🚀 Poseless-3B
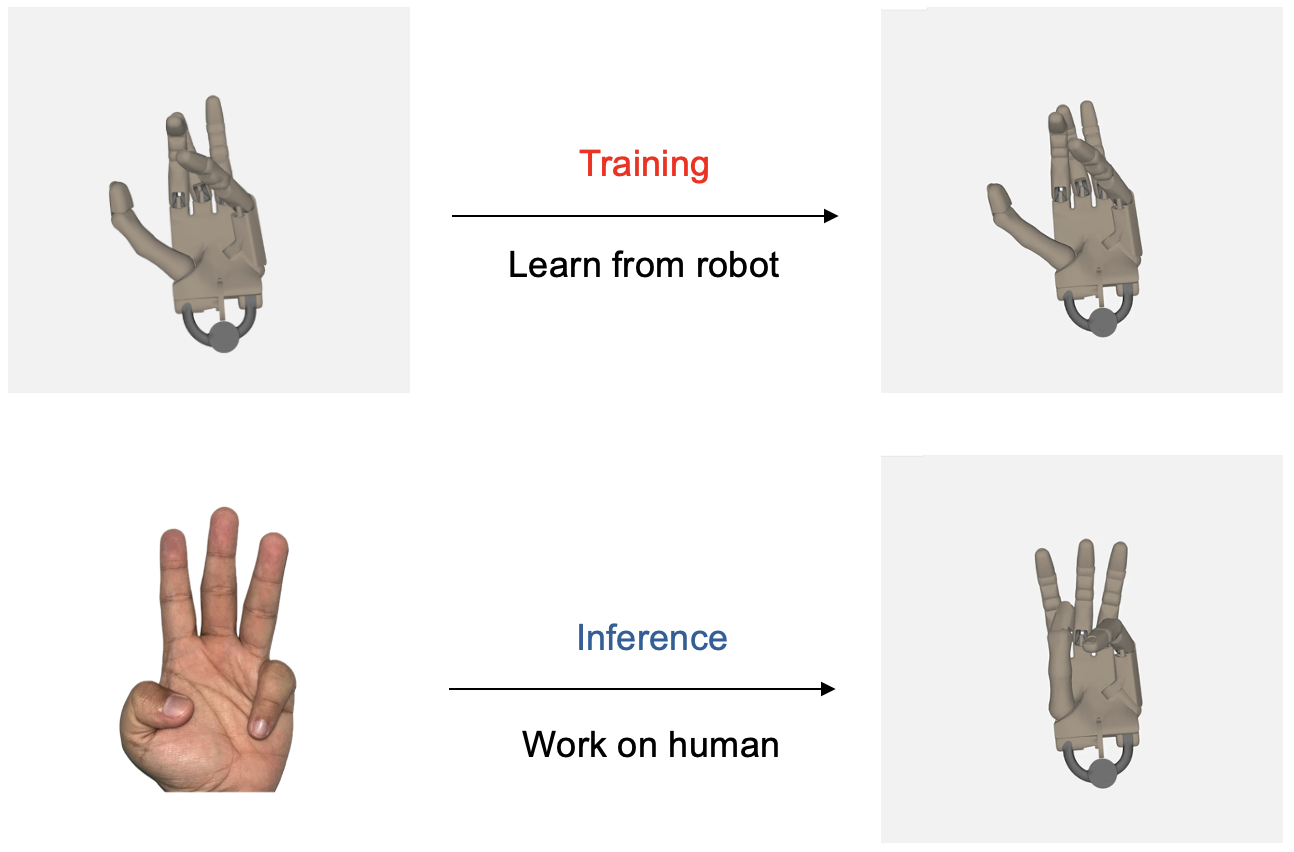
このプロジェクトは、ロボットハンド制御のための新しいフレームワークを提供します。画像を直接関節角度にマッピングすることで、明示的なポーズ推定を不要にし、実世界のシナリオへのゼロショット汎化や、ロボットハンドから人間の手へのクロスモルフォロジー転送を可能にします。
🚀 クイックスタート
以下のコードを使用して、モデルを使って手の関節角度を推定できます。
基本的な使用法
import torch
from PIL import Image
from transformers import AutoProcessor, Qwen2_5_VLForConditionalGeneration
from qwen_vl_utils import process_vision_info
device = "cuda" if torch.cuda.is_available() else "cpu"
model_path = "homebrewltd/Poseless-3B"
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
model_path,
trust_remote_code=True,
torch_dtype=torch.bfloat16
).eval().to(device)
processor = AutoProcessor.from_pretrained(
model_path,
min_pixels=256*28*28,
max_pixels=1280*28*28,
trust_remote_code=True
)
image = Image.open("your_hand_image.png").convert("RGB")
SYSTEM_PROMPT = """You are a specialized Vision Language Model designed to accurately estimate joint angles from hand pose images. Your task is to analyze images of a human or robotic hand and output precise angle measurements for each joint. Output joint angles in radians.
Output Format:
<lh_WRJ2>angle</lh_WRJ2><lh_WRJ1>angle</lh_WRJ1><lh_FFJ4>angle</lh_FFJ4><lh_FFJ3>angle</lh_FFJ3><lh_FFJ2>angle</lh_FFJ2><lh_FFJ1>angle</lh_FFJ1><lh_MFJ4>angle</lh_MFJ4><lh_MFJ3>angle</lh_MFJ3><lh_MFJ2>angle</lh_MFJ2><lh_MFJ1>angle</lh_MFJ1><lh_RFJ4>angle</lh_RFJ4><lh_RFJ3>angle</lh_RFJ3><lh_RFJ2>angle</lh_RFJ2><lh_RFJ1>angle</lh_RFJ1><lh_LFJ5>angle</lh_LFJ5><lh_LFJ4>angle</lh_LFJ4><lh_LFJ3>angle</lh_LFJ3><lh_LFJ2>angle</lh_LFJ2><lh_LFJ1>angle</lh_LFJ1><lh_THJ5>angle</lh_THJ5><lh_THJ4>angle</lh_THJ4><lh_THJ3>angle</lh_THJ3><lh_THJ2>angle</lh_THJ2><lh_THJ1>angle</lh_THJ1>
"""
messages = [
{"role": "system", "content": f"{SYSTEM_PROMPT}"},
{
"role": "user",
"content": [
{
"type": "image",
"image": image,
"min_pixels": 1003520,
"max_pixels": 1003520,
},
{"type": "text", "text": "<Pose>"},
],
},
]
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(text=[text], images=image_inputs, videos=video_inputs, padding=True, return_tensors="pt").to(device)
generated_ids = model.generate(**inputs, max_new_tokens=1024)
generated_ids_trimmed = [out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]
output_text = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
print(output_text)
出力は、ラジアンで表された関節角度のXML形式になります。
<lh_WRJ2>angle</lh_WRJ2><lh_WRJ1>angle</lh_WRJ1><lh_FFJ4>angle</lh_FFJ4>...
✨ 主な機能
- 新しいフレームワークの導入:VLM(例:Qwen 2.5 3B Instruct)を利用して、単眼画像を直接ロボットの関節角度にマッピングする新しいフレームワークを導入しました。これにより、ポーズ推定を完全に回避し、ロバストでモルフォロジーに依存しない特徴抽出が可能になります。
- 合成データパイプライン:関節角度をランダム化し、視覚的特徴(例:照明、テクスチャ)をドメインランダム化することで、無限のトレーニング例を生成する合成データパイプラインを導入しました。これにより、高価なラベル付きデータセットへの依存を排除し、実世界の変動に対するロバスト性を確保します。
- クロスモルフォロジー汎化:モデルがクロスモルフォロジー汎化を行うことを実証し、ロボットハンドのデータのみでトレーニングされたにもかかわらず、人間の手の動きを模倣する能力を示しました。
- 深度フリー制御:深度フリー制御が可能であることを実証し、ロボット工学の研究で頻繁に使用される深度推定機能を持たないカメラでの後続の採用に道を開きます。
📦 インストール
このライブラリは transformers を使用しています。必要な依存関係をインストールするには、以下のコマンドを実行してください。
pip install transformers
📚 ドキュメント
モデル詳細
📄 ライセンス
このプロジェクトはApache-2.0ライセンスの下で公開されています。
🔖 引用
📞 詳細情報
詳細については、著者に alan@menlo.ai, bach@menlo.ai, charles@menlo.ai, yuuki@menlo.ai まで連絡してください。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 複数言語対応
Transformers 複数言語対応