%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
モデル概要
モデル特徴
モデル能力
使用事例
🚀 Flan-UL2モデルカード
Flan-UL2は、T5アーキテクチャに基づくエンコーダ・デコーダモデルです。このモデルは、昨年早くにリリースされたUL2モデルと同じ設定を使用しており、"Flan"プロンプトチューニングとデータセットコレクションを用いてファインチューニングされています。
🚀 クイックスタート
モデルの使用方法
T5xからHugging Faceへの変換
convert_t5x_checkpoint_to_pytorch.py スクリプトを使用し、strict = False 引数を渡すことができます。元の辞書には最終レイヤーのノルムが欠けているため、この引数を渡します。
python convert_t5x_checkpoint_to_pytorch.py --t5x_checkpoint_path PATH_TO_T5X_CHECKPOINTS --config_file PATH_TO_CONFIG --pytorch_dump_path PATH_TO_SAVE
ここでは、google/ul2 と同じ設定ファイルを使用します。
モデルの実行
メモリ使用を効率化するために、GPU環境下では load_in_8bit フラグを使用してモデルを 8bit でロードすることをおすすめします。
# pip install accelerate transformers bitsandbytes
from transformers import T5ForConditionalGeneration, AutoTokenizer
import torch
model = T5ForConditionalGeneration.from_pretrained("google/flan-ul2", device_map="auto", load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained("google/flan-ul2")
input_string = "Answer the following question by reasoning step by step. The cafeteria had 23 apples. If they used 20 for lunch, and bought 6 more, how many apple do they have?"
inputs = tokenizer(input_string, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(inputs, max_length=200)
print(tokenizer.decode(outputs[0]))
# <pad> They have 23 - 20 = 3 apples left. They have 3 + 6 = 9 apples. Therefore, the answer is 9.</s>
または、モデルを bfloat16 でロードして実行することもできます。
# pip install accelerate transformers
from transformers import T5ForConditionalGeneration, AutoTokenizer
import torch
model = T5ForConditionalGeneration.from_pretrained("google/flan-ul2", torch_dtype=torch.bfloat16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("google/flan-ul2")
input_string = "Answer the following question by reasoning step by step. The cafeteria had 23 apples. If they used 20 for lunch, and bought 6 more, how many apple do they have?"
inputs = tokenizer(input_string, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(inputs, max_length=200)
print(tokenizer.decode(outputs[0]))
# <pad> They have 23 - 20 = 3 apples left. They have 3 + 6 = 9 apples. Therefore, the answer is 9.</s>
✨ 主な機能
性能の改善
報告された結果は以下の通りです。
| MMLU | BBH | MMLU-CoT | BBH-CoT | 平均 | |
|---|---|---|---|---|---|
| FLAN-PaLM 62B | 59.6 | 47.5 | 56.9 | 44.9 | 49.9 |
| FLAN-PaLM 540B | 73.5 | 57.9 | 70.9 | 66.3 | 67.2 |
| FLAN-T5-XXL 11B | 55.1 | 45.3 | 48.6 | 41.4 | 47.6 |
| FLAN-UL2 20B | 55.7(+1.1%) | 45.9(+1.3%) | 52.2(+7.4%) | 42.7(+3.1%) | 49.1(+3.2%) |
📚 ドキュメント
UL2の紹介
このセクション全体は、google/ul2 のモデルカードからコピーされたものであり、flan-ul2 に関しては変更される可能性があります。
UL2は、データセットや設定に関係なく普遍的に有効なモデルを事前学習するための統一フレームワークです。UL2は、多様な事前学習パラダイムを組み合わせた事前学習目的であるMixture-of-Denoisers (MoD) を使用しています。また、UL2はモード切り替えの概念を導入しており、下流のファインチューニングは特定の事前学習スキームに関連付けられています。

概要 既存の事前学習モデルは、一般的に特定のクラスの問題に向けられています。これまで、適切なアーキテクチャと事前学習設定についてはまだコンセンサスが得られていないようです。この論文では、データセットや設定に関係なく普遍的に有効なモデルを事前学習するための統一フレームワークを提案しています。まず、一般的に混同される2つの概念であるアーキテクチャの原型と事前学習目的を切り離します。次に、NLPにおける自己教師付き学習の一般化された統一的な視点を提示し、異なる事前学習目的がどのように相互に変換できるか、および異なる目的間の補間がどのように有効であるかを示します。そして、多様な事前学習パラダイムを組み合わせた事前学習目的であるMixture-of-Denoisers (MoD) を提案します。さらに、モード切り替えの概念を導入し、下流のファインチューニングを特定の事前学習スキームに関連付けます。多数のアブレーション実験を行い、複数の事前学習目的を比較し、我々の方法が多様な設定でT5やGPTのようなモデルを上回り、パレートフロンティアを押し上げることを見出しました。最後に、モデルを200億パラメータまでスケーリングすることで、言語生成(自動評価と人間評価)、言語理解、テキスト分類、質問応答、常識推論、長文推論、構造化知識の基礎付け、情報検索など、50の確立された教師付きNLPタスクでSOTAの性能を達成しました。また、コンテキスト内学習でも強力な結果を達成し、ゼロショットSuperGLUEで1750億パラメータのGPT-3を上回り、ワンショット要約でT5-XXLの性能を3倍にしました。
詳細については、元の論文を参照してください。 論文: Unifying Language Learning Paradigms 著者: Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
学習
Flan UL2
Flan-UL2モデルは、UL2 のチェックポイントを使用して初期化され、その後Flanプロンプトを使用して追加学習されました。これは、元の学習コーパスが C4 であることを意味します。
「Scaling Instruction-Finetuned language models (Chung et al.)」(Flan2論文とも呼ばれる)では、大規模言語モデルをデータセットのコレクションで学習させるというアイデアが提案されています。これらのデータセットは、多様なタスクに対する汎化能力を可能にする命令として表現されています。Flanは主に学術的なタスクで学習されています。Flan2では、2億から110億パラメータの一連のT5モデルをFlanで命令チューニングしてリリースしました。
Flanデータセットは、「The Flan Collection: Designing Data and Methods for Effective Instruction Tuning」(Longpre et al.) でオープンソース化されています。Google AIブログ記事「The Flan Collection: Advancing Open Source Methods for Instruction Tuning」も参照してください。
UL2の事前学習
このモデルは、C4コーパスで事前学習されています。事前学習では、バッチサイズ1024でC4上の合計1兆トークン(200万ステップ)で学習されました。入力とターゲットのシーケンス長は512/512に設定されています。事前学習中のドロップアウトは0に設定されています。事前学習には、約1兆トークンに対して1か月強かかりました。このモデルは、32のエンコーダレイヤーと32のデコーダレイヤーを持ち、dmodel は4096、df は16384です。各ヘッドの次元は256で、合計16ヘッドです。モデルはモデル並列化を8で使用しています。T5と同じ語彙サイズ32000のSentencePieceトークナイザーが使用されています(T5トークナイザーの詳細についてはこちらをクリック)。
UL-20Bは、T5に非常に似たモデルとして解釈できますが、異なる目的とわずかに異なるスケーリングノブで学習されています。UL-20Bは、Jax と T5X インフラストラクチャを使用して学習されました。
事前学習中の学習目的は、以下で説明するさまざまなデノイズ戦略の混合です。
デノイザーの混合
論文から引用すると、
我々は、強力な普遍的モデルは、事前学習中に多様な問題を解くことにさらされる必要があると推測しています。事前学習は自己教師付き学習を使用して行われるため、このような多様性はモデルの目的に注入されるべきであり、そうでなければモデルは、長い一貫したテキスト生成のような特定の能力を欠く可能性があります。 これに触発され、現在のクラスの目的関数を考慮して、事前学習中に使用される3つの主要なパラダイムを定義します。
- R-Denoiser:通常のデノイジングは、T5 で導入された標準的なスパン破損で、2から5トークンの範囲をスパン長として使用し、入力トークンの約15%をマスクします。これらのスパンは短く、知識を獲得するのに役立つ可能性がありますが、流暢なテキストを生成することを学習するには不十分です。
- S-Denoiser:入力からターゲットへのタスクを構築する際に厳密な順序を守る特定のデノイジングのケースです。つまり、プレフィックス言語モデリングです。これを行うために、入力シーケンスをコンテキストとターゲットの2つのサブシーケンスに分割し、ターゲットが未来の情報に依存しないようにします。これは、コンテキストトークンよりも早い位置にターゲットトークンがある可能性のある標準的なスパン破損とは異なります。非常に短いメモリまたはメモリがないS-Denoisingは、標準的な因果言語モデリングと同じ精神です。
- X-Denoiser:モデルが入力の大部分を回復する必要がある極端なデノイジングのバージョンです。これは、比較的限られた情報のメモリから長いターゲットを生成する必要がある状況をシミュレートします。これを行うために、入力シーケンスの約50%がマスクされる積極的なデノイジングの例を含めるようにします。これは、スパン長と/または破損率を増やすことによって行われます。我々は、長いスパン(例えば、≥12トークン)または大きな破損率(例えば、≥30%)を持つ事前学習タスクを極端なものと見なします。X-デノイジングは、通常のスパン破損と言語モデルのような目的の間の補間として動機付けられています。
視覚的な説明については、次の図を参照してください。
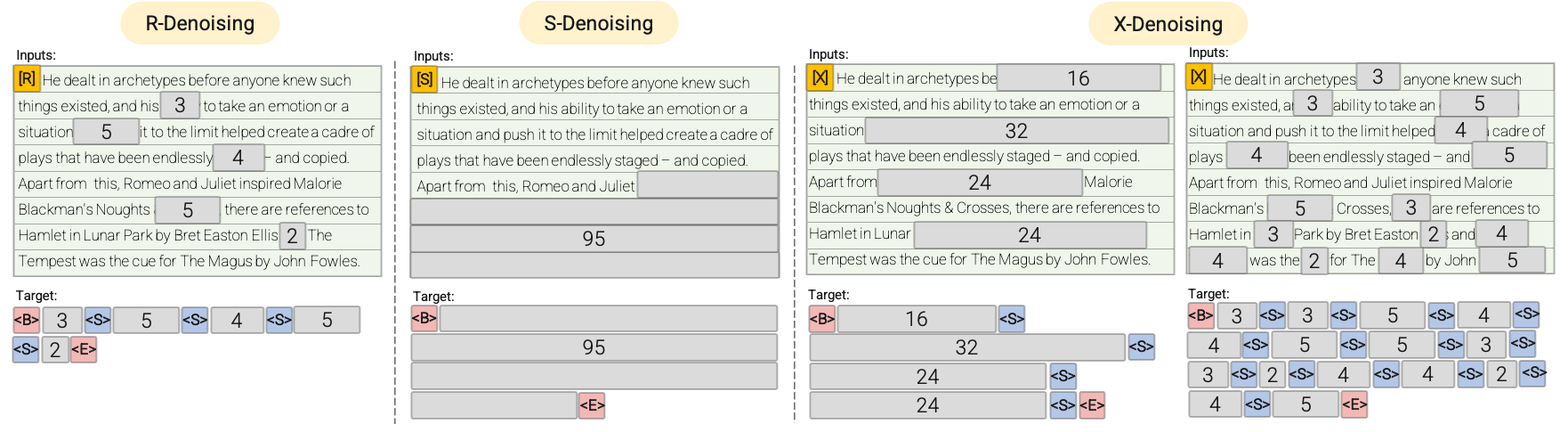
重要:詳細については、論文 のセクション3.1.2を参照してください。
ファインチューニング
このモデルは、通常5万から10万の事前学習ステップ後に継続的にファインチューニングされます。つまり、事前学習の各Nkステップ後に、モデルは各下流タスクでファインチューニングされます。ファインチューニングに使用されたすべてのデータセットの概要については、論文 のセクション5.2.2を参照してください。
モデルが継続的にファインチューニングされるため、計算量を節約するために、タスクが最先端の性能に達したらファインチューニングは停止されます。合計で、このモデルは265万ステップで学習されました。
重要:詳細については、論文 のセクション5.2.1と5.2.2を参照してください。
🔧 技術詳細
言語サポート
- en
- fr
- ro
- de
- 多言語
ウィジェットの使用例
| ウィジェットの説明 | 具体的なテキスト例 |
|---|---|
| 翻訳 | 'Translate to German: My name is Arthur' |
| 質問応答 | 'Please answer to the following question. Who is going to be the next Ballon d'or?' |
| 論理推論 | 'Q: Can Geoffrey Hinton have a conversation with George Washington? Give the rationale before answering.' |
| 科学知識 | 'Please answer the following question. What is the boiling point of Nitrogen?' |
| はい/いいえの質問 | 'Answer the following yes/no question. Can you write a whole Haiku in a single tweet?' |
| 推論タスク | 'Answer the following yes/no question by reasoning step-by-step. Can you write a whole Haiku in a single tweet?' |
| ブール式 | 'Q: ( False or not False or False ) is? A: Let's think step by step' |
| 数学的推論 | 'The square root of x is the cube root of y. What is y to the power of 2, if x = 4?' |
| 前提と仮説 | 'Premise: At my age you will probably have learnt one lesson. Hypothesis: It's not certain how many lessons you'll learn by your thirties. Does the premise entail the hypothesis?' |
| 思考の連鎖 | 'Answer the following question by reasoning step by step. The cafeteria had 23 apples. If they used 20 for lunch, and bought 6 more, how many apple do they have?' |
タグ
- text2text-generation
- flan-ul2
データセット
- svakulenk0/qrecc
- taskmaster2
- djaym7/wiki_dialog
- deepmind/code_contests
- lambada
- gsm8k
- aqua_rat
- esnli
- quasc
- qed
- c4
📄 ライセンス
このモデルは、apache-2.0ライセンスの下で提供されています。
🔗 関連情報
貢献者
このモデルは、Yi Tay によって最初に貢献され、Younes Belkada と Arthur Zucker によってHugging Faceエコシステムに追加されました。
引用
このワークを引用する場合は、Flan-UL2 のリリースを発表したブログ記事 を引用してください。