により、現在オープンソース化されているコードは、Huggingface上でGPUで実行する場合、内部コードベースよりもパフォーマンスが遅くなっています。モデルを効率的に実行するために、専用のvllmソリューションを提供しています。
💻 使用例
ローカルでの実行方法
DeepSeek-V2-LiteをBF16形式で推論するには、40GB*1のGPUが必要です。
HuggingfaceのTransformersを使用した推論
HuggingfaceのTransformersを直接使用してモデルの推論を行うことができます。
テキスト生成
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/DeepSeek-V2-Lite"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
text = "An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
チャット生成
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/DeepSeek-V2-Lite-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
messages = [
{"role": "user", "content": "Write a piece of quicksort code in C++"}
]
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(input_tensor.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
print(result)
完全なチャットテンプレートは、Huggingfaceのモデルリポジトリにあるtokenizer_config.json内にあります。
チャットテンプレートの例は以下の通りです。
<|begin▁of▁sentence|>User: {user_message_1}
Assistant: {assistant_message_1}<|end▁of▁sentence|>User: {user_message_2}
Assistant:
オプションのシステムメッセージを追加することもできます。
<|begin▁of▁sentence|>{system_message}
User: {user_message_1}
Assistant: {assistant_message_1}<|end▁of▁sentence|>User: {user_message_2}
Assistant:
vLLMを使用した推論(推奨)
VLLMを使用してモデルの推論を行うには、このプルリクエストをvLLMのコードベースにマージしてください。https://github.com/vllm-project/vllm/pull/4650
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
max_model_len, tp_size = 8192, 1
model_name = "deepseek-ai/DeepSeek-V2-Lite-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_name)
llm = LLM(model=model_name, tensor_parallel_size=tp_size, max_model_len=max_model_len, trust_remote_code=True, enforce_eager=True)
sampling_params = SamplingParams(temperature=0.3, max_tokens=256, stop_token_ids=[tokenizer.eos_token_id])
messages_list = [
[{"role": "user", "content": "Who are you?"}],
[{"role": "user", "content": "Translate the following content into Chinese directly: DeepSeek-V2 adopts innovative architectures to guarantee economical training and efficient inference."}],
[{"role": "user", "content": "Write a piece of quicksort code in C++."}],
]
prompt_token_ids = [tokenizer.apply_chat_template(messages, add_generation_prompt=True) for messages in messages_list]
outputs = llm.generate(prompt_token_ids=prompt_token_ids, sampling_params=sampling_params)
generated_text = [output.outputs[0].text for output in outputs]
print(generated_text)
LangChainのサポート
APIがOpenAIと互換性があるため、LangChainで簡単に使用することができます。
以下は例です。
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model='deepseek-chat',
openai_api_key=<your-deepseek-api-key>,
openai_api_base='https://api.deepseek.com/v1',
temperature=0.85,
max_tokens=8000)
📚 ドキュメント
評価結果
ベースモデル
標準ベンチマーク
| ベンチマーク | ドメイン | DeepSeek 7B (Dense) | DeepSeekMoE 16B | DeepSeek-V2-Lite (MoE-16B) |
|---|---|---|---|---|
| アーキテクチャ | - | MHA+Dense | MHA+MoE | MLA+MoE |
| MMLU | 英語 | 48.2 | 45.0 | 58.3 |
| BBH | 英語 | 39.5 | 38.9 | 44.1 |
| C-Eval | 中国語 | 45.0 | 40.6 | 60.3 |
| CMMLU | 中国語 | 47.2 | 42.5 | 64.3 |
| HumanEval | コード | 26.2 | 26.8 | 29.9 |
| MBPP | コード | 39.0 | 39.2 | 43.2 |
| GSM8K | 数学 | 17.4 | 18.8 | 41.1 |
| Math | 数学 | 3.3 | 4.3 | 17.1 |
チャットモデル
標準ベンチマーク
| ベンチマーク | ドメイン | DeepSeek 7B Chat (SFT) | DeepSeekMoE 16B Chat (SFT) | DeepSeek-V2-Lite 16B Chat (SFT) |
|---|---|---|---|---|
| MMLU | 英語 | 49.7 | 47.2 | 55.7 |
| BBH | 英語 | 43.1 | 42.2 | 48.1 |
| C-Eval | 中国語 | 44.7 | 40.0 | 60.1 |
| CMMLU | 中国語 | 51.2 | 49.3 | 62.5 |
| HumanEval | コード | 45.1 | 45.7 | 57.3 |
| MBPP | コード | 39.0 | 46.2 | 45.8 |
| GSM8K | 数学 | 62.6 | 62.2 | 72.0 |
| Math | 数学 | 14.7 | 15.2 | 27.9 |
モデルアーキテクチャ
DeepSeek-V2は、革新的なアーキテクチャを採用して、経済的なトレーニングと効率的な推論を保証しています。
- アテンションについては、MLA(Multi-head Latent Attention)を設計しています。これは低ランクのキーバリュー結合圧縮を利用して、推論時のキーバリューキャッシュのボトルネックを解消し、効率的な推論をサポートします。
- フィードフォワードネットワーク(FFNs)については、DeepSeekMoEアーキテクチャを採用しています。これは高性能なMoEアーキテクチャで、低コストでより強力なモデルのトレーニングを可能にします。
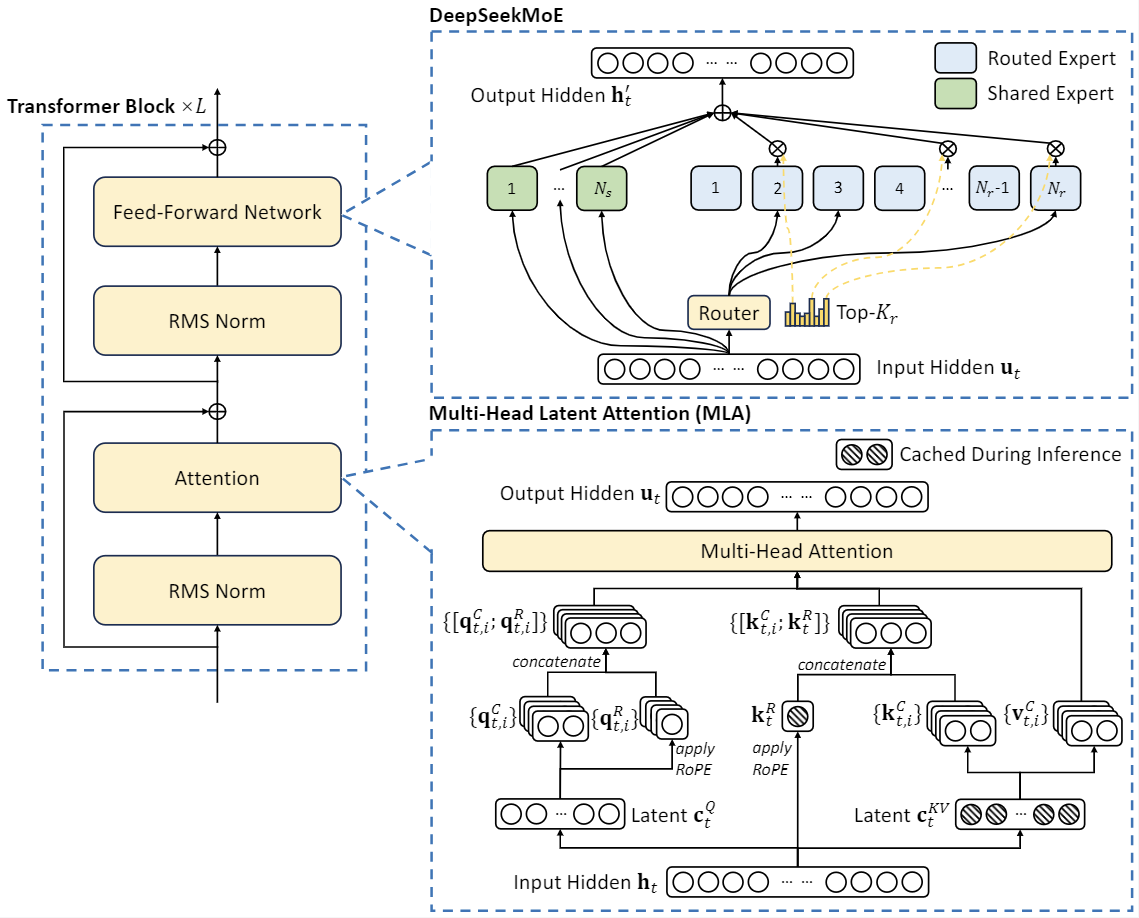
DeepSeek-V2-Liteは27層で、隠れ次元は2048です。また、MLAを採用しており、16個のアテンションヘッドを持ち、各ヘッドの次元は128です。そのKV圧縮次元は512ですが、DeepSeek-V2とは少し異なり、クエリを圧縮しません。分離されたクエリとキーについては、ヘッドごとの次元は64です。DeepSeek-V2-Liteはまた、DeepSeekMoEを採用しており、最初の層を除くすべてのFFNがMoE層に置き換えられています。各MoE層は2つの共有エキスパートと64個のルーティングエキスパートで構成されており、各エキスパートの中間隠れ次元は1408です。ルーティングエキスパートのうち、各トークンに対して6つのエキスパートがアクティブになります。この設定で、DeepSeek-V2-Liteは総計15.7Bのパラメータを持ち、そのうち2.4Bが各トークンに対してアクティブになります。
トレーニングの詳細
DeepSeek-V2-Liteは、DeepSeek-V2と同じ事前学習コーパスでゼロからトレーニングされており、SFTデータによる汚染はありません。AdamWオプティマイザを使用し、ハイパーパラメータは$\beta_1 = 0.9$、$\beta_2 = 0.95$、$\mathrm{weight_decay} = 0.1$に設定されています。学習率は、ウォームアップとステップディケイ戦略を使用してスケジューリングされます。最初に、学習率は最初の2Kステップで0から最大値まで線形に増加します。その後、約80%のトークンをトレーニングした後に学習率に0.316を掛け、約90%のトークンをトレーニングした後に再度0.316を掛けます。最大学習率は$4.2 \times 10^{-4}$に設定され、勾配クリッピングノルムは1.0に設定されています。バッチサイズスケジューリング戦略は使用せず、一定のバッチサイズ4608シーケンスでトレーニングされます。事前学習中は、最大シーケンス長を4Kに設定し、5.7TトークンでDeepSeek-V2-Liteをトレーニングします。パイプライン並列化を利用して、異なる層を異なるデバイスにデプロイしますが、各層については、すべてのエキスパートが同じデバイスにデプロイされます。したがって、$\alpha_{1}=0.001$の小さなエキスパートレベルのバランス損失のみを使用し、デバイスレベルのバランス損失や通信バランス損失は使用しません。事前学習後、長文脈拡張とSFTを行い、DeepSeek-V2-Lite Chatというチャットモデルを得ます。
📄 ライセンス
コードのライセンスについてはCode Licenseを、モデルのライセンスについてはModel Licenseをご確認ください。