🚀 RT-DETRのモデルカード
RT-DETRは、リアルタイム物体検出のための最先端のエンドツーエンド物体検出器です。このモデルは、速度と精度のバランスを最適化し、NMSの問題を解決することで、既存の手法を上回る性能を発揮します。
🚀 クイックスタート
以下のコードを使用して、モデルを始めることができます。
import torch
import requests
from PIL import Image
from transformers import RTDetrForObjectDetection, RTDetrImageProcessor
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
image_processor = RTDetrImageProcessor.from_pretrained("PekingU/rtdetr_r50vd_coco_o365")
model = RTDetrForObjectDetection.from_pretrained("PekingU/rtdetr_r50vd_coco_o365")
inputs = image_processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
results = image_processor.post_process_object_detection(outputs, target_sizes=torch.tensor([image.size[::-1]]), threshold=0.3)
for result in results:
for score, label_id, box in zip(result["scores"], result["labels"], result["boxes"]):
score, label = score.item(), label_id.item()
box = [round(i, 2) for i in box.tolist()]
print(f"{model.config.id2label[label]}: {score:.2f} {box}")
これにより、以下のような出力が得られます。
sofa: 0.97 [0.14, 0.38, 640.13, 476.21]
cat: 0.96 [343.38, 24.28, 640.14, 371.5]
cat: 0.96 [13.23, 54.18, 318.98, 472.22]
remote: 0.95 [40.11, 73.44, 175.96, 118.48]
remote: 0.92 [333.73, 76.58, 369.97, 186.99]
✨ 主な機能
- YOLOシリーズの速度と精度の問題を解決するために、NMSを排除したエンドツーエンド物体検出器を提案します。
- 効率的なハイブリッドエンコーダを設計して、マルチスケール特徴を高速に処理し、速度を向上させます。
- 不確定性最小化クエリ選択を提案して、高品質の初期クエリをデコーダに提供し、精度を向上させます。
- デコーダ層の数を調整することで、柔軟に速度を調整でき、再トレーニングなしで様々なシナリオに適応します。
📦 インストール
このモデルはtransformersライブラリを使用しています。以下のコマンドでインストールできます。
pip install transformers
📚 ドキュメント
モデル詳細

YOLOシリーズは、速度と精度の合理的なトレードオフにより、リアルタイム物体検出の最も人気のあるフレームワークになりました。しかし、YOLOの速度と精度はNMSによって悪影響を受けることがわかりました。最近、エンドツーエンドのTransformerベースの検出器(DETR)が、NMSを排除する代替手段を提供しています。しかし、高い計算コストが実用性を制限し、NMSを排除する利点を十分に活用することができません。この論文では、Real-Time DEtection TRansformer(RT-DETR)を提案します。これは、私たちの知る限りでは、上記のジレンマを解決する最初のリアルタイムエンドツーエンド物体検出器です。RT-DETRは、高度なDETRを参考に2段階で構築されています。まず、精度を維持しながら速度を向上させ、次に速度を維持しながら精度を向上させます。具体的には、スケール内相互作用とクロススケール融合を分離することで、マルチスケール特徴を迅速に処理する効率的なハイブリッドエンコーダを設計して速度を向上させます。次に、不確定性最小化クエリ選択を提案して、高品質の初期クエリをデコーダに提供し、精度を向上させます。さらに、RT-DETRは、デコーダ層の数を調整することで柔軟に速度を調整でき、再トレーニングなしで様々なシナリオに適応できます。私たちのRT-DETR-R50 / R101は、COCOで53.1% / 54.3%のAPを達成し、T4 GPUで108 / 74 FPSを達成し、速度と精度の両方で以前の高度なYOLOを上回っています。また、スケーリングされたRT-DETRも開発し、より軽量なYOLO検出器(SおよびMモデル)を上回っています。さらに、RT-DETR-R50は、精度でDINO-R50を2.2%上回り、FPSで約21倍上回っています。Objects365で事前学習した後、RT-DETR-R50 / R101は55.3% / 56.2%のAPを達成します。プロジェクトページはこちらhttps URL。
モデルの情報
| 属性 |
详情 |
| モデルタイプ |
RT-DETR |
| 開発者 |
Yian ZhaoとSangbum Choi |
| 資金提供元 |
中国国家重点研究開発計画(No.2022ZD0118201)、中国自然科学基金(No.61972217, 32071459, 62176249, 62006133, 62271465)、および中国深セン医療研究基金(No.B2302037) |
| 共有者 |
Sangbum Choi |
| ライセンス |
Apache-2.0 |
モデルのソース
- HF Docs: RT-DETR
- リポジトリ: https://github.com/lyuwenyu/RT-DETR
- 論文: https://arxiv.org/abs/2304.08069
- デモ: RT-DETR Tracking
トレーニング詳細
トレーニングデータ
RTDETRモデルは、COCO 2017物体検出データセットでトレーニングされました。このデータセットは、トレーニング用に118k、検証用に5kの注釈付き画像で構成されています。
トレーニング手順
COCOとObjects365データセットで実験を行い、RT-DETRはCOCO train2017でトレーニングされ、COCO val2017データセットで検証されます。標準的なCOCOメトリクスを報告します。これには、AP(IoU閾値0.50-0.95の範囲で均一にサンプリングされた平均AP)、AP50、AP75、および異なるスケールでのAP(APS、APM、APL)が含まれます。
前処理
画像は640x640ピクセルにリサイズされ、image_mean=[0.485, 0.456, 0.406]とimage_std=[0.229, 0.224, 0.225]で再スケーリングされます。
トレーニングハイパーパラメータ
- トレーニング方式:

評価
| モデル |
エポック数 |
パラメータ数 (M) |
GFLOPs |
FPS_bs=1 |
AP (val) |
AP50 (val) |
AP75 (val) |
AP-s (val) |
AP-m (val) |
AP-l (val) |
| RT-DETR-R18 |
72 |
20 |
60.7 |
217 |
46.5 |
63.8 |
50.4 |
28.4 |
49.8 |
63.0 |
| RT-DETR-R34 |
72 |
31 |
91.0 |
172 |
48.5 |
66.2 |
52.3 |
30.2 |
51.9 |
66.2 |
| RT-DETR R50 |
72 |
42 |
136 |
108 |
53.1 |
71.3 |
57.7 |
34.8 |
58.0 |
70.0 |
| RT-DETR R101 |
72 |
76 |
259 |
74 |
54.3 |
72.7 |
58.6 |
36.0 |
58.8 |
72.1 |
| RT-DETR-R18 (Objects 365 pretrained) |
60 |
20 |
61 |
217 |
49.2 |
66.6 |
53.5 |
33.2 |
52.3 |
64.8 |
| RT-DETR-R50 (Objects 365 pretrained) |
24 |
42 |
136 |
108 |
55.3 |
73.4 |
60.1 |
37.9 |
59.9 |
71.8 |
| RT-DETR-R101 (Objects 365 pretrained) |
24 |
76 |
259 |
74 |
56.2 |
74.6 |
61.3 |
38.3 |
60.5 |
73.5 |
モデルアーキテクチャと目的
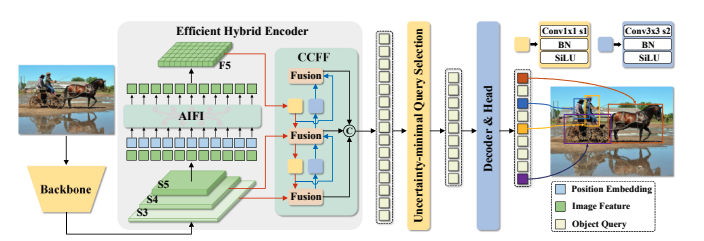
RT-DETRの概要です。バックボーンの最後の3つのステージからの特徴をエンコーダに入力します。効率的なハイブリッドエンコーダは、Attentionベースのスケール内特徴相互作用(AIFI)とCNNベースのクロススケール特徴融合(CCFF)によって、マルチスケール特徴を画像特徴のシーケンスに変換します。次に、不確定性最小化クエリ選択が、エンコーダ特徴の固定数を選択して、デコーダの初期物体クエリとして使用します。最後に、補助予測ヘッドを持つデコーダが、物体クエリを反復的に最適化して、カテゴリとボックスを生成します。
引用
BibTeX:
@misc{lv2023detrs,
title={DETRs Beat YOLOs on Real-time Object Detection},
author={Yian Zhao and Wenyu Lv and Shangliang Xu and Jinman Wei and Guanzhong Wang and Qingqing Dang and Yi Liu and Jie Chen},
year={2023},
eprint={2304.08069},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
モデルカード作成者
Sangbum Choi
Pavel Iakubovskii
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応