🚀 StarCoder2-Instruct: コード生成のための完全透明かつ許容的な自己アライメント
完全に許容的で透明なパイプラインでトレーニングされた、最初の完全に自己アライメントされたコード生成用大規模言語モデルです。
🚀 クイックスタート
このモデルは、コード生成に特化した大規模言語モデルです。完全に自己アライメントされ、透明なパイプラインでトレーニングされています。以下に、モデルの基本情報を示します。
| 属性 |
详情 |
| パイプラインタグ |
テキスト生成 |
| ベースモデル |
bigcode/starcoder2-15b |
| データセット |
bigcode/self-oss-instruct-sc2-exec-filter-50k |
| ライセンス |
bigcode-openrail-m |
| ライブラリ名 |
transformers |
| タグ |
コード |
モデルの概要
StarCoder2-15B-Instruct-v0.1は、完全に自己アライメントされたコード生成用大規模言語モデルです。このオープンソースのパイプラインは、StarCoder2-15Bを使用して数千の命令応答ペアを生成し、それを使用してStarCoder-15B自体を微調整します。この過程では、人間によるアノテーションや、巨大で独自の大規模言語モデルからの蒸留データは使用されていません。

引用
@article{wei2024selfcodealign,
title={SelfCodeAlign: Self-Alignment for Code Generation},
author={Yuxiang Wei and Federico Cassano and Jiawei Liu and Yifeng Ding and Naman Jain and Zachary Mueller and Harm de Vries and Leandro von Werra and Arjun Guha and Lingming Zhang},
year={2024},
journal={arXiv preprint arXiv:2410.24198}
}
💻 使用例
基本的な使用法
このモデルは、コーディング関連の命令に対して単一ターンで応答するように設計されています。他のスタイルの命令では、応答の精度が低下する可能性があります。
以下は、transformersライブラリを使用してモデルを使用する例です。
import transformers
import torch
pipeline = transformers.pipeline(
model="bigcode/starcoder2-15b-instruct-v0.1",
task="text-generation",
torch_dtype=torch.bfloat16,
device_map="auto",
)
def respond(instruction: str, response_prefix: str) -> str:
messages = [{"role": "user", "content": instruction}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False)
prompt += response_prefix
teminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("###"),
]
result = pipeline(
prompt,
max_length=256,
num_return_sequences=1,
do_sample=False,
eos_token_id=teminators,
pad_token_id=pipeline.tokenizer.eos_token_id,
truncation=True,
)
response = response_prefix + result[0]["generated_text"][len(prompt) :].split("###")[0].rstrip()
return response
instruction = "Write a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria."
response_prefix = ""
print(respond(instruction, response_prefix))
以下は、期待される出力です。
Here's how you can implement a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria:
```python
from typing import TypeVar, Callable
T = TypeVar('T')
def quicksort(items: list[T], less_than: Callable[[T, T], bool] = lambda x, y: x < y) -> list[T]:
if len(items) <= 1:
return items
pivot = items[0]
less = [x for x in items[1:] if less_than(x, pivot)]
greater = [x for x in items[1:] if not less_than(x, pivot)]
return quicksort(less, less_than) + [pivot] + quicksort(greater, less_than)
```
バイアス、リスク、および制限
StarCoder2-15B-Instruct-v0.1は、主に実行を通じて検証できるPythonコード生成タスクに対して微調整されています。このため、特定のバイアスや制限が生じる可能性があります。たとえば、モデルは出力形式を指定する命令に厳密に従わない場合があります。このような場合、応答プレフィックスまたはワンショット例を提供すると、モデルの出力を誘導するのに役立ちます。また、モデルは他のプログラミング言語やドメイン外のコーディングタスクに対して制限がある可能性があります。
このモデルは、ベースのStarCoder2-15Bモデルからバイアス、リスク、および制限を引き継いでいます。詳細については、StarCoder2-15Bモデルカードを参照してください。
評価
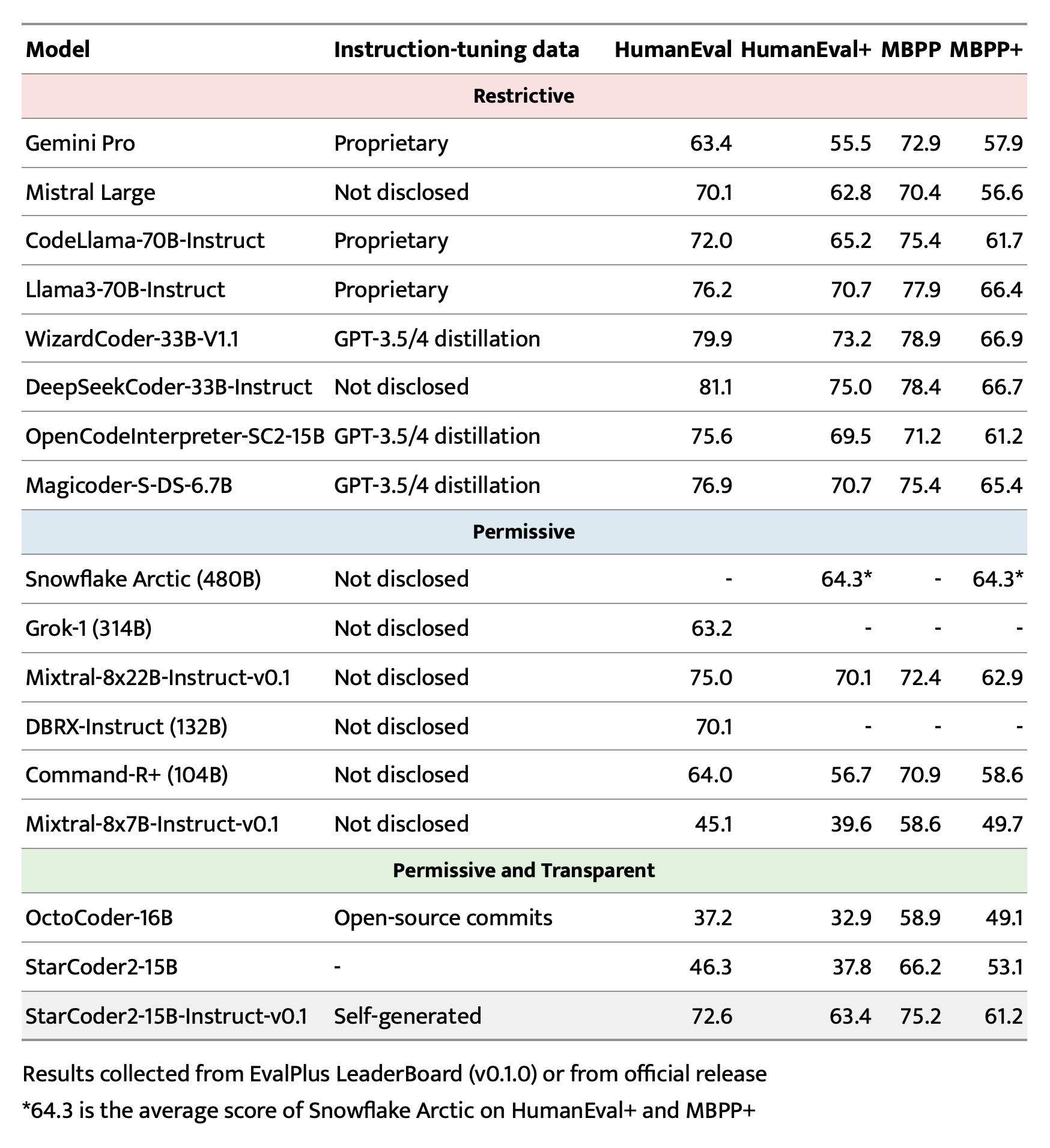
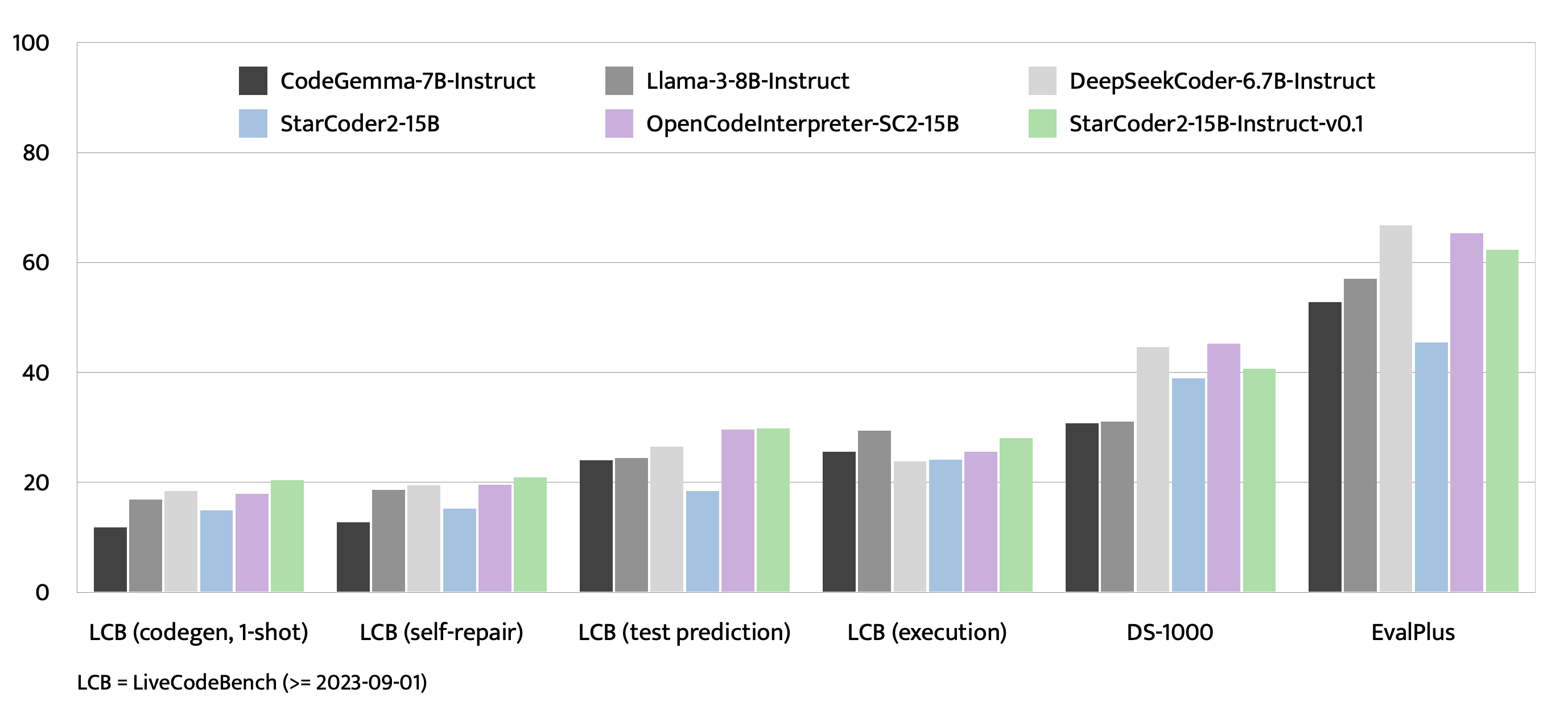
🔧 技術詳細
ハイパーパラメータ
- オプティマイザ: Adafactor
- 学習率: 1e-5
- エポック数: 4
- バッチサイズ: 64
- ウォームアップ率: 0.05
- スケジューラ: Linear
- シーケンス長: 1280
- ドロップアウト: 適用なし
ハードウェア
1 x NVIDIA A100 80GB
リソース
完全なデータパイプライン
データセット生成パイプラインにはいくつかのステップがあります。パイプラインの各ステップに対して中間データセットを提供しています。
- The Stack v1からフィルタリングされた元のシードデータセット: https://huggingface.co/datasets/bigcode/python-stack-v1-functions-filtered
- StarCoder2-15Bを判定器として使用して、不適切なドキュメント文字列を持つアイテムを削除したシードデータセット: https://huggingface.co/datasets/bigcode/python-stack-v1-functions-filtered-sc2
- シード -> 概念: https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-concepts
- 概念 -> 命令: https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-instructions
- 命令 -> 応答: https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-responses-unfiltered
- 実行によってフィルタリングされた応答: https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-500k-raw
- 重複排除によってフィルタリングされた実行済み応答 (最終データセット): https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応