🚀 GLM-4-Z1-32B-0414
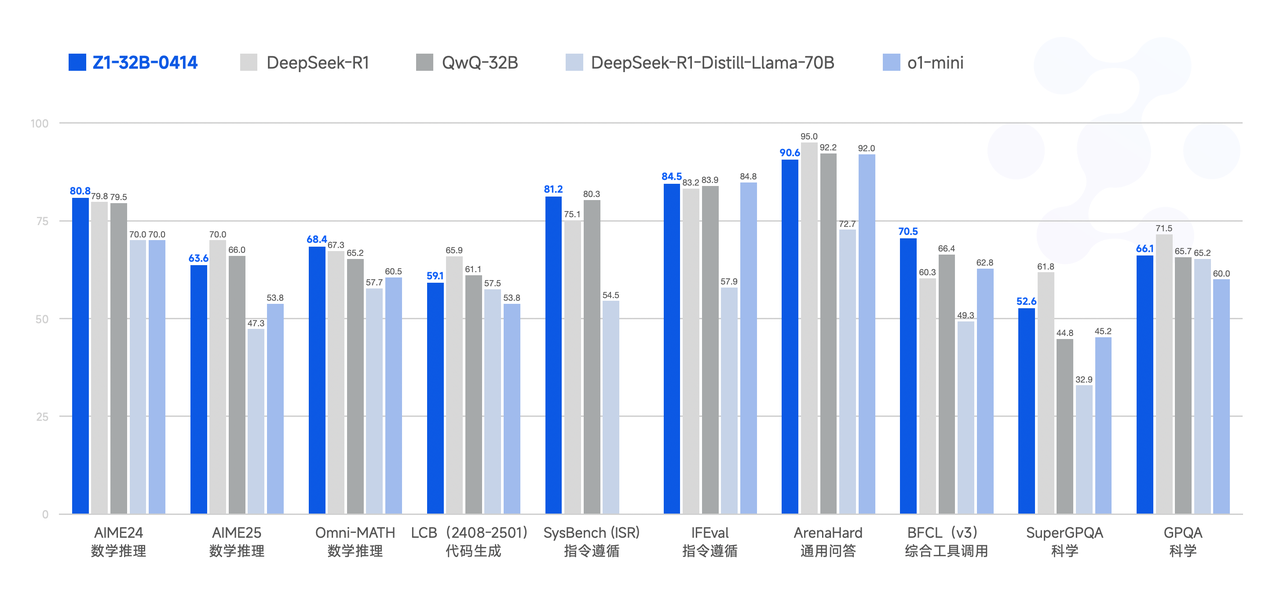
GLMシリーズに新たなオープンソースモデル、GLM-4-32B-0414シリーズが登場しました。このモデルは320億のパラメータを持ち、OpenAIのGPTシリーズやDeepSeekのV3/R1シリーズと匹敵する性能を誇り、非常に使いやすいローカルデプロイ機能をサポートしています。GLM-4-32B-Base-0414は15Tの高品質データ、大量の推論タイプの合成データを含むデータで事前学習され、その後の強化学習拡張の基礎を築いています。事後学習段階では、対話シナリオの人間の嗜好アライメントに加え、棄却サンプリングや強化学習などの技術を用いて、命令追従、エンジニアリングコード、関数呼び出しなどのモデルの性能を強化し、エージェントタスクに必要な原子的な能力を強化しています。GLM-4-32B-0414は、エンジニアリングコード、アーティファクト生成、関数呼び出し、検索ベースの質問応答、レポート生成などの分野で良好な結果を達成しています。一部のベンチマークでは、GPT-4oやDeepSeek-V3-0324(671B)などの大規模モデルに匹敵する性能を発揮します。
GLM-Z1-32B-0414は、深い思考能力を持つ推論モデルです。これはGLM-4-32B-0414をベースに、コールドスタートと拡張強化学習を行い、数学、コード、論理に関するタスクでモデルをさらに学習させることで開発されました。ベースモデルと比較して、GLM-Z1-32B-0414は数学的能力と複雑なタスクを解決する能力を大幅に向上させています。学習過程では、ペアワイズランキングフィードバックに基づく一般的な強化学習も導入し、モデルの一般的な能力をさらに強化しています。
GLM-Z1-Rumination-32B-0414は、熟考能力を持つ深層推論モデルです(OpenAIのDeep Researchをベンチマークとしています)。典型的な深層思考モデルとは異なり、熟考モデルはより長い時間をかけて深い思考を行い、よりオープンエンドで複雑な問題(例えば、2つの都市のAI開発の比較分析とその将来の開発計画の作成)を解決します。熟考モデルは深い思考過程で検索ツールを統合して複雑なタスクを処理し、複数のルールベースの報酬を利用してエンドツーエンドの強化学習を誘導および拡張することで学習されます。Z1-Ruminationは、調査スタイルの執筆や複雑な検索タスクで大幅な改善を示しています。
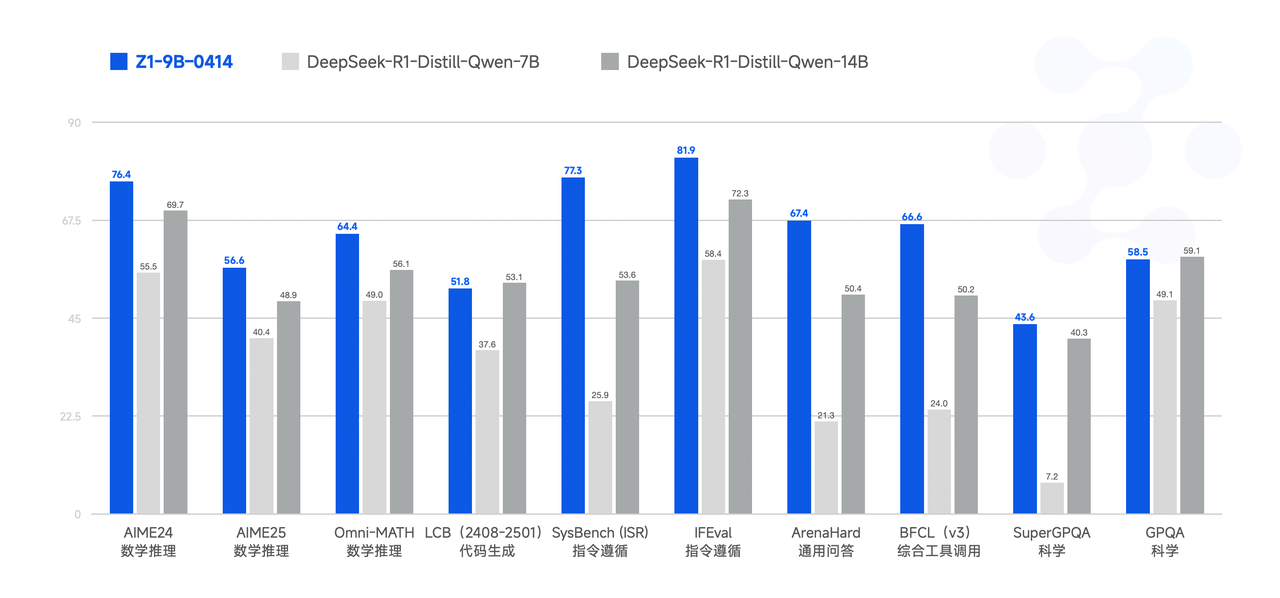
最後に、GLM-Z1-9B-0414は驚きのモデルです。前述の一連の技術を用いて9Bの小型モデルを学習させ、オープンソースの伝統を維持しています。規模が小さいにもかかわらず、GLM-Z1-9B-0414は数学的推論や一般的なタスクでも優れた能力を発揮します。その全体的な性能は、同規模のオープンソースモデルの中ですでにトップレベルにあります。特にリソースが制限されたシナリオでは、このモデルは効率と効果の間で優れたバランスを達成し、軽量なデプロイを求めるユーザーに強力なオプションを提供します。
✨ 主な機能
性能
モデルの使用ガイドライン
サンプリングパラメータ
| パラメータ |
推奨値 |
説明 |
| temperature |
0.6 |
創造性と安定性のバランスを取ります |
| top_p |
0.95 |
サンプリングの累積確率閾値 |
| top_k |
40 |
希少なトークンを除外しながら多様性を維持します |
| max_new_tokens |
30000 |
思考に十分なトークンを残します |
強制思考
- 最初の行に
<think>\n を追加します。これにより、モデルが応答する前に思考することが保証されます。
chat_template.jinja を使用する場合、この動作を強制するためのプロンプトが自動的に注入されます。
対話履歴のトリミング
- ユーザーに表示される最後の返信のみを保持します。
隠された思考内容は履歴に保存しないでください。これにより干渉が減少します。これは
chat_template.jinja ですでに実装されています。
長文脈の処理(YaRN)
- 入力長が 8,192トークン を超える場合、YaRN(Rope Scaling)を有効にすることを検討してください。
- サポートされているフレームワークでは、
config.json に以下のスニペットを追加します。
"rope_scaling": {
"type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 32768
}
- Static YaRN はすべてのテキストに一律に適用されます。短いテキストでは性能がわずかに低下する可能性があるため、必要に応じて有効にしてください。
💻 使用例
基本的な使用法
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "THUDM/GLM-4-Z1-32B-0414"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForCausalLM.from_pretrained(MODEL_PATH, device_map="auto")
message = [{"role": "user", "content": "Let a, b be positive real numbers such that ab = a + b + 3. Determine the range of possible values for a + b."}]
inputs = tokenizer.apply_chat_template(
message,
return_tensors="pt",
add_generation_prompt=True,
return_dict=True,
).to(model.device)
generate_kwargs = {
"input_ids": inputs["input_ids"],
"attention_mask": inputs["attention_mask"],
"max_new_tokens": 4096,
"do_sample": False,
}
out = model.generate(**generate_kwargs)
print(tokenizer.decode(out[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True))
📚 ドキュメント
引用
もし私たちの研究が役に立った場合は、以下の論文を引用していただけると幸いです。
@misc{glm2024chatglm,
title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools},
author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang},
year={2024},
eprint={2406.12793},
archivePrefix={arXiv},
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
}
📄 ライセンス
このプロジェクトはMITライセンスの下で公開されています。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応