🚀 Sonya-7B
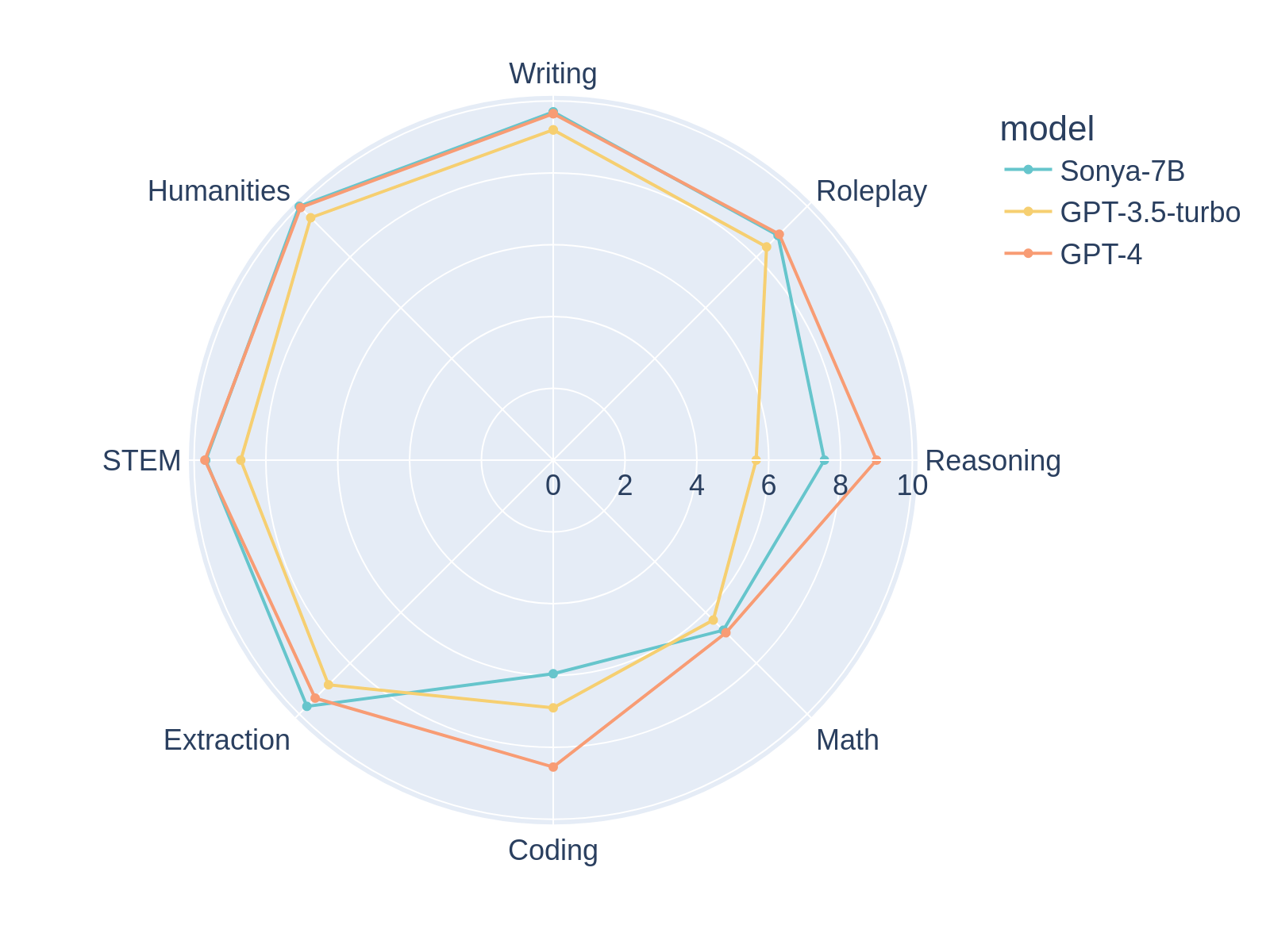
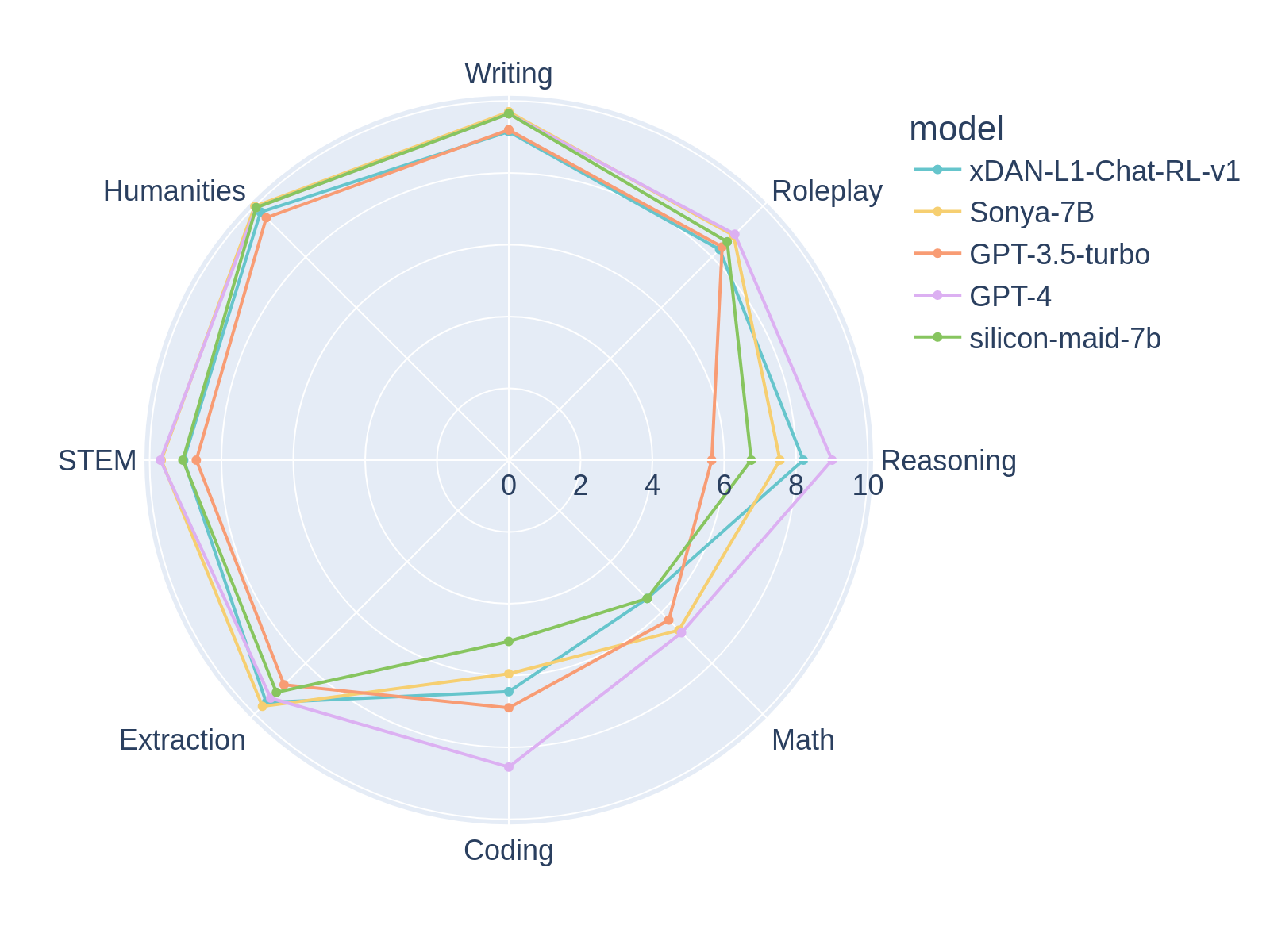
Sonya-7Bは、執筆時点でMT-Benchの初回ターンで1位、GPT-4を上回り、MT-Bench全体では2位を獲得したモデルです。アシスタントやロールプレイなど、あらゆるタスクに適した汎用モデルです。
🚀 クイックスタート
Sonya-7Bは、以前のモデルであるSilicon-Maid-7Bと同様の構造を持ち、非常に似たマージ方法を用いています。このモデルは、xDAN-AI/xDAN-L1-Chat-RL-v1、Jan-Ai's Stealth v1.2、chargoddard/piano-medley-7b、NeverSleep/Noromaid-7B-v0.2、そしてathirdpath/NSFW_DPO_vmgb-7bをマージしたものです。マージの詳細は以下に示します。これらのモデルを組み合わせることで、MT-Benchで親モデルを大幅に上回るスコアを獲得しています。
これらのモデルを選んだ理由は以下の通りです。
- MT-Benchのスコアは実世界でのモデル品質とよく相関しており、xDANはこのベンチマークで良好な成績を収めています。
- マージに使用したほとんどのモデルはAlpacaプロンプト形式を採用しており、プロンプトの一貫性が保たれています。
- Stealth v1.2は、MT-Benchのスコアを向上させる魔法の要素のようです。
- ロールプレイモデルを追加することで、文章作成とロールプレイのベンチマークが向上しました。
親モデルに基づき、このモデルは8192のコンテキストウィンドウで使用することを想定しています。16384のコンテキストを実験的に試す場合は、NTKスケーリングアルファを2.6に設定してください。
率直に言うと、このモデルはテストスコアにもかかわらず、GPTを凌駕するものではありません。7Bモデルとしては非常に優れたモデルで、おそらく7Bモデルとしては大きな威力を発揮しますが、やはり7Bモデルです。たとえ7Bモデルであっても、癖があり、奇妙な出力をすることがあります。これはおそらくマージ方法が複雑であるためです。期待値を適切に設定してください。
✨ 主な機能
MT-Bench平均ターン
| モデル |
スコア |
サイズ |
| gpt-4 |
8.99 |
- |
| Sonya-7B |
8.52 |
7b |
| xDAN-L1-Chat-RL-v1 |
8.34 |
7b |
| Starling-7B |
8.09 |
7b |
| Claude-2 |
8.06 |
- |
| Silicon-Maid |
7.96 |
7b |
| Loyal-Macaroni-Maid |
7.95 |
7b |
| gpt-3.5-turbo |
7.94 |
20b? |
| Claude-1 |
7.90 |
- |
| OpenChat-3.5 |
7.81 |
- |
| vicuna-33b-v1.3 |
7.12 |
33b |
| wizardlm-30b |
7.01 |
30b |
| Llama-2-70b-chat |
6.86 |
70b |
🔧 技術詳細
マージの詳細
models:
- model: xDAN-AI/xDAN-L1-Chat-RL-v1
parameters:
weight: 1
density: 1
- model: chargoddard/piano-medley-7b
parameters:
weight: 0.3
- model: jan-hq/stealth-v1.2
parameters:
weight: 0.2
- model: NeverSleep/Noromaid-7b-v0.2
parameters:
weight: 0.2
- model: athirdpath/NSFW_DPO_vmgb-7b
parameters:
weight: 0.2
merge_method: ties
base_model: mistralai/Mistral-7B-v0.1
parameters:
density: 0.4
int8_mask: true
normalize: true
dtype: bfloat16
追加のトレーニング、ファインチューニング、またはDPOは行われていません。これは単純なマージです。
プロンプトテンプレート (Alpaca)
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
このモデルはxDANプロンプト形式では性能が低下することがわかりました。したがって、このマージにおけるxDANの重みが大きいにもかかわらず、使用を避けることをお勧めします。
その他のベンチマーク情報
########## 初回ターン ##########
| モデル |
ターン |
スコア |
サイズ |
| Sonya-7B |
1 |
9.06875 |
7b |
| gpt-4 |
1 |
8.95625 |
- |
| xDAN-L1-Chat-RL-v1 |
1 |
8.87500 |
7b |
| xDAN-L2-Chat-RL-v2 |
1 |
8.78750 |
30b |
| claude-v1 |
1 |
8.15000 |
- |
| gpt-3.5-turbo |
1 |
8.07500 |
20b |
| vicuna-33b-v1.3 |
1 |
7.45625 |
33b |
| wizardlm-30b |
1 |
7.13125 |
30b |
| oasst-sft-7-llama-30b |
1 |
7.10625 |
30b |
| Llama-2-70b-chat |
1 |
6.98750 |
70b |
########## 2回目のターン ##########
| モデル |
ターン |
スコア |
サイズ |
| gpt-4 |
2 |
9.025000 |
- |
| xDAN-L2-Chat-RL-v2 |
2 |
8.087500 |
30b |
| Sonya-7B |
2 |
7.962500 |
7b |
| xDAN-L1-Chat-RL-v1 |
2 |
7.825000 |
7b |
| gpt-3.5-turbo |
2 |
7.812500 |
20b |
| claude-v1 |
2 |
7.650000 |
- |
| wizardlm-30b |
2 |
6.887500 |
30b |
| vicuna-33b-v1.3 |
2 |
6.787500 |
33b |
| Llama-2-70b-chat |
2 |
6.725000 |
70b |
MT-Benchの実行を再現する場合は、Alpacaプロンプトテンプレートをモデルに適用することを確認してください。私はモデルパスに「alpaca」を入力することでAlpacaAdapterをトリガーしました。
📄 ライセンス
このモデルはCC BY 4.0ライセンスの下で提供されています。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

 Transformers 複数言語対応
Transformers 複数言語対応