🚀 AnimateDiff-Lightning
AnimateDiff-Lightningは、超高速なテキストから動画を生成するモデルです。元のAnimateDiffよりも10倍以上高速に動画を生成することができます。詳細については、当社の研究論文AnimateDiff-Lightning: Cross-Model Diffusion Distillationを参照してください。本モデルは研究の一環として公開されています。
🚀 クイックスタート
AnimateDiff-Lightningは、スタイル化されたベースモデルと組み合わせて使用すると、最良の結果を得ることができます。以下のベースモデルの使用をおすすめします。
リアリスティック
アニメ&カートゥーン
また、さまざまな設定を自由に試してみることをおすすめします。2ステップモデルで3回の推論ステップを使用すると、素晴らしい結果が得られることがわかっています。特定のベースモデルでは、CFGを使用するとより良い結果が得られます。また、Motion LoRAsを使用すると、より強力なモーションが得られるため、おすすめです。ウォーターマークを避けるために、強度0.7~0.8のMotion LoRAsを使用しています。
✨ 主な機能
- 超高速なテキストから動画への生成
- 元のAnimateDiffよりも10倍以上高速な動画生成
- 1ステップ、2ステップ、4ステップ、8ステップの蒸留モデルのチェックポイントを提供
- 動画から動画への生成にも優れた性能を発揮
📦 インストール
このセクションでは、DiffusersとComfyUIを使用したAnimateDiff-Lightningのインストール方法を説明します。
Diffusersを使用したインストール
import torch
from diffusers import AnimateDiffPipeline, MotionAdapter, EulerDiscreteScheduler
from diffusers.utils import export_to_gif
from huggingface_hub import hf_hub_download
from safetensors.torch import load_file
device = "cuda"
dtype = torch.float16
step = 4
repo = "ByteDance/AnimateDiff-Lightning"
ckpt = f"animatediff_lightning_{step}step_diffusers.safetensors"
base = "emilianJR/epiCRealism"
adapter = MotionAdapter().to(device, dtype)
adapter.load_state_dict(load_file(hf_hub_download(repo ,ckpt), device=device))
pipe = AnimateDiffPipeline.from_pretrained(base, motion_adapter=adapter, torch_dtype=dtype).to(device)
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config, timestep_spacing="trailing", beta_schedule="linear")
output = pipe(prompt="A girl smiling", guidance_scale=1.0, num_inference_steps=step)
export_to_gif(output.frames[0], "animation.gif")
ComfyUIを使用したインストール
- animatediff_lightning_workflow.jsonをダウンロードし、ComfyUIにインポートします。
- ノードをインストールします。手動でインストールすることも、ComfyUI-Managerを使用することもできます。
- 好きなベースモデルのチェックポイントをダウンロードし、
/models/checkpoints/に配置します。
- AnimateDiff-Lightningのチェックポイント
animatediff_lightning_Nstep_comfyui.safetensorsをダウンロードし、/custom_nodes/ComfyUI-AnimateDiff-Evolved/models/に配置します。
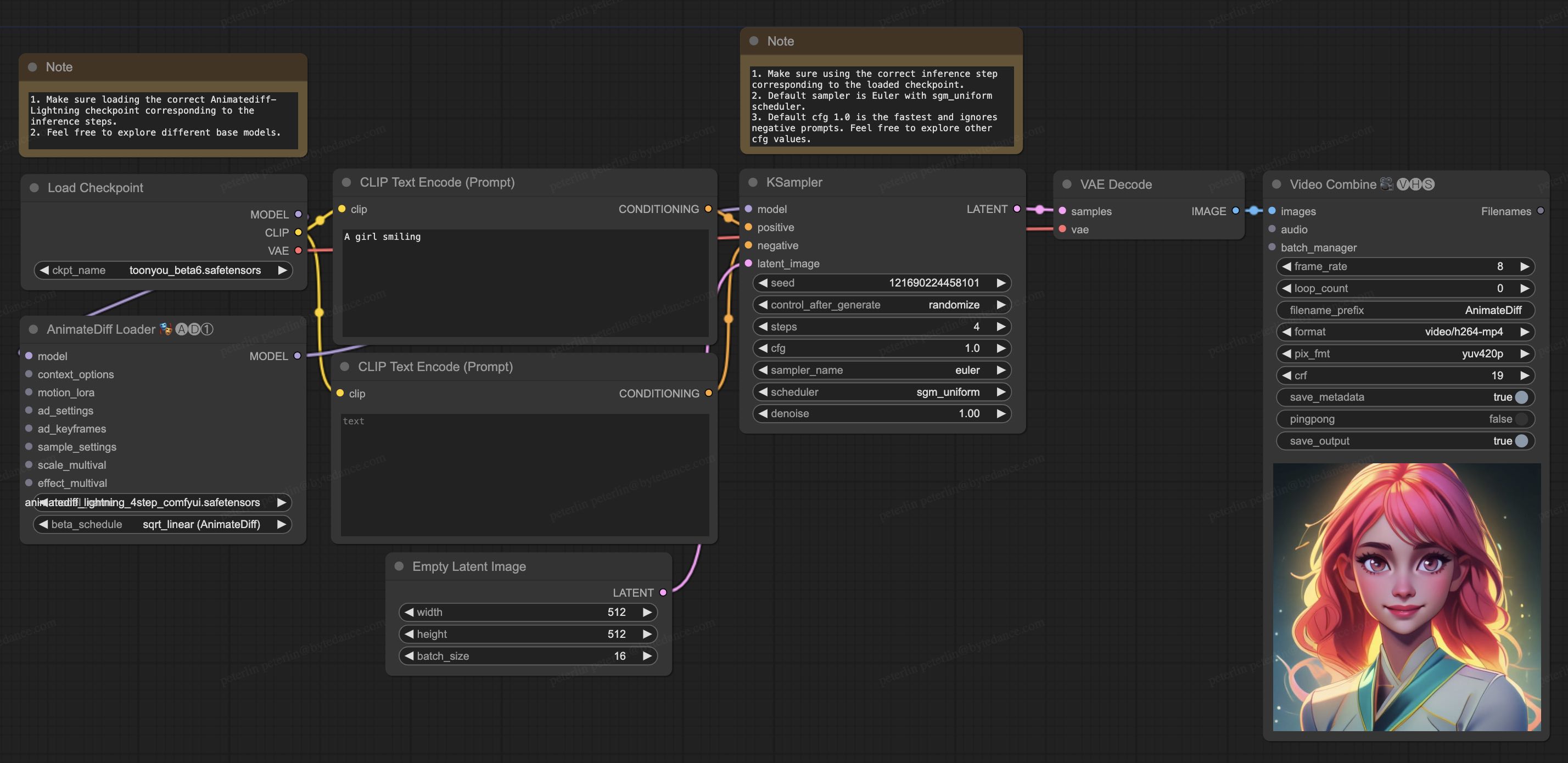
💻 使用例
テキストから動画への生成
上記のDiffusersのコード例を参照してください。
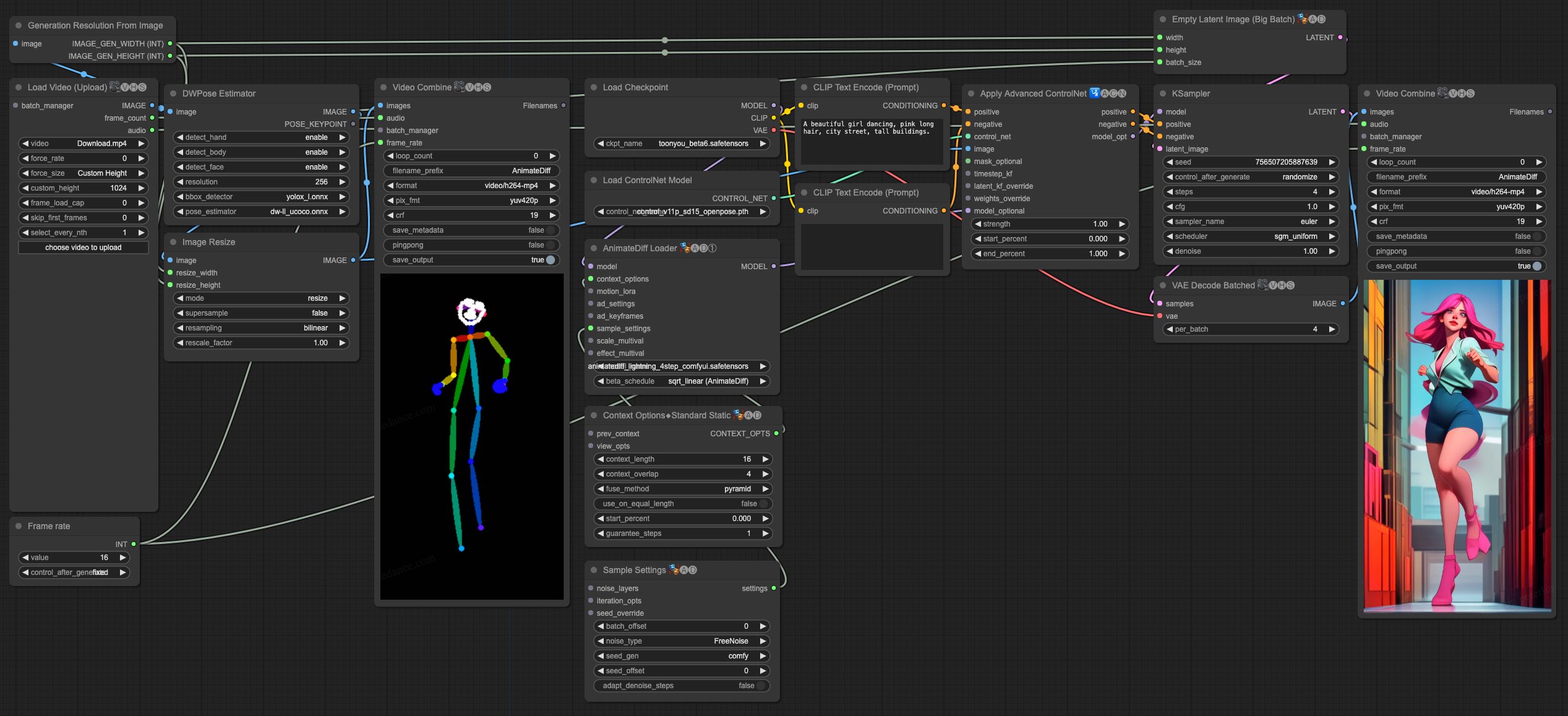
動画から動画への生成
AnimateDiff-Lightningは、動画から動画への生成にも優れた性能を発揮します。ControlNetを使用した最もシンプルなComfyUIワークフローを提供しています。
- animatediff_lightning_v2v_openpose_workflow.jsonをダウンロードし、ComfyUIにインポートします。
- ノードをインストールします。手動でインストールすることも、ComfyUI-Managerを使用することもできます。
- 好きなベースモデルのチェックポイントをダウンロードし、
/models/checkpoints/に配置します。
- AnimateDiff-Lightningのチェックポイント
animatediff_lightning_Nstep_comfyui.safetensorsをダウンロードし、/custom_nodes/ComfyUI-AnimateDiff-Evolved/models/に配置します。
- ControlNet OpenPoseの
control_v11p_sd15_openpose.pthチェックポイントを/models/controlnet/にダウンロードします。
- 動画をアップロードし、パイプラインを実行します。
追加注意事項
- 動画はあまり長く、または解像度が高すぎないようにしてください。テストには、576x1024、8秒、30fpsの動画を使用しています。
- フレームレートを入力動画に合わせて設定してください。これにより、オーディオが出力動画と一致します。
- DWPoseは初回実行時に自動的にチェックポイントをダウンロードします。
- DWPoseはUIで停止することがありますが、実際にはパイプラインはバックグラウンドで実行されています。ComfyUIのログと出力フォルダを確認してください。
📄 ライセンス
このモデルは、CreativeML OpenRAIL-Mライセンスの下で公開されています。
📚 ドキュメント
詳細については、当社の研究論文AnimateDiff-Lightning: Cross-Model Diffusion Distillationを参照してください。
📖 引用
@misc{lin2024animatedifflightning,
title={AnimateDiff-Lightning: Cross-Model Diffusion Distillation},
author={Shanchuan Lin and Xiao Yang},
year={2024},
eprint={2403.12706},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
💡 使用アドバイス
- スタイル化されたベースモデルを使用すると、より良い結果が得られます。
- 2ステップモデルで3回の推論ステップを使用すると、素晴らしい結果が得られます。
- 特定のベースモデルでは、CFGを使用するとより良い結果が得られます。
- Motion LoRAsを使用すると、より強力なモーションが得られます。
- ウォーターマークを避けるために、強度0.7~0.8のMotion LoRAsを使用してください。
⚠️ 重要な注意事項
- 動画はあまり長く、または解像度が高すぎないようにしてください。
- フレームレートを入力動画に合わせて設定してください。
- DWPoseは初回実行時に自動的にチェックポイントをダウンロードします。
- DWPoseはUIで停止することがありますが、実際にはパイプラインはバックグラウンドで実行されています。ComfyUIのログと出力フォルダを確認してください。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応