🚀 ~ GenZ ~
GenZは、オープンソースコミュニティにおける大規模言語モデル(LLM)へのアクセスを民主化することを目指したプロジェクトです。我々は、オープンソースの協力によって、AI技術の進歩を加速させることができると信じています。
🚀 クイックスタート
Hugging FaceでGenZモデルを使用するには、以下の手順に従ってください。
1️⃣ 必要なモジュールをインポートする
まず、transformersライブラリとtorchから必要なモジュールをインポートします。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("budecosystem/genz-70b", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("budecosystem/genz-70b", torch_dtype=torch.bfloat16, rope_scaling={"type": "dynamic", "factor": 2})
prompt = "### User:\nWrite a python flask code for login management\n\n### Assistant:\n"
inputs = tokenizer(prompt, return_tensors="pt")
sample = model.generate(**inputs, max_length=128)
print(tokenizer.decode(sample[0]))
もっと直感的にモデルと対話したい場合は、GitHubページに移動してリポジトリをクローンし、generate.pyスクリプトを実行して試してみてください。
✨ 主な機能
- 高度なテキスト生成:GenZは、MetaのオープンソースLlama V2 70Bパラメータモデルをベースに微調整された大規模言語モデルです。高度なテキスト生成能力を持ち、ユーザーのプロンプトに対して高品質な応答を提供します。
- 多様なパラメータと量子化:我々は、異なるパラメータ数(7B、13B、70B)と量子化(32ビットと4ビット)の一連のモデルをオープンソースコミュニティに公開する予定です。小さな量子化バージョンのモデルは、個人用コンピュータでも使用できるようになっています。
- 継続的な改善:我々は、GenZを継続的に改善することにコミットしています。定期的に様々なデータセットでモデルを微調整し、性能を向上させます。
📦 インストール
Hugging FaceでGenZモデルを使用するには、上記のクイックスタートセクションの手順に従ってください。
💻 使用例
基本的な使用法
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("budecosystem/genz-70b", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("budecosystem/genz-70b", torch_dtype=torch.bfloat16, rope_scaling={"type": "dynamic", "factor": 2})
prompt = "### User:\nWrite a python flask code for login management\n\n### Assistant:\n"
inputs = tokenizer(prompt, return_tensors="pt")
sample = model.generate(**inputs, max_length=128)
print(tokenizer.decode(sample[0]))
📚 ドキュメント
マイルストーンリリース ️🏁
評価 🎯
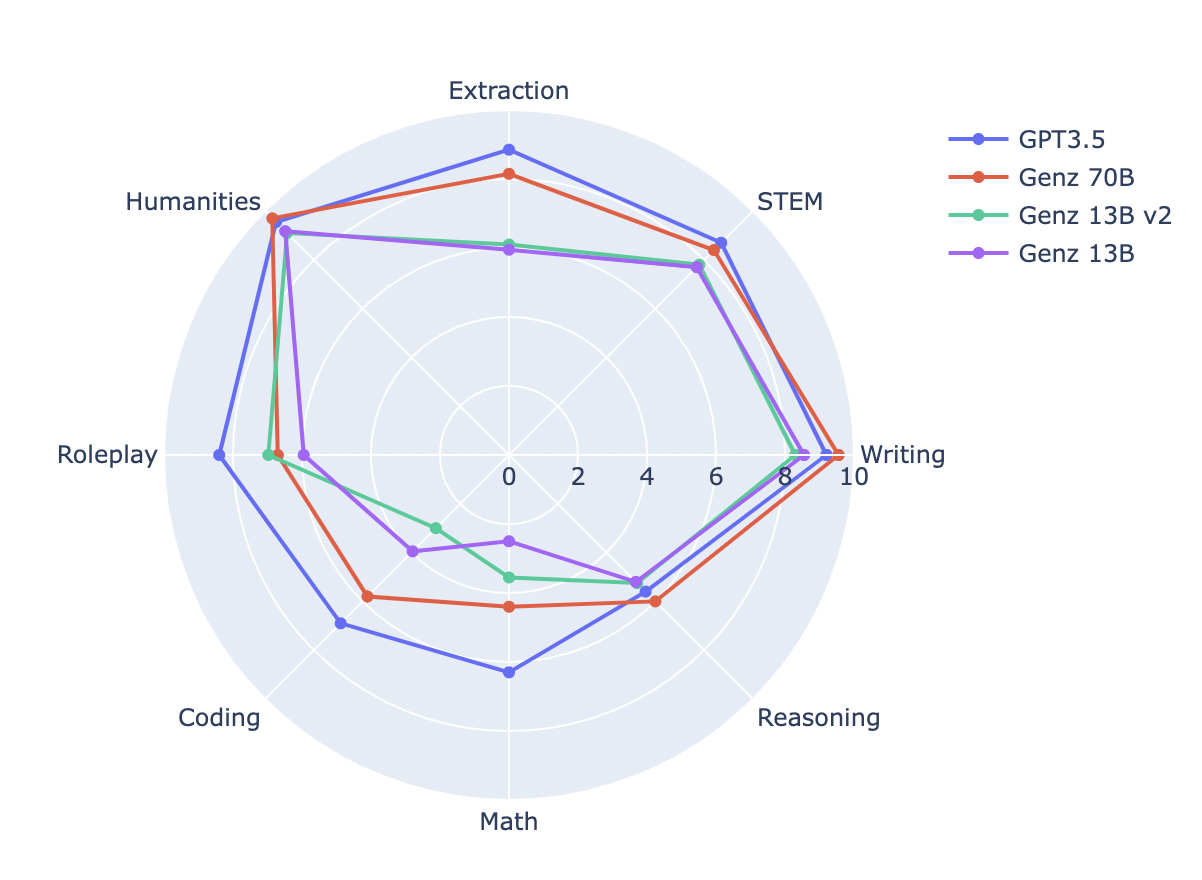
ベンチマーク比較
GenZモデルを比較し、微調整によって達成された改善を確認しました。
| モデル名 |
MT Bench |
MMLU |
Human Eval |
BBH |
| Genz 13B |
6.12 |
53.62 |
17.68 |
37.76 |
| Genz 13B v2 |
6.79 |
53.68 |
21.95 |
38.1 |
| Genz 70B |
7.33 |
70.32 |
37.8 |
54.69 |
MT Benchスコア
MT Benchスコアは、モデルの性能を包括的に評価するための重要な指標です。
GenZ 70Bのモデルカード 📄
モデルの詳細
- 開発者:Bud Ecosystem
- ベースの事前学習モデルタイプ:Llama V2 70B
- モデルアーキテクチャ:GenZ 70Bは、Llama V2 70Bをベースに微調整された自己回帰型言語モデルで、最適化されたトランスフォーマーアーキテクチャを採用しています。微調整には、教師付き微調整(SFT)を使用しています。
- ライセンス:このモデルは、カスタム商用ライセンスの下で商用利用可能です。詳細については、Meta AI Model and Library Downloads をご覧ください。
意図された使用法 💼
直接的な使用
GenZ 70Bは、大規模言語モデルの研究に強力なツールとして設計されています。また、特定のユースケースに合わせてさらに特化および微調整するための優れた基盤となります。
- テキスト要約
- テキスト生成
- チャットボット作成
- など
範囲外の使用 🚩
GenZ 70Bは多用途ですが、以下のような使用は範囲外です。
- リスクの十分な評価と軽減策なしでの本番環境での使用
- 無責任または有害と見なされる可能性のある使用ケース
- 適用される法律や規制、貿易コンプライアンス法に違反する使用
- Llama 2の許容使用ポリシーとライセンス契約で禁止されている他の使用方法
推奨事項 🧠
GenZ 70Bのユーザーは、関心のある特定のタスクセットに合わせてモデルを微調整することをお勧めします。本番環境での使用には、適切な予防策とガードレールを講じる必要があります。
トレーニングの詳細 📚
微調整トレーニングデータ
微調整には、OpenAssistantの命令微調整データセットやThought SourceのChain Of Thought(CoT)アプローチなど、さまざまなデータセットを使用しました。これらの多様なデータソースは、モデルの様々なタスクでの能力を向上させるのに役立ちました。
ハイパーパラメータ
微調整に使用したハイパーパラメータは以下の通りです。
| ハイパーパラメータ |
値 |
| ウォームアップ比率 |
0.04 |
| 学習率スケジューラタイプ |
コサイン |
| 学習率 |
2e-5 |
| トレーニングエポック数 |
3 |
| デバイスあたりのトレーニングバッチサイズ |
4 |
| 勾配累積ステップ |
4 |
| 精度 |
FP16 |
| オプティマイザ |
AdamW |
🔧 技術詳細
GenZ 70Bは、Llama V2 70Bをベースに微調整された自己回帰型言語モデルです。微調整には、教師付き微調整(SFT)を使用し、多様なデータセットを用いてモデルの能力を向上させました。
📄 ライセンス
このモデルは、カスタム商用ライセンスの下で商用利用可能です。詳細については、Meta AI Model and Library Downloads をご覧ください。
👀 これからの展望
我々は、GenZのこれからの旅程に興奮しています。モデルを継続的に改善し、オープンソースコミュニティが何を構築するかを楽しみにしています。我々は協力の力を信じており、一緒に何が達成できるかを楽しみにしています。
コードについては、GitHubを確認してください -> GenZ
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応