🚀 SigLIP (ベースサイズのモデル)
SigLIPは、解像度256x256のWebLiで事前学習されたモデルです。このモデルは、Zhaiらによる論文 Sigmoid Loss for Language Image Pre-Training で紹介され、このリポジトリ で最初に公開されました。
なお、SigLIPを公開したチームはこのモデルのモデルカードを作成していないため、このモデルカードはHugging Faceチームによって作成されています。
🚀 クイックスタート
このセクションでは、SigLIPモデルの概要、用途、使い方、トレーニング手順、評価結果などについて説明します。
✨ 主な機能
- SigLIPは、CLIP というマルチモーダルモデルの損失関数を改良したものです。シグモイド損失は画像 - テキストペアにのみ作用し、正規化のためにペアワイズ類似度のグローバルビューを必要としません。これにより、バッチサイズをさらに拡大できると同時に、小さいバッチサイズでも良好な性能を発揮します。
- 著者の一人によるSigLIPの概要は こちら で確認できます。
📦 インストール
このモデルを使用するには、transformers ライブラリが必要です。以下のコマンドでインストールできます。
pip install transformers
💻 使用例
基本的な使用法
このモデルを使用してゼロショット画像分類を行う方法は次の通りです。
from PIL import Image
import requests
from transformers import AutoProcessor, AutoModel
import torch
model = AutoModel.from_pretrained("google/siglip-base-patch16-256")
processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-256")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = ["a photo of 2 cats", "a photo of 2 dogs"]
inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image
probs = torch.sigmoid(logits_per_image)
print(f"{probs[0][0]:.1%} that image 0 is '{texts[0]}'")
高度な使用法
パイプラインAPIを使用することで、ユーザーにとっての複雑さを軽減できます。
from transformers import pipeline
from PIL import Image
import requests
image_classifier = pipeline(task="zero-shot-image-classification", model="google/siglip-base-patch16-224")
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
outputs = image_classifier(image, candidate_labels=["2 cats", "a plane", "a remote"])
outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
print(outputs)
より多くのコード例については、ドキュメント を参照してください。
📚 ドキュメント
想定される用途と制限
このモデルは、ゼロショット画像分類や画像 - テキスト検索などのタスクに使用できます。他のバージョンや関心のあるタスクについては、モデルハブ を参照してください。
トレーニング手順
トレーニングデータ
SigLIPは、WebLIデータセット (Chen et al., 2023) の英語の画像 - テキストペアで事前学習されています。
前処理
画像は同じ解像度 (256x256) にリサイズ/リスケールされ、RGBチャンネル全体で平均 (0.5, 0.5, 0.5) および標準偏差 (0.5, 0.5, 0.5) で正規化されます。
テキストはトークン化され、同じ長さ (64トークン) にパディングされます。
コンピューティング資源
このモデルは、16個のTPU - v4チップで3日間トレーニングされました。
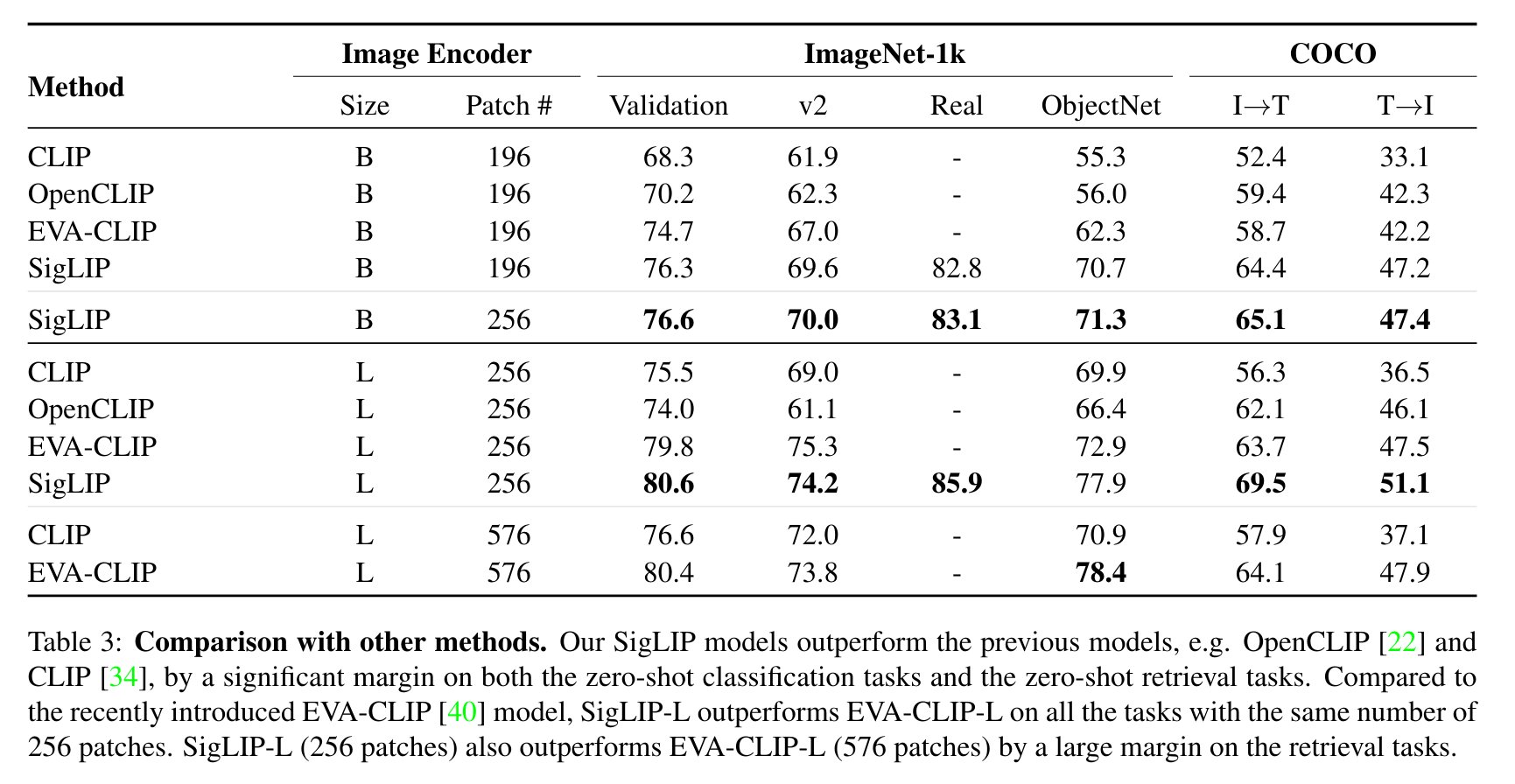
評価結果
CLIPと比較したSigLIPの評価結果を以下に示します(論文から引用)。
BibTeXエントリと引用情報
@misc{zhai2023sigmoid,
title={Sigmoid Loss for Language Image Pre-Training},
author={Xiaohua Zhai and Basil Mustafa and Alexander Kolesnikov and Lucas Beyer},
year={2023},
eprint={2303.15343},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
📄 ライセンス
このモデルはApache-2.0ライセンスの下で提供されています。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 複数言語対応
Transformers 複数言語対応