🚀 SigLIP (base-sized model)
A pre - trained SigLIP model on WebLi at 256x256 resolution, introduced in a paper by Zhai et al., offering better performance in multimodal tasks.
🚀 Quick Start
SigLIP is a multimodal model, similar to CLIP, but with a better loss function. The sigmoid loss only operates on image - text pairs, enabling further scaling up of the batch size and better performance at smaller batch sizes.
✨ Features
- Better Loss Function: The sigmoid loss in SigLIP allows for more efficient training and better performance.
- Multimodal Capabilities: Suitable for tasks like zero - shot image classification and image - text retrieval.
📦 Installation
No specific installation steps are provided in the original README. However, to use the model, you need to install the transformers library:
pip install transformers
💻 Usage Examples
Basic Usage
Here is how to use this model to perform zero - shot image classification:
from PIL import Image
import requests
from transformers import AutoProcessor, AutoModel
import torch
model = AutoModel.from_pretrained("google/siglip-base-patch16-256")
processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-256")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = ["a photo of 2 cats", "a photo of 2 dogs"]
inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image
probs = torch.sigmoid(logits_per_image)
print(f"{probs[0][0]:.1%} that image 0 is '{texts[0]}'")
Advanced Usage
Alternatively, one can leverage the pipeline API which abstracts away the complexity for the user:
from transformers import pipeline
from PIL import Image
import requests
image_classifier = pipeline(task="zero-shot-image-classification", model="google/siglip-base-patch16-224")
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
outputs = image_classifier(image, candidate_labels=["2 cats", "a plane", "a remote"])
outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
print(outputs)
For more code examples, we refer to the documentation.
📚 Documentation
Intended uses & limitations
You can use the raw model for tasks like zero - shot image classification and image - text retrieval. See the model hub to look for other versions on a task that interests you.
Training procedure
Training data
SigLIP is pre - trained on the English image - text pairs of the WebLI dataset (Chen et al., 2023).
Preprocessing
- Images are resized/rescaled to the same resolution (256x256) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
- Texts are tokenized and padded to the same length (64 tokens).
Compute
The model was trained on 16 TPU - v4 chips for three days.
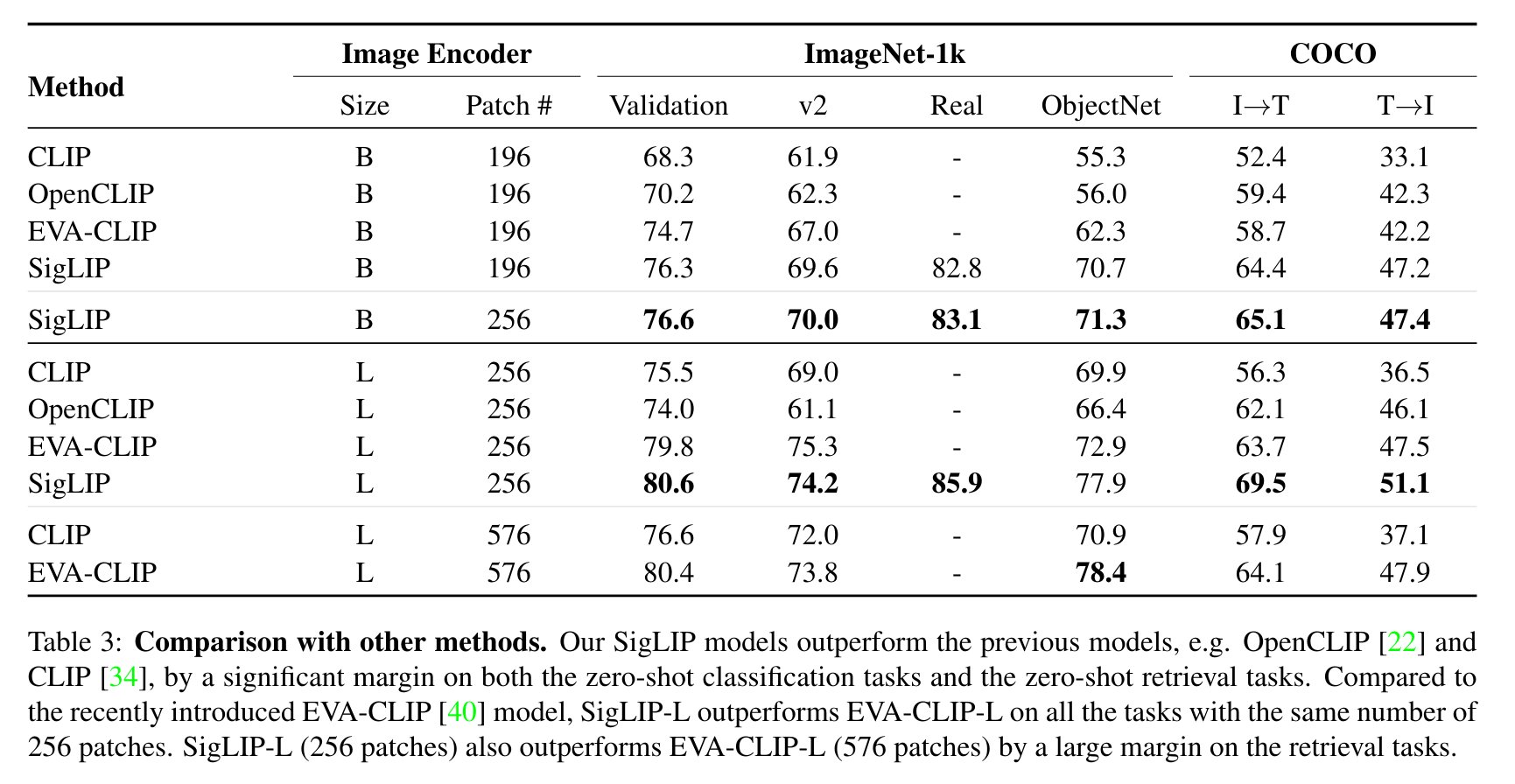
Evaluation results
Evaluation of SigLIP compared to CLIP is shown below (taken from the paper).
BibTeX entry and citation info
@misc{zhai2023sigmoid,
title={Sigmoid Loss for Language Image Pre-Training},
author={Xiaohua Zhai and Basil Mustafa and Alexander Kolesnikov and Lucas Beyer},
year={2023},
eprint={2303.15343},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
📄 License
This model is released under the Apache 2.0 license.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors