🚀 EMOVA-Qwen-2.5-7B-HF
EMOVA(EMotionally Omni-present Voice Assistant)は、外部モデルに依存せずに、見る、聞く、話すことができる革新的なエンドツーエンドのオムニモーダル大規模言語モデル(LLM)です。オムニモーダル(テキスト、ビジュアル、音声)の入力を受け取ると、EMOVAは音声デコーダーとスタイルエンコーダーを利用して、生き生きとした感情制御を伴うテキストと音声の両方の応答を生成することができます。EMOVAは、一般的なオムニモーダル理解と生成能力を備えており、高度なビジョン言語理解、感情豊かな音声対話、構造化データ理解を伴う音声対話において優れた性能を発揮します。主な利点を以下にまとめます。
✨ 主な機能
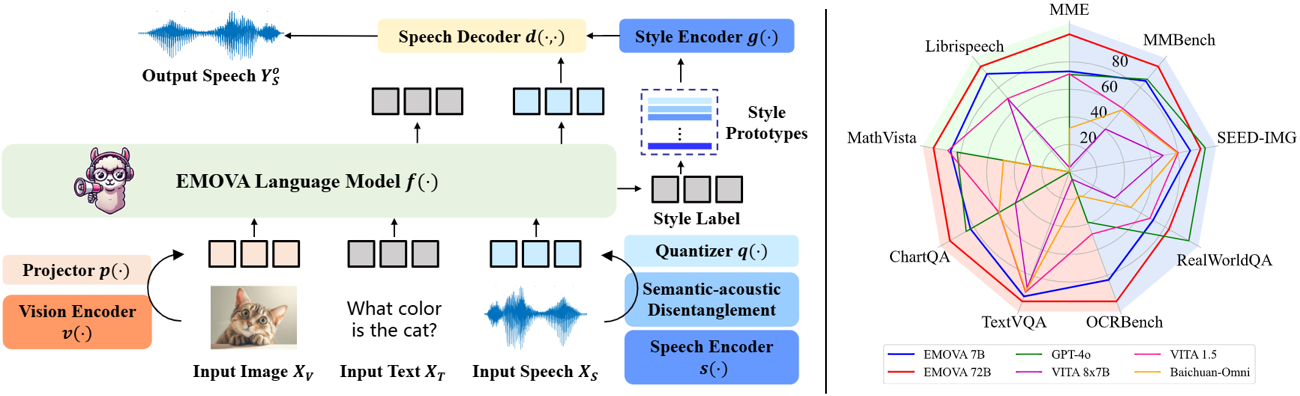
- 最先端のオムニモーダル性能:EMOVAは、ビジョン言語と音声の両方のベンチマークで同時に最先端の結果を達成しています。最も性能の高いモデルであるEMOVA-72Bは、GPT-4oやGemini Pro 1.5などの商用モデルを上回っています。
- 感情豊かな音声対話:意味論的・音響的分離型の音声トークナイザーと軽量なスタイル制御モジュールを採用して、シームレスなオムニモーダルアライメントと多様な音声スタイル制御を実現しています。EMOVAは、24種類の音声スタイル制御(2人の話者、3種類のピッチ、4種類の感情) を備えた両言語(中国語と英語) の音声対話をサポートしています。
- 多様な構成:3種類の構成(EMOVA-3B/7B/72B)をオープンソースで公開して、さまざまな計算リソースに対応したオムニモーダルな使用をサポートしています。モデルズーをチェックして、あなたの計算デバイスに最適なモデルを見つけてください!
📦 インストール
このREADMEには具体的なインストール手順が記載されていないため、このセクションをスキップします。
💻 使用例
基本的な使用法
from transformers import AutoModel, AutoProcessor
from PIL import Image
import torch
model = AutoModel.from_pretrained(
"Emova-ollm/emova-qwen-2-5-7b-hf",
torch_dtype=torch.bfloat16,
attn_implementation='flash_attention_2',
low_cpu_mem_usage=True,
trust_remote_code=True).eval().cuda()
processor = AutoProcessor.from_pretrained("Emova-ollm/emova-qwen-2-5-7b-hf", trust_remote_code=True)
speeck_tokenizer = AutoModel.from_pretrained("Emova-ollm/emova_speech_tokenizer_hf", torch_dtype=torch.float32, trust_remote_code=True).eval().cuda()
processor.set_speech_tokenizer(speeck_tokenizer)
inputs = dict(
text=[
{"role": "system", "content": [{"type": "text", "text": "You are a helpful assistant."}]},
{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": "What's shown in this image?"}]},
{"role": "assistant", "content": [{"type": "text", "text": "This image shows a red stop sign."}]},
{"role": "user", "content": [{"type": "text", "text": "Describe the image in more details."}]},
],
images=Image.open('path/to/image')
)
inputs = dict(
text=[{"role": "system", "content": [{"type": "text", "text": "You are a helpful assistant."}]}],
audios='path/to/audio'
)
inputs = dict(
text=[{"role": "system", "content": [{"type": "text", "text": "You are a helpful assistant."}]}],
images=Image.open('path/to/image'),
audios='path/to/audio'
)
has_speech = 'audios' in inputs.keys()
inputs = processor(**inputs, return_tensors="pt")
inputs = inputs.to(model.device)
gen_kwargs = {"max_new_tokens": 4096, "do_sample": False}
speech_kwargs = {"speaker": "female", "output_wav_prefix": "output"} if has_speech else {}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(processor.batch_decode(outputs, skip_special_tokens=True, **speech_kwargs))
📚 ドキュメント
モデル情報
| 属性 |
详情 |
| モデルタイプ |
EMOVA-Qwen-2.5-7B-HFは、オムニモーダル大規模言語モデルで、画像、音声、テキストの入力に対応し、多様なタスクを実行できます。 |
| 学習データ |
Emova-ollm/emova-alignment-7m、Emova-ollm/emova-sft-4m、Emova-ollm/emova-sft-speech-231k |
パフォーマンス
| ベンチマーク |
EMOVA-3B |
EMOVA-7B |
EMOVA-72B |
GPT-4o |
VITA 8x7B |
VITA 1.5 |
Baichuan-Omni |
| MME |
2175 |
2317 |
2402 |
2310 |
2097 |
2311 |
2187 |
| MMBench |
79.2 |
83.0 |
86.4 |
83.4 |
71.8 |
76.6 |
76.2 |
| SEED-Image |
74.9 |
75.5 |
76.6 |
77.1 |
72.6 |
74.2 |
74.1 |
| MM-Vet |
57.3 |
59.4 |
64.8 |
- |
41.6 |
51.1 |
65.4 |
| RealWorldQA |
62.6 |
67.5 |
71.0 |
75.4 |
59.0 |
66.8 |
62.6 |
| TextVQA |
77.2 |
78.0 |
81.4 |
- |
71.8 |
74.9 |
74.3 |
| ChartQA |
81.5 |
84.9 |
88.7 |
85.7 |
76.6 |
79.6 |
79.6 |
| DocVQA |
93.5 |
94.2 |
95.9 |
92.8 |
- |
- |
- |
| InfoVQA |
71.2 |
75.1 |
83.2 |
- |
- |
- |
- |
| OCRBench |
803 |
814 |
843 |
736 |
678 |
752 |
700 |
| ScienceQA-Img |
92.7 |
96.4 |
98.2 |
- |
- |
- |
- |
| AI2D |
78.6 |
81.7 |
85.8 |
84.6 |
73.1 |
79.3 |
- |
| MathVista |
62.6 |
65.5 |
69.9 |
63.8 |
44.9 |
66.2 |
51.9 |
| Mathverse |
31.4 |
40.9 |
50.0 |
- |
- |
- |
- |
| Librispeech (WER↓) |
5.4 |
4.1 |
2.9 |
- |
3.4 |
8.1 |
- |
🔧 技術詳細
このREADMEには具体的な技術詳細が記載されていないため、このセクションをスキップします。
📄 ライセンス
このモデルは、Apache 2.0ライセンスの下で公開されています。
引用
@article{chen2024emova,
title={Emova: Empowering language models to see, hear and speak with vivid emotions},
author={Chen, Kai and Gou, Yunhao and Huang, Runhui and Liu, Zhili and Tan, Daxin and Xu, Jing and Wang, Chunwei and Zhu, Yi and Zeng, Yihan and Yang, Kuo and others},
journal={arXiv preprint arXiv:2409.18042},
year={2024}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 複数言語対応
Transformers 複数言語対応