🚀 Minerva-1B-base-v1.0 のモデルカード
Minervaは、Sapienza NLPがFuture Artificial Intelligence Research (FAIR) および CINECA と共同で開発した、イタリア語で最初から事前学習された大規模言語モデル(LLM)のファミリーです。特に、Minervaモデルは真にオープン(データとモデル)なイタリア語 - 英語のLLMで、事前学習データの約半分にイタリア語のテキストが含まれています。
🚀 クイックスタート
Minerva-1B-base-v1.0は、イタリア語と英語の両方で事前学習された大規模言語モデルです。以下に、Hugging Faceのtransformersライブラリを使用してこのモデルを使う方法を示します。
import transformers
import torch
model_id = "sapienzanlp/Minerva-1B-base-v1.0"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
input_text = "La capitale dell'Italia è"
output = pipeline(
input_text,
max_new_tokens=128,
)
✨ 主な機能
- Minervaは、イタリア語で最初から事前学習されたLLMファミリーで、イタリア語と英語の両方のデータで訓練されています。
- このモデルは、Transformerベースのアーキテクチャを持ち、Mistralアーキテクチャに基づいています。
- Minervaファミリーには、異なるパラメータ数のモデルが含まれており、それぞれ異なるタスクに適しています。
📚 ドキュメント
説明
これは Minerva-1B-base-v1.0 のモデルカードです。このモデルは、2000億トークン(イタリア語1000億トークン、英語1000億トークン)で訓練された10億パラメータのモデルです。
このモデルはMinerva LLMファミリーの一部です。
🚨⚠️🚨 バイアス、リスク、制限事項 🚨⚠️🚨
このセクションでは、予見可能な害や誤解を特定します。
これはファウンデーションモデルであり、アライメントが行われていません。モデルは以下のような問題を引き起こす可能性があります。
- 一部の見解を過剰に表現し、他の見解を過小に表現することがあります。
- ステレオタイプを含むことがあります。
- 個人情報を含むことがあります。
- 以下のような内容を生成することがあります。
- 憎悪的、虐待的、または暴力的な言語
- 差別的または偏見的な言語
- すべての設定に適さない内容(性的な内容を含む)
- 誤りを犯すことがあり、誤った情報を事実のように生成することがあります。
- 関連性のないまたは繰り返しの出力を生成することがあります。
現在の事前学習された大規模言語モデルが示すバイアスについては認識しています。具体的には、(イタリア語と英語の)言語の確率モデルとして、これらのモデルは訓練データのバイアスを反映し、増幅する傾向があります。
この問題に関する詳細情報については、以下の調査を参照してください。
モデルアーキテクチャ
Minerva-1B-base-v1.0は、Mistralアーキテクチャに基づくTransformerモデルです。層の数、ヘッドの数、および隠れ状態の次元は、10億パラメータに達するように調整されています。
このモデルに選択したハイパーパラメータの詳細な内訳については、設定ファイルを参照してください。
Minerva LLMファミリーは以下のように構成されています。
| モデル名 |
トークン数 |
層数 |
隠れサイズ |
アテンションヘッド数 |
KVヘッド数 |
スライディングウィンドウ |
最大コンテキスト長 |
| Minerva-350M-base-v1.0 |
700億 (350億イタリア語 + 350億英語) |
16 |
1152 |
16 |
4 |
2048 |
16384 |
| Minerva-1B-base-v1.0 |
2000億 (1000億イタリア語 + 1000億英語) |
16 |
2048 |
16 |
4 |
2048 |
16384 |
| Minerva-3B-base-v1.0 |
6600億 (3300億イタリア語 + 3300億英語) |
32 |
2560 |
32 |
8 |
2048 |
16384 |
モデル訓練
Minerva-1B-base-v1.0は、MosaicMLのllm-foundry 0.6.0を使用して訓練されました。使用されたハイパーパラメータは以下の通りです。
| モデル名 |
オプティマイザ |
学習率 |
ベータ |
イプシロン |
重み減衰 |
スケジューラ |
ウォームアップステップ |
バッチサイズ (トークン) |
総ステップ数 |
| Minerva-350M-base-v1.0 |
Decoupled AdamW |
2e-4 |
(0.9, 0.95) |
1e-8 |
0.0 |
Cosine |
2% |
400万 |
16,690 |
| Minerva-1B-base-v1.0 |
Decoupled AdamW |
2e-4 |
(0.9, 0.95) |
1e-8 |
0.0 |
Cosine |
2% |
400万 |
47,684 |
| Minerva-3B-base-v1.0 |
Decoupled AdamW |
2e-4 |
(0.9, 0.95) |
1e-8 |
0.0 |
Cosine |
2% |
400万 |
157,357 |
モデル評価
LM-Evaluation-Harnessライブラリを使用してモデルを評価しました。このライブラリは、幅広い評価タスクにわたって生成型言語モデルをテストするための包括的なフレームワークです。
報告されたすべてのベンチマークデータは、LM-Evaluation-Harnessスイートにすでに含まれていました。
イタリア語データ
英語データ
訓練データ
Minerva-1B-base-v1.0は、CulturaXからサンプリングされた1000億イタリア語トークンと1000億英語トークンで訓練されました。
データは以下のソースから選択されました。
- OSCAR-2201
- OSCAR-2301
- mC4
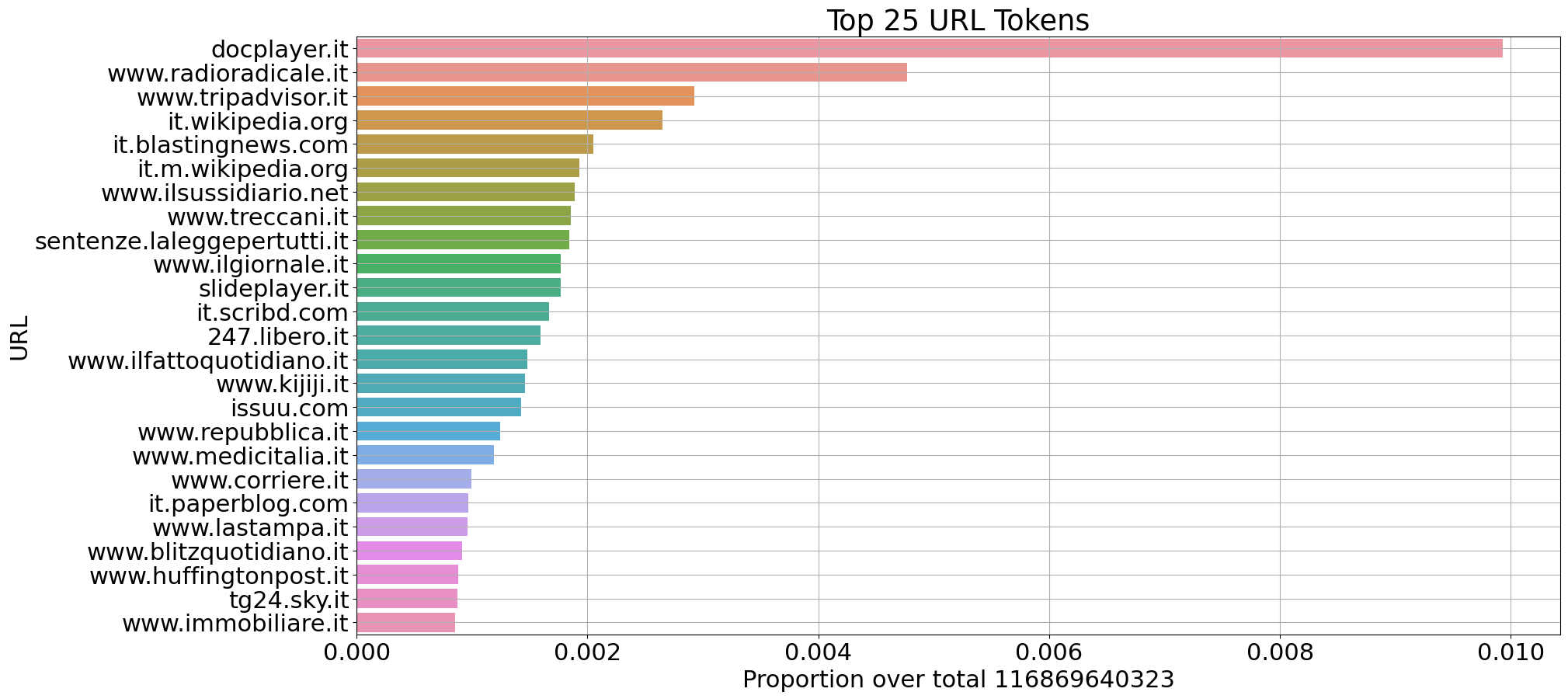
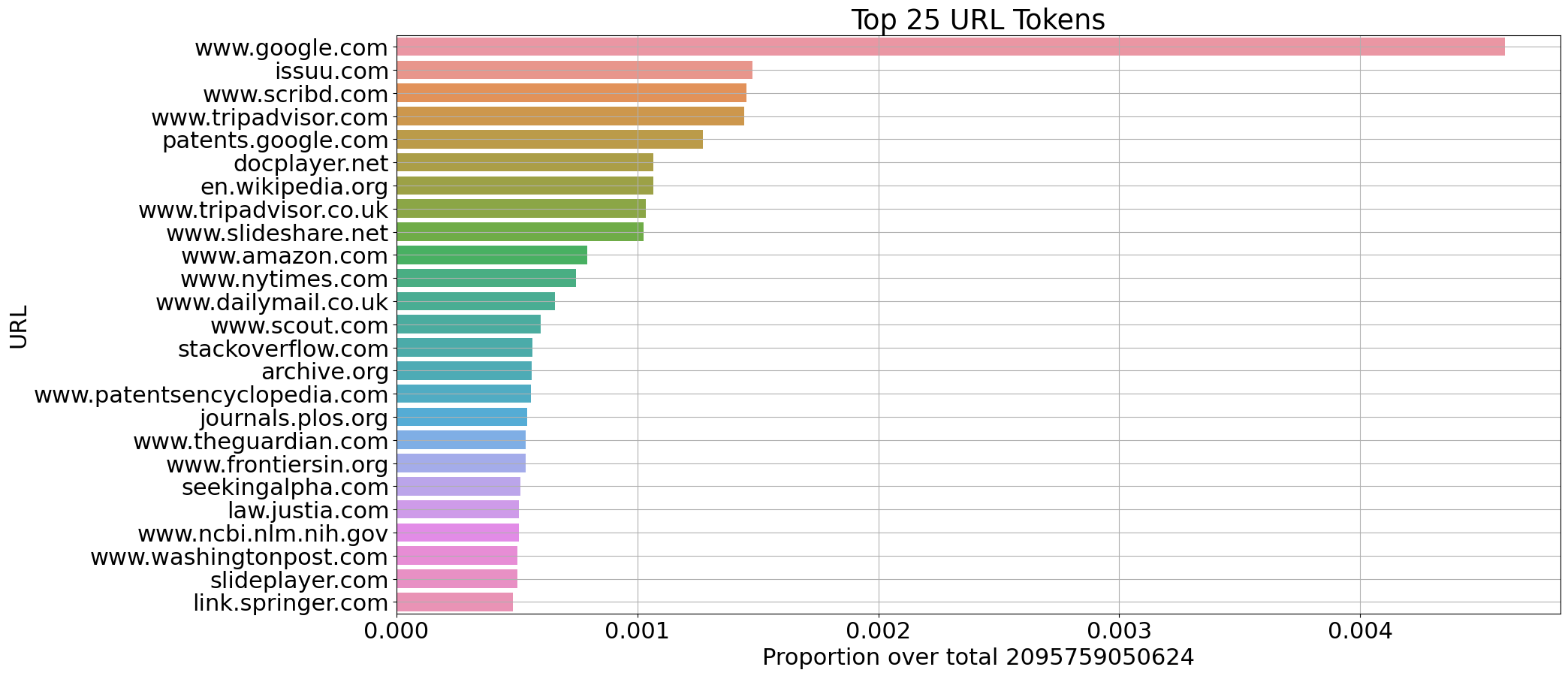
選択されたソースについて、CulturaXからイタリア語(1150億トークン)と英語(2100億トークン)のドキュメントに関するいくつかの統計情報を抽出しました。
ドメインごとのトークン数の割合(イタリア語)
ドメインごとのトークン数の割合(英語)
トークナイザの生産性
トークナイザの生産性は、トークン化された単語ごとに生成されるトークンの平均量を測定します。
特定の言語で高い生産性値を示すトークナイザは、通常、その言語の単語を広範に分割することを示しています。
トークナイザの生産性は、特定の言語に関するモデルの推論速度と厳密に相関しています。生産性値が高いほど、生成するトークンのシーケンスが長くなり、推論速度が低下します。
Cultura X (CX) データとWikipedia (Wp) のサンプルに対して計算された生産性
| モデル |
語彙サイズ |
生産性 IT (CX) |
生産性 EN (CX) |
生産性 IT (Wp) |
生産性 EN (Wp) |
| Mistral-7B-v0.1 |
32000 |
1.87 |
1.32 |
2.05 |
1.57 |
| gemma-7b |
256000 |
1.42 |
1.18 |
1.56 |
1.34 |
| Minerva-1B-base-v1.0 |
32768 |
1.39 |
1.32 |
1.66 |
1.59 |
注意事項
Minerva-350M-base-v1.0は事前学習されたベースモデルであり、モデレーションメカニズムがありません。
Sapienza NLPチーム
- Riccardo Orlando: データ前処理、モデル訓練
- Pere-Lluis Huguet Cabot: データ前処理、語彙、評価
- Luca Moroni: データ選別、データ分析、下流タスク、評価
- Simone Conia: データ選別、評価、プロジェクト監督
- Edoardo Barba: データ前処理、下流タスク、プロジェクト監督
- Roberto Navigli: プロジェクトリードと調整
支援に感謝します
- Giuseppe Fiameni, Nvidia
- Sergio Orlandini, CINECA
謝辞
この研究は、PNRR MURプロジェクト PE0000013-FAIRによって資金提供されています。
高性能コンピューティングリソースとサポートの提供について、CINECAの "IscB_medit" 賞に感謝します。
📄 ライセンス
このモデルは、Apache-2.0ライセンスの下で提供されています。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応